
DeepSeek-R1 : The true open AI out there
Few weeks back DeepSeek walked into picture and blew the internet with DeepSeekR1 which shattered all the benchmarks, interestingly they open-sourced the model and method, which we will discuss here.


Recently (December 2024) openAI released O1 which not only pushed the limits of LLMs on really complex tasks, but also, prompted us to wonder over all the beautiful methodology that goes behind such capable systems.
The current open-sourced versions which include llama, Qwen, mistral family of models follow more or less the conventional methods and hence, are not on par with the o1 series of models and as OpenAI contrary to the name never shared any deep-dive into the actual development of such large scale models, hence we are only left with trial and error.
Few weeks back DeepSeek walked into picture and just blew the internet. Their model DeepSeekR1 not only shattered all the benchmarks, but interestingly they open-sourced the model weights as well as a comprehensive report/paper on everything they did to make such large scale model. In this article we will discuss about the methodology and topics surrounding DeepSeekR1.

Table of contents
Introduction
Methodology
sketch/overview of the process
process in detail
DeepSeek R1-zero
GRPO explanation
DeepSeek R1
Multi-step training
Smaller distilled models
glimpse over ablation
Cost and compute optimization
Outcome and results
Thoughts
Conclusion
Introduction
Conventional methods for training large language models follows a three step phase.
 for Language Models")
Pre-training : This is generally a Self-supervised learning phase, where model learn semantics and data distribution without any specific objective in place. This phase usually trains model in an auto-regressive setup (next word prediction). The final model from this step is assumed to have strong semantic understanding of data. From here on alignment via fine-tuning is performed.
Supervised fine-tuning : Here an annotated dataset is used to tune the Pre-trained model to generate accurate samples. Furthermore, techniques like rejection or importance sampling is used for sample filtering.
Alignment tuning : This is where model learn to follow query and generate response with strong alignment to user query, hence, it is also called as instruction-tuning. This is where for stronger alignment objective reinforcement learning comes into picture. Methods like RLHF (Reinforcement learning through human feedback) and RLAIF (Reinforcement learning through AI feedback) are used. Issue with RLHF is in the sheer number of labelled samples that needs to be collected, whereas RLAIF solves this by using a stronger model instead of humans, but, ends up setting a requirement for really strong model and eventually becoming a by-product of it.
Both tuning and alignment steps suffer from few major issues:
1. They require a large number of collected samples.
2. Quality is upper-bounded based on the capability of critic model for alignment.
3. A large amount of compute is required due to the additional step of tuning.
This is where deepseekR1 brings it's innovation as they use pure RL based end-to-end training, hence, bypassing any need of SFT.

Given this context, let's start exploring Deepseek-R1 now.
Methodology
The entire methodology could be boiled/sketched in three steps:
Train DeepseekR1-zero (the larger, capable yet noisy model)
Use Deepseek-R1-zero to tune Deepseek-v3 base, hence new model is named as DeepSeekR1 (the model for which internet is hyped about)
Tune smaller open models like qwen using deepseekR1.
