
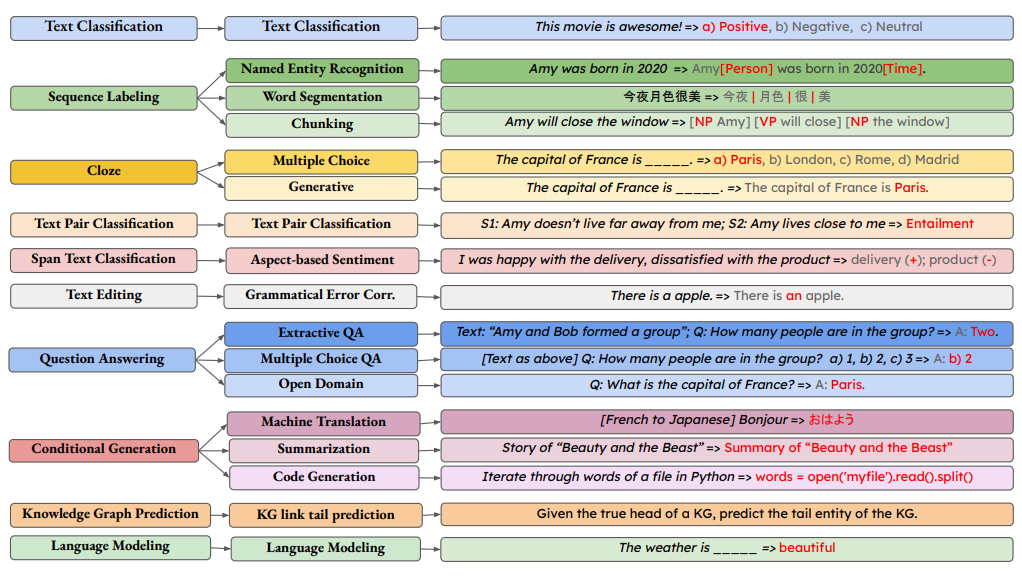
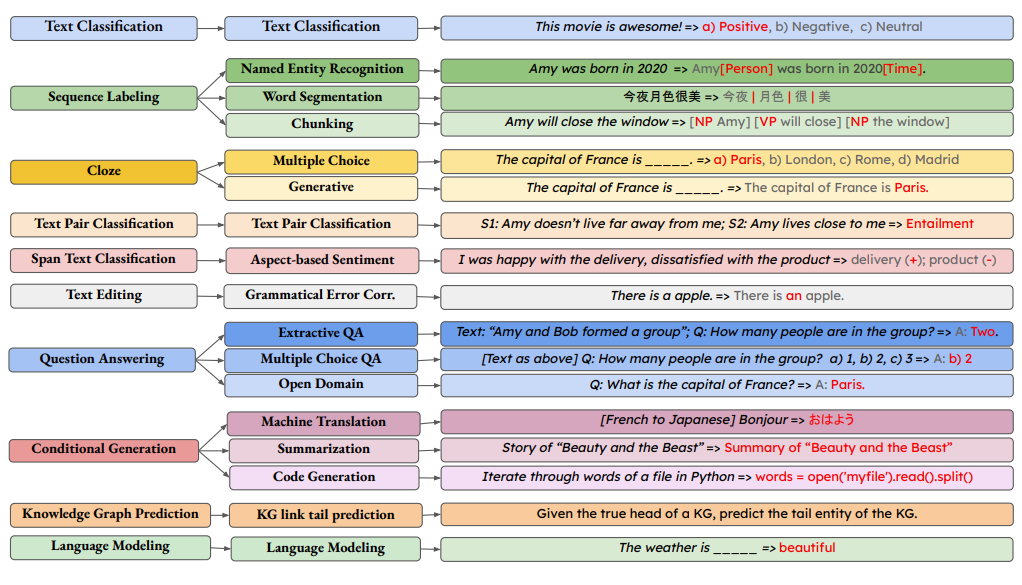
A primer on NLP benchmarks
Ever wondered how your favourite LLM was evaluated? How is the battle between Deepseek vs openAI vs Gemini is measured/conducted? This article will cover the evaluation benchmarks in great detail.


Table of content
Introduction
Components of a benchmark
Criterion for dataset
Criterion for metrics
Important metrics
BLEU
ROUGE
Perplexity
CIDEr
METEOR
BERTScore
Burstiness
Dataset for evaluation
Classification Benchmarks
Reasoning benchmarks
Generation benchmarks
Retrieval benchmarks
Extra/Miscellaneous benchmarks (coding+modern benchmarks)
Multi-lingual benchmarks
Indic-language benchmarks
Thoughts / Potential issues with benchmarking
Conclusion
Introduction
Due to exponential growth in quality of research in domain of LLMS everyday we hear about one large language model beating other ones. But, how are we even quantifying which model is better? Is there a measure to identify performance and quality? And if yes, then how is it done? and more importantly what exactly serves as the methodology for evaluation?
Simple yet not so straightforward answer to this are evaluation Benchmarks.
Benchmark serve as milestones or north-star for any objective/algorithm, which in our case are SLMs (small language models) and LLMs (Large Language models), as said "if you cannot measure it, you cannot improve it" by Peter drucker, the benchmark serve as building block of innovation and research.