With sketch in our mind, let's discuss in detail:
Step 1 : Deepseek-R1-zero

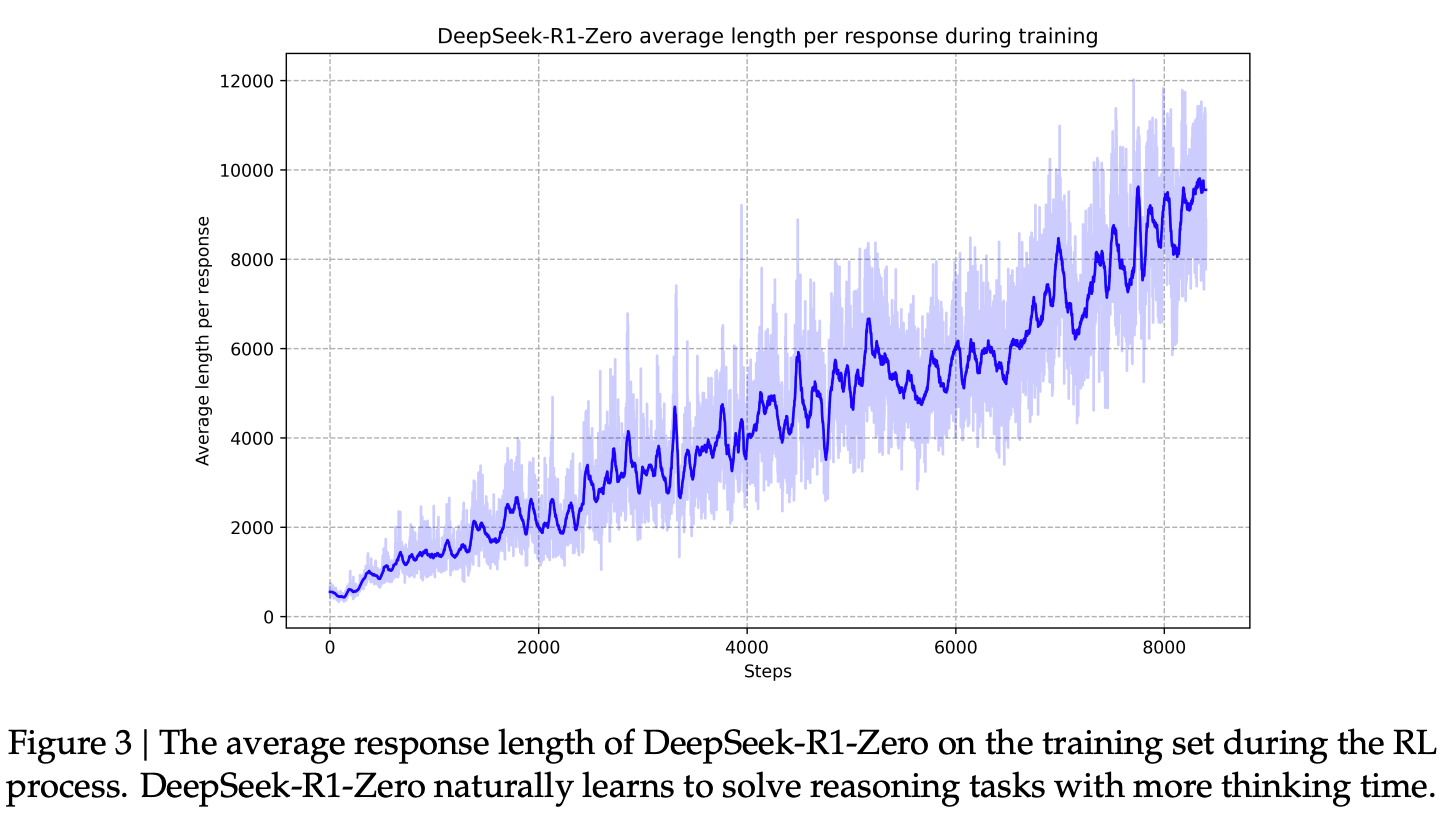
As the name suggest this is the 0th step of the entire process. Here they have two main components, first is CoT incentivization and pure RL. Earlier/conventional models had multi-step training as they didn't had any concept of during-training CoT which could be leveraged to make model stronger during the first phase/step itself, here it uses pure RL based training with a specialized prompt which contains placeholders for CoT and answer. This results in a strongly aligned and reasoning capable model from step 1 itself. The model learns the reasoning capabilities as an emergent property of RL based alignment. Check the prompt image below

For the RL procedure, instead of conventional PPO based optimization (which is supervised in nature and hence limited by number of labelled samples); authors ended-up using GRPO (Group relative policy optimization) to tune a policy model as objective for format and accuracy alignment.