Hence, importance of Benchmarks are many fold:
Helps in evaluations : evaluation benchmarks serve as a metric for understanding models potential across multiple downstream tasks like classification, generation, etc.
Comparability : As the evaluations are standardized set, hence, they offer a common ground to compare multiple algorithms/models.
Generalization check : One of the most important thing that is expected out of a well trained model is generalization, it might be possible that during training given the biasness over a certain type of objective or data, model might perform really well with a some benchmarks but fail in others, hence, multiple benchmarks ensure only a general purpose yet resourceful model is utilized. Though, specific models are really important, but, even there testing on multiple types of specific use-cases is important.
Serve as bridge between algorithm and use-case (virtual vs real-world) : finally, the benchmarks could be defined in such a way that they strongly align with a certain use-case, for example, code quality check, a model trained on huge corpus of code/scripts is expected to also understand the finer details of good naming conventions, etc. which is eventually tested out by the benchmarks, once the model passes the test, it could be vehemently believed to be good enough to use for the downstream task.
Components of a benchmark
Now we understand importance of Benchmarks, let's investigate the definition itself. Each evaluation Benchmark consists of two distinct part:
Data : This serves as the input to your model, basically the samples on which your model predicts/generates an output. They are defined keeping multiple aspects about quality, alignment and modality/structure in mind. For example we have images for image datasets (vision tasks) and strings in NLP.
Metric : Once the model predicts the outputs, the most important question arises is how do we say that the output is good or not / usable or not? This term is defined through metrics which serves as qualitative representation of our expectations and models quality.
You can also think of datapoints as space itself, imagine a landscape full of mountains and valleys, each point here is our data points. The scale/method we move or measure distance between one point and other is our metric.
Hence, both our space and metric system has to be well defined and need to satisfy some mathematical conditions to have an understandable meaning.
Criterion for data
Good amount of variance in samples : This is subjective as the definition of variance is qualitative in nature, but, in general the data should contain as less bias as possible while covering sufficient amount of samples for testing the model.
Representative of use-cases and tasks : The data should contain crafted samples to accommodate multiple tasks, for example in language translation, a good quality, checked and verified data samples should be part of benchmark, if not, then in itself it would limit the quality of our tests and eventually the understanding of the quality of model itself.
Criterion for metrics
It has to follow triangular inequality (in terms of logits/probabilistic measure, Jensen inequality compatibility is required).
A convex metric is much easier to understand and interpret, you can read more about convexity here.
Ideally the metrics should be computationally feasible, which simply says that it has to run in certain polynomial time.
The conditions now known, let's dive deeper in various available metrics, for sake of simplicity and quality of information, we will focus more on specific/important metrics first specially for language and language dependent reasoning tasks. Then we will also discuss about each data benchmark in detail. (We wont discuss about simpler metrics such as precision, recall, F1-score, etc. as there really good and visual explanation out there.)
Important metrics
1. BLEU (Bilingual Evaluation Understudy)
What is it?
BLEU measures n-gram overlap between generated text and reference text/ground truth.
It was actually designed specifically for machine translation, but now even used in summarization, paraphrasing, and text generation tasks as well.
How is BLEU score calculated?
Compute n-gram precision:
Compare how many unigrams, bigrams, trigrams, etc. from the generated text appear in the reference text.
Apply a brevity penalty to prevent very short outputs from getting high scores.
Final BLEU score is the geometric mean of n-gram precisions.
Formula:
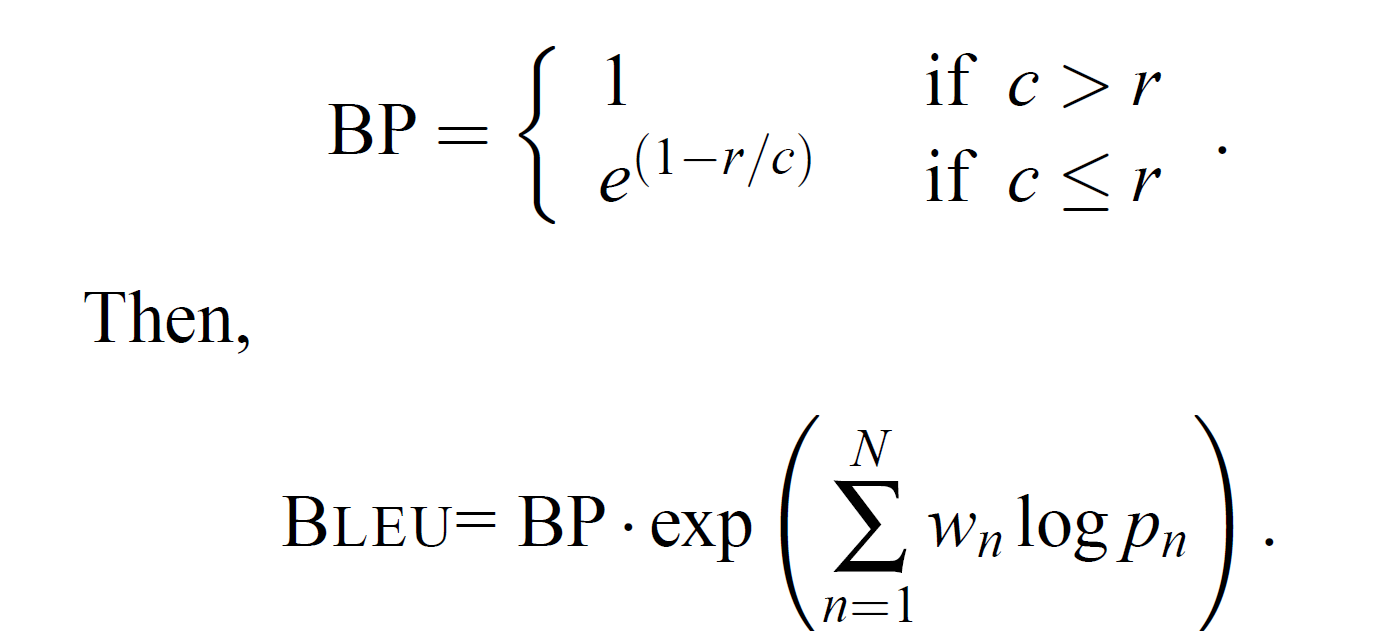
Where:
BPis the brevity penaltyp_n is the precision for n-gramsw_nis the weight assigned to each n-gram level (default is equal weighting)
Advantages:
Fast and easy to compute
Works well for machine translation
Disadvantages:
Ignores semantic meaning (only matches words)
Favors exact matches, so synonyms and paraphrases are penalized
2. ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
What is it?
ROUGE evaluates how well a generated summary matches a human-written reference summary.
Used mainly for summarization and paraphrasing.
Types of ROUGE scores:
ROUGE-N: Measures n-gram overlap between generated and reference text (e.g., ROUGE-1 for unigrams, ROUGE-2 for bigrams).
ROUGE-L: Uses longest common subsequence (LCS) to measure fluency and order of words.
ROUGE-W: Weighted LCS to reward longer matches.
ROUGE-S: Measures skip-bigram overlap (words that appear together but may have gaps).
How is ROUGE score calculated?
Precision: % of words in generated text that appear in the reference text.
Recall: % of words in reference text that appear in the generated text.
F1-score: Harmonic mean of precision and recall.