GRPO Explained
GRPO eliminates the need to train a separate critic model as we saw in above discussions, hence, making it independent of labelled samples and is resource incentivize. Here, instead of chasing a global objective (conventionally done through PPO), we chase a local stochastic objective. This could also be thought of as a mean/first moment inside the samples group (similar to how we compute mean and variance params in batch-norm of a given batch).
Methods like PPO use a global objective, whereas GRPO relies on a local objective. While PPO approximates the optimal solution, its dependence on labels limits its ability to overcome the bottleneck created by sample size. On the other hand, although GRPO pursues a sub-optimal objective, it can break this bottleneck, continuing to improve over time as training progresses. This improvement is evident in the diagram below, where GRPO continues to make progress across epochs, even as it works with less-than-ideal objectives.
Here is the main GRPO equation:

Simply put the equation above signifies a constraint optimization task, where the war is between primary objective term (policy ) and regularization term (KLD).
The left hand side of the equation simply talks about the quality of current model against the older ones and current batch outputs quality by measuring the advantage (A) over the group and log likelihood of response o using current vs older policy, think it like this, the log likelihood term is weightage/magnitude and advantage term (A) is the direction. It's like saying are you moving in the right direction? and is the amount of movement good enough. If we would have done this through PPO we would have needed a critic model to evaluate the outputs against the labelled set (Think of it as supervised vs Self-supervised learning).
The right hand side ensures that the change in current and previous policy is not significant/unstable. Again to keep the training stable clipping is performed.
Also, the reward signal is comprised of two sub-components which quite literally are regex matches, first, accuracy reward (to evaluate correctness of response), second, format reward (to measure formatting/structure).
The outcome of the above method is DeepSeekR1-zero model which shows some interesting features.
Model shows strong self-reflection and alignment capabilities even beating openAI O1 on reasoning benchmarks.
"The aha moments" : Model in the reasoning steps not only ponders over the current set of generated tokens, but, also backtracks and highlights important token groups/sentences.