where,
R_lcs, P_lcs, F_lcs is average recall, precision and F1 score.
Advantages:
Handles synonyms and paraphrases better than BLEU
Can be used for longer texts
Disadvantages:
Still relies on word overlap, ignoring deeper semantics
Struggles with abstractive summaries
3. Perplexity (PPL)
What is it?
Perplexity measures how well a language model predicts a sequence of words.
Used to evaluate language models (GPT, BERT, LLMs).
How is perplexity calculated?
Perplexity is the inverse probability of the test set, normalized by the number of words.
Where:
Nis the number of wordsP(w_i)is the probability assigned by the model to word wi.
Advantages:
Measures fluency of generated text
Helps tune language models
Disadvantages:
Lower perplexity isn't equivalent to better text quality (a model can be very confident but wrong)
Does not evaluate semantic correctness
4. CIDEr (Consensus-Based Image Description Evaluation)
What is it?
CIDEr evaluates caption generation models (image-to-text tasks).
Measures n-gram overlap but weights words based on their importance using TF-IDF.
How is CIDEr score calculated?
Compute n-gram overlap between the generated caption and multiple reference captions.
Apply TF-IDF weighting to emphasize important words.
Aggregate using cosine similarity.
Formula:
Advantages:
Handles multiple reference texts better
Rewards important words
Disadvantages:
Requires multiple reference captions
May still favor word overlap over meaning
5. METEOR (Metric for Evaluation of Translation with Explicit ORdering)
What is it?
METEOR improves on BLEU by considering synonyms, stemming, and paraphrasing.
Developed for machine translation, also used for summarization and paraphrasing.
How is METEOR score calculated?
Compute unigram precision and recall.
Apply synonym and paraphrase matching.
Apply penalties for word order changes, The METEOR penalty is computed based on fragmentation, which measures how scattered matched words are across chunks.
More discontinuous chunks lead to a greater penalty, reducing the final METEOR score to favor fluent, contiguous phrase matches over disordered word matches
Compute final F1-score with higher recall weighting.
Formula:
Advantages:
Captures synonyms, stemming, and word order
More human-correlated than BLEU
Disadvantages:
Slower to compute than BLEU
Requires WordNet or paraphrase databases
6. BERTScore
What is it?
BERTScore measures semantic similarity using BERT embeddings.
Unlike BLEU or ROUGE, it doesn’t rely on word overlap.
How is BERTScore calculated?
Convert generated and reference text into BERT embeddings.
Compute cosine similarity between token embeddings.
Aggregate scores across all tokens.
Advantages:
Captures semantic meaning
Works well for abstractive generation
Disadvantages:
Requires pretrained BERT models
Slower than BLEU/ROUGE
7. Burstiness
What is it?
It measures/quantifies how natural a certain text sequence is.
It leverages the fact that a more natural text sequence has dense information at certain place, hence there are hot regions of information and lots of surrounding content, whereas generated content has more-or-less uniformly placed information content.
Larger burstiness means high probability of human-like/written content.
How is Burstiness calculated?
Computation is very similar to TF-IDF, here, we compute the ratio of the standard deviation of token frequency and the mean frequency of token.
Assume a low std text, which means the information is almost uniform, which leads to small B score, hence symbolizing machine generated content.
Aggregate scores across all tokens.
Advantages:
Really important for identification of generated vs natural content.
Agnostic to downstream tasks and models.
Disadvantages:
Strong assumption over word distribution and its interpretation as qualitative measure.
Almost no assumption over semantic/contextual understanding.
Datasets for evaluations
Now we understand multiple metrics generally used for evaluations, lets quickly go through different benchmark datasets. Here, we will divide the section into smaller sub-domains like generation, translation, reasoning, etc. Though there exists significant overlap between categories, but I have tried to closely follow paperswithcode method of categorization.
1. Classification Benchmarks
Benchmarks that evaluate a model's ability to classify text into predefined categories, which could be related to language understanding or classification (sentiment, captions, etc.).
1.1 GLUE (General Language Understanding Evaluation)
A suite of nine diverse classification tasks containing around 1.5million samples. QQP and MNLI are the most represented ones with around 400k+ samples each, various datasets include:
SST-2 (Stanford Sentiment Treebank) – Binary sentiment classification.
MRPC (Microsoft Research Paraphrase Corpus) – Paraphrase detection.
QQP (Quora Question Pairs) – Determines if two questions are duplicates.
MNLI (Multi-Genre Natural Language Inference) – Classifies premise-hypothesis relationships.
QNLI (Question Natural Language Inference) – Determines if a sentence answers a given question.
RTE (Recognizing Textual Entailment) – Binary classification for entailment.
STS-B (Semantic Textual Similarity Benchmark) – Measures sentence similarity.
CoLA (Corpus of Linguistic Acceptability) – Evaluates grammatical acceptability.
WNLI (Winograd NLI) – Pronoun resolution for sentence comprehension.
Metric: Accuracy, Matthews Correlation Coefficient (CoLA), Pearson/Spearman Correlation (STS-B), F1 score (MRPC, QQP).
1.2 SuperGLUE
A more challenging version of GLUE with harder reasoning tasks. It contains roughly 135,000 datapoints across all tasks, with ReCoRD being the most dominant sample-set (around 100k). It includes:
BoolQ – Binary classification of whether a passage answers a yes/no question.
CB (CommitmentBank) – Classifies whether a sentence expresses belief in a proposition.
COPA (Choice of Plausible Alternatives) – Evaluates causal reasoning.
MultiRC – Multi-sentence reading comprehension with multiple correct answers.
ReCoRD – Extracts named entities from passages to answer cloze-style questions.
RTE – Same as GLUE but included due to difficulty.
WiC (Word-in-Context) – Word sense disambiguation task.
WSC (Winograd Schema Challenge) – Requires resolving ambiguous pronouns.
Metric: Accuracy, F1 score, Matthews Correlation, Exact Match (for extractive tasks).
1.3 Sentiment Analysis (IMDB, Yelp, Amazon Reviews)
IMDB Reviews: Binary sentiment classification of movie reviews. 50,000 movie reviews (25,000 for training and 25,000 for testing).
Yelp/Amazon Reviews: Sentiment classification of product and business reviews. Both Amazon and Yelp have around 5 million samples.
Metric: Accuracy, F1-score.
1.4 AG News / DBPedia
AG News: Classifies news articles into 4 categories. It contains 120,000 training samples and 7,600 test samples, categorized into 4 classes.
DBPedia: Classifies Wikipedia articles into 14 categories. It consists of 560,000 training samples and 70,000 test samples across 14 categories.
Metric: Accuracy.
1.5 Toxicity & Bias Detection (Jigsaw, BBQ)
Jigsaw Toxicity Dataset: Detects hate speech and offensive language. The Jigsaw Toxicity dataset contains 2 million comments (not all toxic), used for classifying comments as toxic or not toxic.
BBQ (Bias Benchmark for QA): Evaluates fairness in NLP models.
Metric: AUC, F1-score.
2. Reasoning benchmarks
The generic benchmarks are significantly easier to crack by the modern day LLMs, but they don’t represent basic building block of intelligence like logic understanding, pattern finding, problem solving, etc. Hence, we need set of benchmarks to understand and evaluate ability of model to reason and comprehend complex problems.
2.1 MMLU (Massive Multitask Language Understanding)
Description: MMLU is a comprehensive benchmark designed to evaluate a model's multitask accuracy across a diverse range of 57 subjects, including humanities, sciences, and mathematics. It assesses both world knowledge and problem-solving abilities.
It covers topics from elementary mathematics to advanced professional subjects, providing a broad spectrum for evaluation.
It is designed to test models' abilities in both knowledge recall and reasoning, making it a stringent benchmark for general language understanding.
An advanced variant (MMLU-Pro) comprises over 12,000 rigorously curated questions from academic exams and textbooks, spanning 14 diverse domains including Biology, Business, Chemistry, Computer Science, Economics, Engineering, Health, History, Law, Math, Philosophy, Physics, Psychology, and Others.

MMLU-pro is an enhanced benchmark designed to evaluate language understanding models across broader and more challenging tasks
Number of Datapoints: The benchmark comprises approximately 57 tasks, each containing around 500 multiple-choice questions, totaling about 28,500 questions.
Metrics: Performance is measured using accuracy, calculated as the percentage of correctly answered questions.

2.2 ARC (AI2 Reasoning Challenge)
Description: ARC is a benchmark focusing on scientific reasoning, presenting models with multiple-choice science questions that require complex reasoning and knowledge application (GPT-O3 gained a lot of attention by beating human threshold here). Arguably this serves as hallmark of reasoning and pattern understanding (recently authors launched ARC2).
The Challenge Set is specifically curated to include questions that are difficult for both machines and humans, aiming to push the boundaries of evaluating reasoning.
ARC emphasizes the need for models to integrate multiple pieces of information, simulating real-world scientific problem-solving.

Number of Datapoints: The dataset contains 7,787 science questions, divided into an Easy Set with 5,228 questions and a Challenge Set with 2,559 questions.
Metrics: Evaluation is based on accuracy, representing the percentage of questions answered correctly.



2.3 HellaSwag
Description: HellaSwag is designed to assess a model's common-sense reasoning by presenting sentence completion tasks where the model must choose the most plausible continuation from multiple options.
Here the questions are adversarially filtered, meaning they are specifically selected to be challenging for AI models, even if they rely on superficial patterns.
Despite its difficulty for machines, human participants achieve near-perfect scores, highlighting the gap between human and machine common-sense reasoning.

Number of Datapoints: The dataset consists of 70,000 multiple-choice questions, each with four possible endings.
Metrics: Performance is measured using accuracy, indicating the proportion of correctly chosen ending.

2.4 GSM8K (Grade School Math 8K)
Description: GSM8K is a dataset focused on evaluating a model's ability to solve grade-school-level math word problems, testing arithmetic and problem-solving skills.
Problems are designed to require multi-step reasoning, reflecting the complexity of real-world math challenges faced by grade-school students.
The dataset serves as a benchmark for assessing the mathematical reasoning capabilities of language models, an area where many models traditionally struggle.

Number of Datapoints: The dataset comprises 8,000 diverse math word problems.
Metrics: Performance is measured using Exact Match (EM), indicating the percentage of problems for which the model provides the correct final answer.

2.5 DROP (Discrete Reasoning Over Paragraphs)
Description: DROP is a reading comprehension benchmark that requires models to perform discrete reasoning over paragraphs, such as arithmetic computations and logical inferences, to arrive at the correct answer.
Challenges models to go beyond surface-level text matching, requiring genuine understanding and manipulation of information presented in the text.
The benchmark includes questions that necessitate numerical reasoning, such as addition and subtraction, within the context of the passage.
Number of Datapoints: The dataset contains 96,567 questions over 8,000 paragraphs.
Metrics: Evaluation is based on Exact Match (EM) and F1 scores, measuring the precision and recall of the predicted answers.
2.6 PIQA (Physical Interaction Question Answering)
Description: PIQA focuses on common-sense reasoning about physical interactions. It tests a model's understanding of the physical world by presenting questions about everyday situations and asking which of two solutions is more plausible.
It addresses the gap in AI understanding of physical common sense knowledge, such as the typical use of objects and the feasibility of actions.
The dataset includes scenarios that require reasoning about tool use, object affordances, and basic physical principles.

Number of Datapoints: The dataset contains 20,000 training questions and 2,000 validation questions, each with two possible answers.
Metrics: Performance is measured by accuracy, indicating the percentage of questions for which the model selects the correct, more plausible solution.

There are more similar benchmarks for example LogicQA, TruthfulQA, but, they are more or less very similar to above mentioned ones.
3. Generation benchmarks
Beyond simple classification / predictive outputs, the ability of LLM/SLM to generate high fidelity output/perform completion task serves as a really important benchmarks, specially for smaller models where due to restrictions in parameter size; emergent properties like reasoning is less noticeable.
3.1 WMT (Workshop on Machine Translation)
Description: The Workshop on Machine Translation (WMT) is an annual conference that provides a platform for evaluating machine translation systems across various language pairs. It offers shared tasks that challenge participants to develop models capable of translating text between different languages accurately.
WMT has been instrumental in advancing machine translation research by providing standardized datasets and evaluation frameworks since 2006.
The conference has expanded to include tasks beyond translation, such as quality estimation and multimodal translation, reflecting the evolving challenges in the field.

Number of Datapoints: The number of datapoints varies annually and depends on the specific language pairs and tasks. Each year's dataset typically includes tens of thousands of sentence pairs for training, with separate validation and test sets.
Metrics: Evaluation metrics commonly used in WMT include BLEU (Bilingual Evaluation Understudy), METEOR, and TER (Translation Edit Rate), which assess the quality of machine-generated translations compared to human references.

3.2 CNN/DailyMail
Description: The CNN/DailyMail dataset is designed for training and evaluating models on the task of abstractive text summarization. It consists of news articles paired with multi-sentence summaries, challenging models to generate concise and coherent summaries that capture the essence of the original articles.
The dataset was created by harvesting online news articles and their associated summaries, providing a large-scale resource for summarization research.
It has been widely adopted in the NLP community, serving as a benchmark for evaluating the performance of various summarization models.

Number of Datapoints: The dataset comprises approximately 312,000 training examples, 13,400 validation examples, and 11,500 test examples.
Metrics: Performance is typically measured using ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrics, including ROUGE-1, ROUGE-2, and ROUGE-L, which compare the overlap of n-grams between the generated summaries and reference summaries.

3.3 XSum (Extreme Summarization)
Description: XSum is a dataset focused on extreme summarization, where the goal is to generate a single-sentence summary that captures the most salient information from a BBC news article. This task requires models to perform significant abstraction and compression of information.
This is more challenging summarization task compared to other datasets, as it requires generating highly concise summaries that are not extractive in nature.
The dataset encourages the development of models capable of true abstraction, moving beyond mere sentence extraction.

Number of Datapoints: The dataset contains 204,045 article-summary pairs, split into training, validation, and test sets.
Metrics: Evaluation is conducted using ROUGE metrics, particularly ROUGE-1, ROUGE-2, and ROUGE-L, to assess the quality of the generated summaries.

3.4 CommonGen
Description: CommonGen is a dataset designed to test generative commonsense reasoning. Given a set of concept words; the task is to generate a coherent sentence that incorporates all the provided concepts, evaluating the model's ability to understand and generate plausible everyday scenarios.
Major focus is on testing a model's ability to generate sentences that reflect common sense knowledge, a crucial aspect of human language understanding.
The dataset encourages research into grounding language generation in real-world contexts, moving beyond syntactic correctness to semantic plausibility.

Number of Datapoints: The dataset comprises 35,141 concept sets and 79,051 sentences, divided into training, validation, and test sets.
Metrics: Evaluation metrics include BLEU, METEOR, and CIDEr, which assess the quality and relevance of the generated sentences.

4. Retrieval benchmarks
With advent of RAG pipelines and sudden boost in high quality of retrieval models (like bert, bge, etc.) in my opinion this becomes a really important category to discuss. Though the benchmarks had existed for quite some time now, but, earlier conventional method like TF-IDF, BM25, even GLOVE, etc. served as retrievers and re-rankers.
4.1 BEIR (Benchmarking Information Retrieval)
Description: BEIR is a comprehensive benchmark suite designed for evaluating information retrieval models across a diverse set of tasks and datasets. It encompasses 18 datasets spanning 9 distinct retrieval tasks, including fact-checking, question-answering, biomedical information retrieval, news retrieval, and more. This diversity allows for a holistic assessment of retrieval models in various contexts.
Facilitates zero-shot evaluation, enabling researchers to assess how well models generalize to unseen tasks without task-specific training.
The benchmark has been instrumental in standardizing the evaluation of retrieval models, promoting reproducibility and comparability in IR research.

Number of Datapoints: The benchmark includes a wide range of datasets, each with its own corpus size and number of queries. For instance, the Natural Questions (NQ) dataset within BEIR comprises approximately 3,500 queries and a corpus of around 2.7 million documents.
Metrics: Evaluation metrics commonly used in BEIR include:
nDCG@k (Normalized Discounted Cumulative Gain at rank k): Measures the ranking quality, emphasizing the relevance of documents at higher positions/ranks.
Recall@k: Assesses the fraction of relevant documents retrieved in the top k results.

4.2 MS MARCO (Microsoft MAchine Reading COmprehension)
Description: MS MARCO is a large-scale dataset created to advance research in machine reading comprehension and information retrieval. It consists of real anonymized user queries from Bing search logs, along with corresponding passages, documents, and answers, providing a rich resource for training and evaluating retrieval models.
MS MARCO has become a foundational dataset for training and benchmarking retrieval models, influencing numerous advancements in the field.
The dataset's real-world queries and diverse passage collection provide a realistic challenge for IR systems, bridging the gap between research and practical applications.

Number of Datapoints: The dataset includes approximately 1 million queries, each paired with multiple passages, and a subset with annotated relevant documents.
Metrics: Evaluation metrics for MS MARCO include:
MRR (Mean Reciprocal Rank): Evaluates the rank position of the first relevant document.
nDCG@k: Assesses the quality of the ranking, considering the positions of relevant documents (similar to test mentioned above).

4.3 FEVER (Fact Extraction and VERification)
Description: FEVER is a dataset focused on fact-checking, where models are tasked with verifying the veracity of claims by retrieving relevant evidence from Wikipedia. This involves not only retrieving pertinent documents but also assessing their content to determine the truthfulness of the claims.
It has been a catalyst for research in automated fact-checking, a critical area in combating misinformation.
The dataset's structure promotes the development of models that can provide transparent and interpretable evidence for their decisions.

Number of Datapoints: The dataset comprises over 185,000 claims, each labeled as supported, refuted, or not enough information, along with corresponding evidence.
Metrics: Evaluation metrics is combination of:
Label Accuracy: Measures the correctness of the claim classification (supported, refuted, not enough information).
Evidence Precision and Recall: Assesses the model's ability to retrieve the correct evidence supporting its classification.

4.4 Natural Questions (NQ)
Description: Developed by Google, the Natural Questions dataset is designed to reflect real user inquiries. It comprises questions posed by users to the Google search engine, along with corresponding Wikipedia pages containing the answers, challenging models to locate precise information within long documents.
Major importance is given to the retrieval of concise answers from extensive documents, simulating real-world information-seeking scenarios.
The dataset has spurred research into efficient retrieval methods capable of handling long-context documents, such as entire Wikipedia articles.

Number of Datapoints: The dataset contains approximately 300,000 training examples, with additional validation and test sets.
Metrics: Evaluation metrics include:
Precision@k: Measures the proportion of relevant documents in the top k results.
Recall@k: Assesses the ability to retrieve all relevant documents within the top k results.

There are more similar ones like TREC, HotpotQA (around 100k QA pairs), etc. but we can skip them here.
5. Extra/Miscellaneous benchmarks
This category mostly comprises of QA type benchmarks and reasoning tasks which I couldn’t fit info above categories, as either they have a very distinct language dependency (as in WSC) or are specifically QA datasets.
5.1 Winograd Schema Challenge (WSC)
Description: The Winograd Schema Challenge is designed to evaluate a system's capability for common sense reasoning through pronoun resolution. Each problem presents a sentence with an ambiguous pronoun, and the task is to determine its correct referent. These challenges are crafted to be straightforward for humans but challenging for machines, as they require contextual and common-sense understanding.

Number of Datapoints: The original WSC dataset comprised 100 manually constructed problems. Over time, this expanded to 285 examples, with the first 273 frequently used for consistency in evaluations
Metrics: Performance is typically measured by the accuracy of correctly resolving the pronoun references.
Interesting Facts:
In 2016, a competition sponsored by Nuance Communications offered a $25,000 prize for achieving over 90% accuracy; however, no participant surpassed this threshold
The WSC has inspired the creation of more extensive datasets like WinoGrande, which consists of 44,000 problems designed to enhance both scale and difficulty.

5.2 WiC (Word-in-Context)
Description: WiC is a benchmark designed to assess a model's ability to determine if a word maintains the same meaning across different contexts. Each example provides a target word and two sentences; the task is to decide whether the sense is identical in both sentences.
It samples its sentences from existing lexical resources like WordNet, VerbNet, and Wiktionary, ensuring a rich diversity of contexts.
The benchmark is part of the SuperGLUE benchmark suite, which aims to provide a comprehensive assessment of language understanding capabilities.
Number of Datapoints: The dataset comprises 5,428 sentence pairs, split into training, development, and test sets.
Metrics: Performance is evaluated using accuracy, reflecting the proportion of correct judgments about the sense consistency.
5.3. SQuAD (Stanford Question Answering Dataset)
Description: SQuAD is a reading comprehension dataset where models are tasked with answering questions based on given passages from Wikipedia articles. The answers are typically spans of text extracted directly from the passages.
SQuAD has been a pivotal benchmark in the development of reading comprehension models, with numerous models achieving human-level performance on the dataset.
The introduction of unanswerable questions in SQuAD v2.0 addresses the challenge of model overconfidence, promoting the development of systems that can acknowledge uncertainty.

Number of Datapoints: The original SQuAD dataset (v1.1) contains over 100,000 question-answer pairs. The subsequent version (v2.0) adds more than 50,000 unanswerable questions, increasing the challenge by requiring models to determine when no answer is present in the text.
Metrics: Evaluation metrics include:
Exact Match (EM): The percentage of predictions that match the ground truth answers exactly.
F1 Score: The harmonic mean of precision and recall, measuring the overlap between predicted and ground truth answers.

5.4 MultiRC (Multiple Sentence Reading Comprehension)
Description: MultiRC is a reading comprehension dataset (very similar to SQuaD) that requires models to answer questions based on multi-sentence passages. Each question is associated with multiple candidate answers, and each answer must be judged independently as true or false, making it a multi-label classification task.
Underlying Task is to integrate information across multiple sentences to arrive at correct answers, reflecting more complex reasoning processes.
The dataset is part of the SuperGLUE benchmark, contributing to a comprehensive evaluation of machine understanding.

Number of Datapoints: The dataset includes 5,000 questions over 870 passages, with each question having multiple answer options.
Metrics:
Exact Match (EM): The proportion of questions for which all candidate answers are correctly classified.
F1 Score: Measures the balance between precision and recall for the true/false classifications of each answer option.

5.5 GPQA (Graduate-Level Google-Proof Q&A Benchmark)
Description: GPQA is a challenging dataset designed to evaluate the capabilities of Large Language Models (LLMs) and scalable oversight mechanisms. It comprises multiple-choice questions meticulously crafted by domain experts in biology, physics, and chemistry, intentionally designed to be high-quality and extremely difficult.
The questions are designed to be "Google-proof," meaning they cannot be easily answered by simple web searches, thus testing the deep understanding and reasoning capabilities of models.
The dataset serves as a benchmark to assess the performance of LLMs in specialized and advanced domains.

Number of Datapoints: The dataset consists of 448 multiple-choice questions.
Metrics: Models are evaluated based on their accuracy in selecting the correct answer from the provided choices.

5.6 LiveCodeBench (LCB)
Description: LiveCodeBench is a comprehensive and contamination-free benchmark designed to evaluate Large Language Models (LLMs) in coding tasks. It continuously aggregates new problems over time from various competitive programming platforms, ensuring an up-to-date and challenging set of tasks. Beyond code generation, LiveCodeBench assesses broader coding-related capabilities, including self-repair, code execution, and test output prediction. LiveCodeBench emphasizes contamination-free evaluation by selecting problems that are unlikely to have been seen by models during their training, ensuring a genuine assessment of their coding abilities.
The benchmark's dynamic nature, with continuous updates from recent contests, provides a robust platform for evaluating the evolving capabilities of LLMs in coding.
By focusing on a wide range of coding skills beyond mere code generation, LiveCodeBench offers a holistic assessment of a model's proficiency in practical programming scenarios.

Number of Datapoints: As of its latest update, LiveCodeBench hosts over 300 high-quality coding problems collected between May 2023 and February 2024. These problems are sourced from platforms like LeetCode, AtCoder, and CodeForces.
Metrics: Evaluation metrics in LiveCodeBench encompass:
Code Generation Accuracy: Assessing the correctness of code produced by LLMs.
Self-Repair Capability: Evaluating the model's ability to identify and correct errors in its own code.
Execution Success Rate: Measuring the proportion of code solutions that run successfully and produce correct outputs.
Test Output Prediction: Determining how accurately the model can predict outputs for given test cases without executing the code.

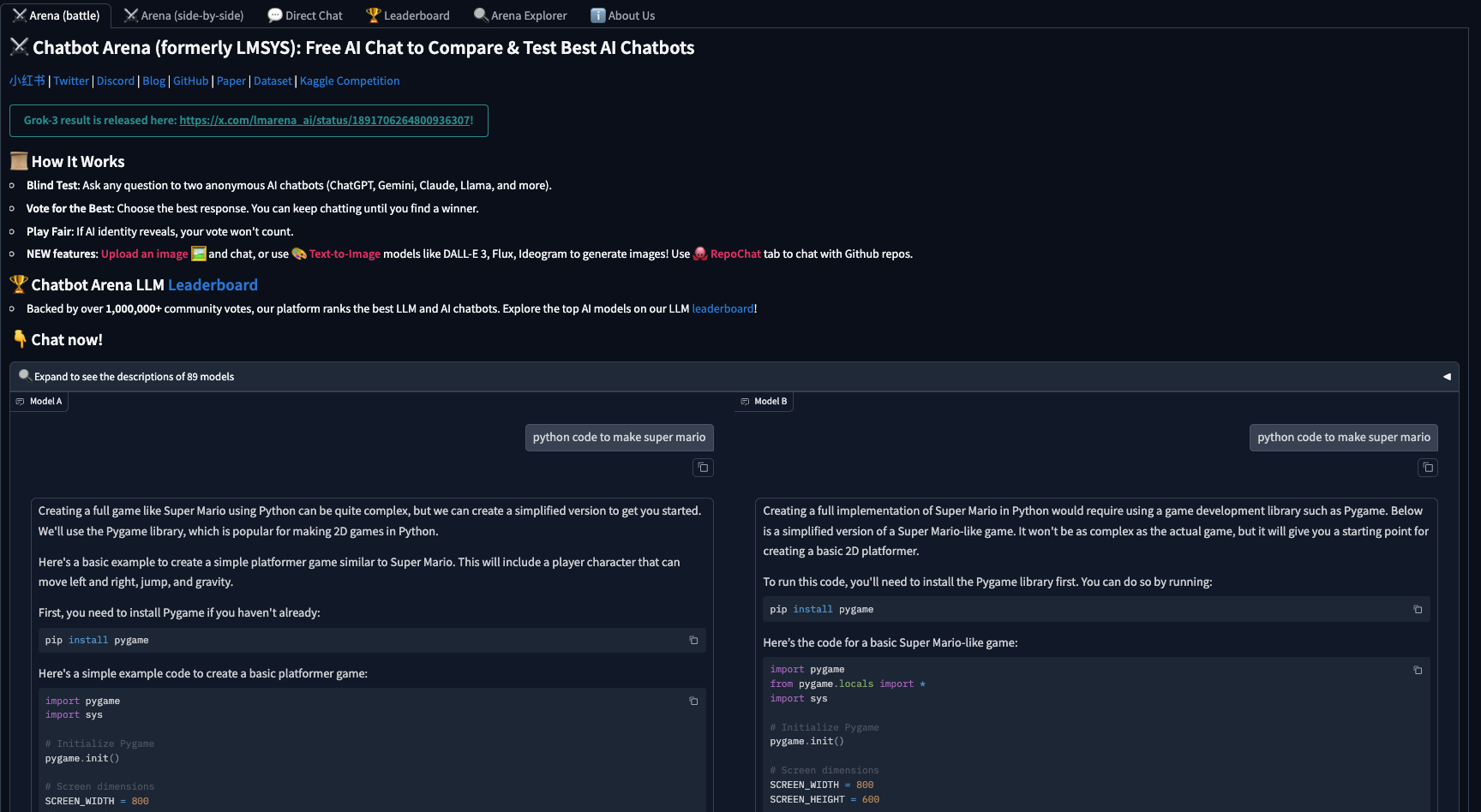
5.7 Chatbot Arena (earlier LMSYS)
Description: Chatbot Arena is an open platform developed by the Large Model Systems Organization (LMSYS) for evaluating Large Language Models (LLMs) based on human preferences. It features anonymous, randomized battles between models in a crowdsourced manner, allowing users to compare and assess different LLMs. The platform has been operational for several months, providing a dynamic and evolving leaderboard that reflects the performance of various LLMs based on real user interactions. It has become a widely referenced resource in the AI community, cited by leading LLM developers and companies.
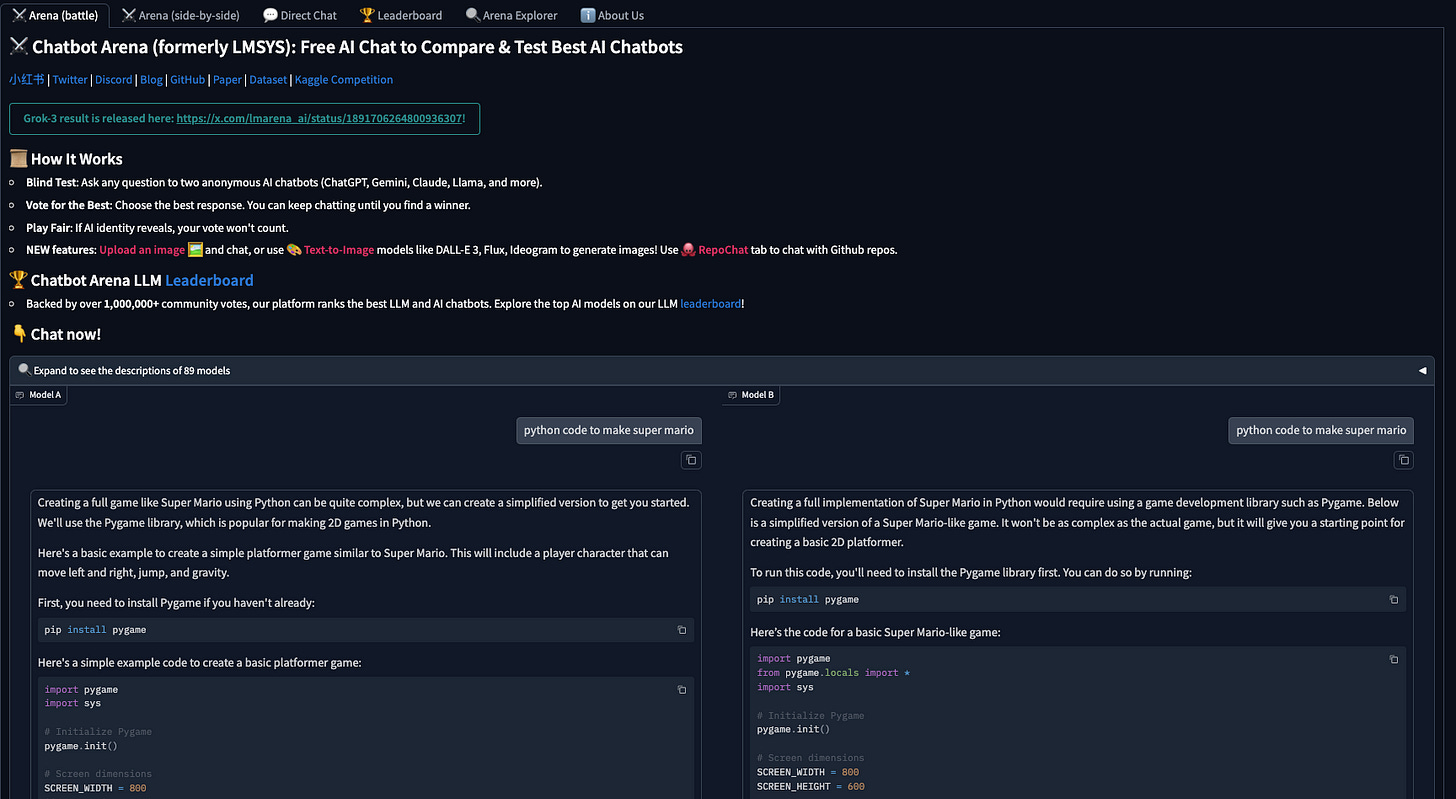
Number of Datapoints: The platform has amassed a tonnes of user votes, contributing to a substantial dataset of human preferences and interactions. The platform is open and crowdsourced nature ensures a diverse range of inputs, enhancing the robustness and credibility of the evaluations.
Metrics: The primary evaluation metric is the Elo rating system, a method widely used in competitive games like chess, which calculates the relative skill levels of models based on user preferences in pairwise comparisons.
5.8 American Invitational Mathematics Examination (AIME)
Description: The AIME is a prestigious mathematics competition in the United States (not a typical LLM specific benchmark), serving as an intermediate examination between the AMC (American Mathematics Competitions) and the USA Mathematical Olympiad (USAMO). It is designed to challenge students with complex problem-solving questions that require a deep understanding of high school mathematics. Each AIME consists of 15 questions. The exam is administered annually, and since its inception in 1983, there have been multiple versions, including AIME I and AIME II, offered each year. Therefore, the total number of unique questions over the years amounts to several hundred.
Answers are integers between 0 and 999, eliminating the possibility of guessing from multiple-choice options. The AIME covers topics such as algebra, geometry, number theory, and combinatorics, often requiring creative and integrative problem-solving approaches. when it's told to use more tokens - the \"just ask o1-mini to think longer\" region of the")
Metrics: Scoring is straightforward: each correct answer yields one point, with no penalty for incorrect answers. Thus, scores range from 0 to 15. These scores are combined with AMC results to determine qualification for the USAMO.
 when it's told to use more tokens - the \"just ask o1-mini to think longer\" region of the")
5.9 HumanEval
HumanEval is a widely used benchmark designed to assess the code generation capabilities of Large Language Models (LLMs). It consists of a curated set of python programming problems that require models to generate correct, functional code based on natural language prompts. The problems cover a range of algorithmic and logical challenges, making it a reliable benchmark for evaluating a model’s reasoning and programming skills. HumanEval was introduced by OpenAI in their Codex paper to benchmark code generation capabilities. The dataset is contamination-free, meaning it is carefully curated to avoid problems that LLMs might have encountered during pretraining. Also It has become one of the gold standard benchmarks for evaluating models like GPT-4, Claude, and CodeLlama on real-world coding tasks. Unlike synthetic datasets, HumanEval problems mimic real-world coding challenges, making it a practical benchmark for assessing LLMs in software development scenarios.

Number of Datapoints:
The benchmark includes 164 programming problems, each accompanied by function signatures and docstrings that specify the expected behavior.Metrics:
Pass@k: The primary evaluation metric, which measures the probability that at least one of the model’s top k generated solutions is correct when executed against unit tests. It is often reported as Pass@1, Pass@10, and Pass@100.
Execution Accuracy: Determines whether the generated code runs successfully without syntax errors.
Correctness: Evaluates whether the code meets all specified requirements in the problem statement.
6. Multi-lingual benchmarks
Most/all of the benchmarks we discussed above have english as dominant language. But, for any general purpose AI/framework, a step beyond it being reasonably good in solving complex tasks is to solve the same across different (strongly or under-represented) samples. Hence, the given set of benchmarks serve a really important purpose.
6.1 GlobalBench
Description: GlobalBench is an extensive benchmark designed to track and promote equitable progress in NLP across a vast array of languages and tasks. Unlike static benchmarks, It is dynamic by nature, continually integrating new datasets and system outputs to provide a comprehensive evaluation of NLP models globally.
aims to identify under-served languages, rewarding research efforts directed towards these languages to promote inclusivity.
The benchmark provides a multi-faceted view of language technology's service to people worldwide, considering both performance and real-world utility.
Number of Datapoints: As of its latest update, GlobalBench encompasses 966 datasets covering 190 languages, with 1,128 system outputs spanning 62 languages.
Metrics: GlobalBench evaluates models using multiple metrics, including:
Accuracy: Measures the correctness of model predictions.
Per-Speaker Utility: Assesses the practical benefit of the model to speakers of each language.
Equity: Evaluates the fairness in performance across different languages, ensuring that less-resourced languages are not disadvantaged.
6.2 Belebele Benchmark
Description: The Belebele Benchmark is a multiple-choice machine reading comprehension dataset that spans 122 language variants. It is fully parallel, enabling direct comparison of model performance across all included languages.
The English portion of Belebele is challenging enough to test state-of-the-art language models, indicating the benchmark's difficulty.
The dataset enables evaluation of both multilingual masked language models (MLMs) and large language models (LLMs), providing insights into their capabilities across diverse languages.

data sample
Number of Datapoints: Each question in the dataset is based on a short passage from the Flores-200 dataset and has four multiple-choice answers.
Metrics: Performance is evaluated using Accuracy based on percentage of correctly answered questions.

6.3 LEXTREME
Description: LEXTREME is a multilingual and multi-task benchmark specifically tailored for the legal domain. It encompasses a diverse set of legal NLP tasks across multiple languages, aiming to facilitate the development and evaluation of models in legal contexts.
Despite advancements in NLP, LEXTREME remains challenging; the best baseline model, XLM-R large, achieves an aggregate score of 61.3, indicating significant room for improvement.
LEXTREME is readily accessible to researchers and practitioners, with resources available on Hugging Face, including evaluation code and a public project with all runs.
Number of Datapoints: It is comprised of 11 datasets covering 24 languages, offering a broad spectrum of legal NLP challenges.
Metrics: Two primary scores are proposed: one based on datasets and another on languages, providing a holistic view of model performance.
7. Indic-language specific benchmarks
I decided to have a separate section of Indian-language specific benchmarks, mostly, because of the importance as well as tremendous work done by AI4Bharat (driven by IIT-M) and multiple other organizations in last few years.
7.1 IndicNLP Corpus
Description: The IndicNLP Corpus is a large-scale, general-domain monolingual corpus developed to support NLP research and applications for Indian languages. It encompasses text from diverse sources, providing a rich linguistic resource.
The corpus supports a wide range of languages, including Hindi, Bengali, Gujarati, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, and Telugu.
It has been instrumental in training word embeddings and language models tailored for Indian languages, facilitating advancements in regional NLP applications.
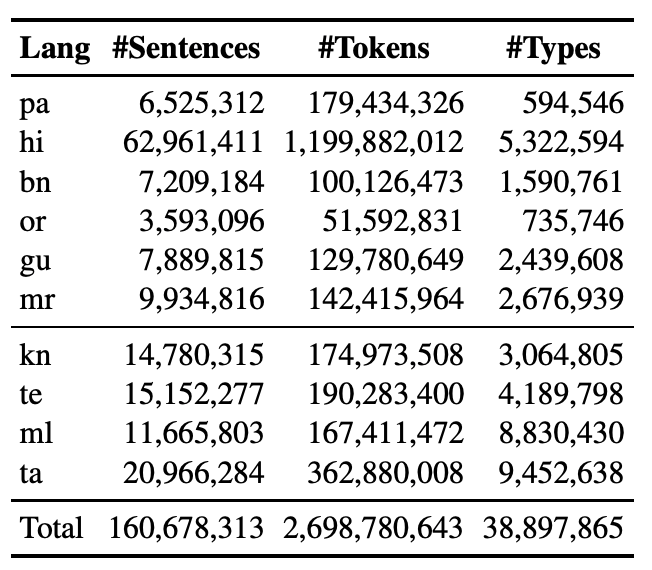
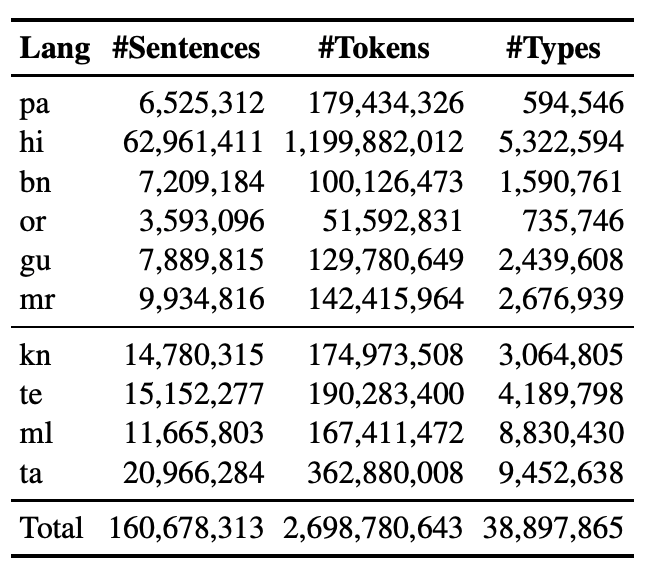
IndicNLP corpus statistics
Number of Datapoints: The corpus contains approximately 2.7 billion words across 10 Indian languages from two language families.
Metrics: As a foundational dataset, the IndicNLP Corpus itself doesn't have direct evaluation metrics. However, models trained on this corpus are typically assessed using standard NLP metrics relevant to specific tasks, such as accuracy for classification or BLEU scores for translation.
7.2 Naamapadam
Description: Naamapadam is a comprehensive Named Entity Recognition (NER) dataset designed for Indian languages. It focuses on annotating entities such as Person, Location, and Organization names across multiple languages.
The training data was automatically generated by projecting entities from English sentences to their corresponding Indian language translations, leveraging the Samanantar parallel corpus.
Manual annotations were created for the test sets in 9 languages, ensuring high-quality evaluation data.
The release includes IndicNER, a multilingual IndicBERT model fine-tuned on the Naamapadam training set, achieving an F1 score exceeding 80 for 7 out of 9 test languages.

Number of Datapoints: The dataset comprises over 400,000 sentences annotated with at least 100,000 entities across 9 out of 11 major Indian languages.
Metrics: Models evaluated on Naamapadam are typically assessed using the F1 score, which balances precision and recall to provide a single performance metric.
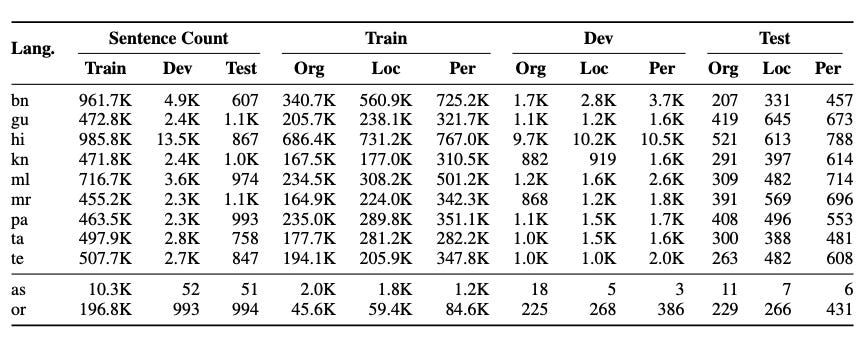
7.3 IndicMT Eval
Description: IndicMT Eval is a dataset created to meta-evaluate machine translation metrics specifically for Indian languages. It aims to assess the correlation between automatic evaluation metrics and human judgments in the context of Indian language translations.
The study found that pre-trained metrics like COMET have the highest correlations with human annotator scores for Indian languages.
It also highlighted that existing metrics often fail to adequately capture fluency-based errors in Indian languages, indicating a need for developing more tailored evaluation metrics.

Number of Datapoints: The dataset comprises 7,000 fine-grained annotations spanning 5 Indian languages and 7 machine translation systems.
Metrics: The primary focus is on evaluating the correlation between automatic metrics (such as BLEU, COMET) and human annotations, using statistical measures like Pearson and Spearman correlation coefficients.

Thoughts/Potential issues
Most of the benchmarks (like GLUE, SQuAD, etc.) are saturated for LLMs, these models are able to achieve high/human level/beyond human performance, hence, limiting there usefulness.
Training a biased model is a major hazard, though there is a huge effort for rich and low bias datasets, still majority of effort lies with dominant languages like English, German, etc. hence making model susceptible to picking up biasness from low represented/curated languages, hence, (as discussed in LCMs), the representation space is shared for most of the corpus, making model inherently biased towards things.
Out-of-distribution generalization is hard to define and test, as the benchmark datasets are the cleanest representation of actual real world datasets.
The metrics in itself are heavily dependent on our euclidean and simplistic assumption, hence restricted by our abilities to understand and define a problem. There exists a tradeoff between quality/complexity and explainability of metric, making the entire evaluation landscape harder to work with.
There is significant lack of evolving or intelligent benchmarks, which could increase/behave as adversary to actually test and understand model capabilities. Also, given the benchmarks are static and known, model objective functions could be tuned during test time to perform specifically for beating these benchmarks.
Also, many of the reasoning benchmarks like ARC, test pattern matching instead of a proper cognitive test, its similar to measuring intelligence through IQ tests only (which in itself is heavily biased toward STEM, hence incomplete).
A significant effort has to be given in to develop high quality task specific multi-lingual datasets to ensure a holistic evaluation.
Conclusion
With this we come to the end of our blogpost, in this very long (quite literally) article, we started with understanding why benchmarks are important, then we discussed components of any standard benchmark intuitively, from there we jumped to understand multiple complex but useful metrics (like BLEU, ROGUE, etc.) as well as multiple datasets (like ARC, MMLU, PIQA, etc.) across wide variety of categories. Finally we ended with some thoughts and concerns over current state of benchmarks.
To be honest, there are many more really important benchmarks out there like MBPP, MulitPL-E, and many more. I would encourage you to visit and try few of these benchmarks yourself to understand fined details and maybe even contribute in building/formulating better/evolving benchmarks. Eventually, the goal should be to go beyond these metrics and benchmarks to build a fair, general-purpose and capable of reasoning/intelligent (whatever that means) models.
That's all for today.
We will be back with more useful articles, till then happy Learning. Bye👋