The quality and number of reasoning tokens increase with more number of epochs, which means model spends longer time searching the solution space in a step-by-step fashion.
Inspite of all the emergent properties, the trained model faces some intrinsic issues:
1. Readability issue
2. Language mixup (interestingly model finds it easier and better to use multiple languages for answer generation unlike us humans, who stick to a single language for our tasks, this could be potential future direction to explore).
Step 2 : DeepSeek R1 (A multi-step training process)
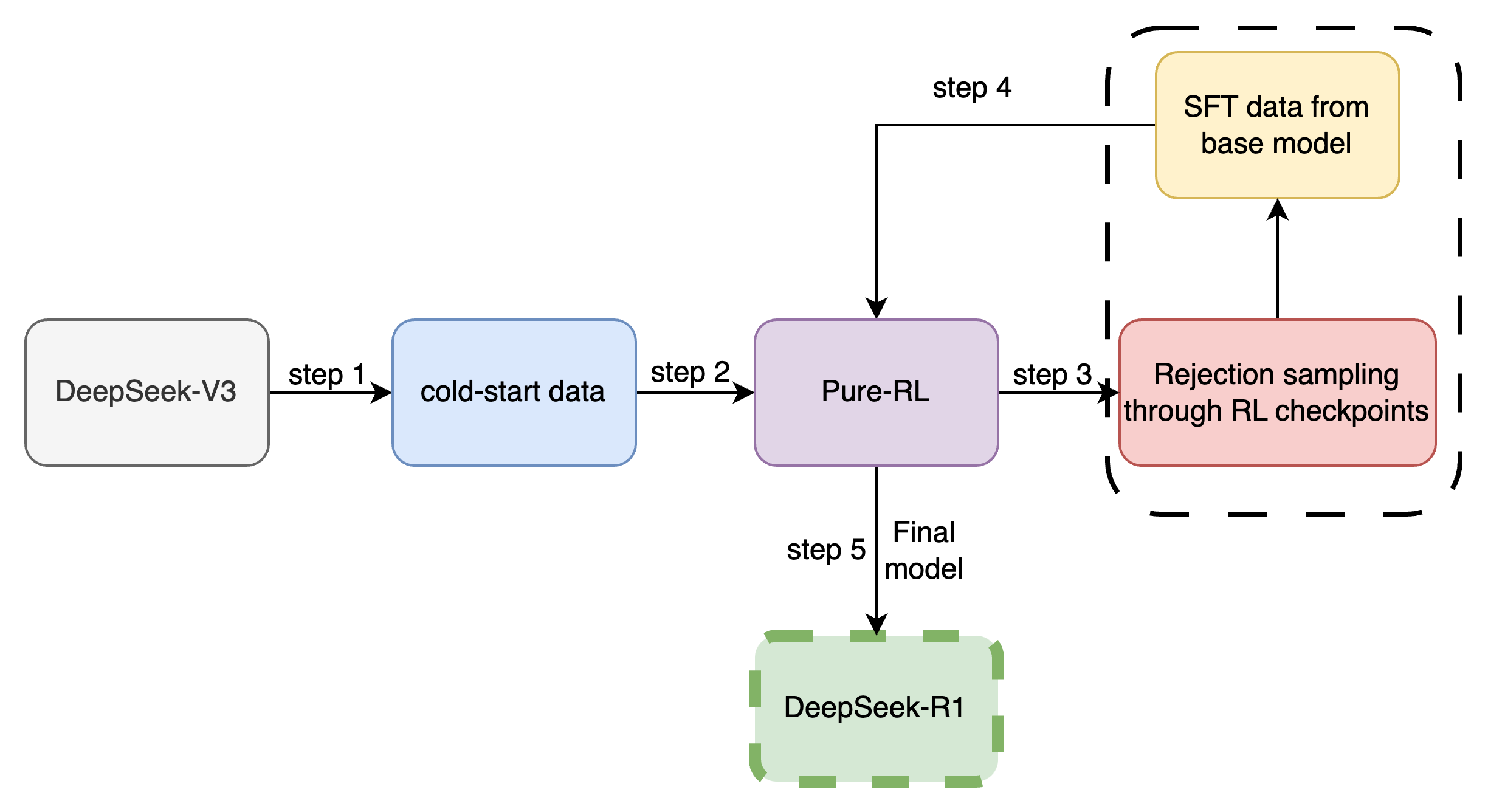
To tackle these issues a multi-stage training pipeline is used. Now, one may ask did we circled back to multi-step process after everything we pointed out to be wrong with it? The answer is unfortunately yes. Though we are employing a multi-stage method, but, instead of three we now have fewer and smaller extra steps. Here we start with DeepSeekv3-base (older model from DeepSeek) as initial model and then perform further tuning using our trained DeepSeekR1-zero from step 1. The process goes something like this:
Cold start data : A curated list of data samples with long CoTs is sampled and used to fine-tune the base v3 model which inherently serves as incentive for model to generate high quality CoT and eventually high-fidelity reasoning/outputs.
Downstream task based re-alignment over tasks such as maths, reasoning, etc using pre RL (similar to step 1). Here language consistency rewards are leveraged to ensure high quality single language generation by the model.
Almost at convergence, they perform supervised fine-tuning over a high quality data generated by rejection sampling from R1 model RL checkpoints. Rejection sampling is simply the filtering of poor quality generations to ensure only the relevant sequences from the generated data is left.
This data is then coupled with more diverse dataset again to ensure high quality yet generalized preference alignment. The outcome of this extends beyond reasoning tasks such as factual QA, role playing, etc.
Finally, the model is re-aligned using RL again to ensure generalization across multiple downstream scenarios and tasks.
The step marks the completion of DeepSeekR1 training, beyond this they leveraged this well trained/tuned model to make smaller but capable models through distillation.
Step 3 : Distillation over smaller models
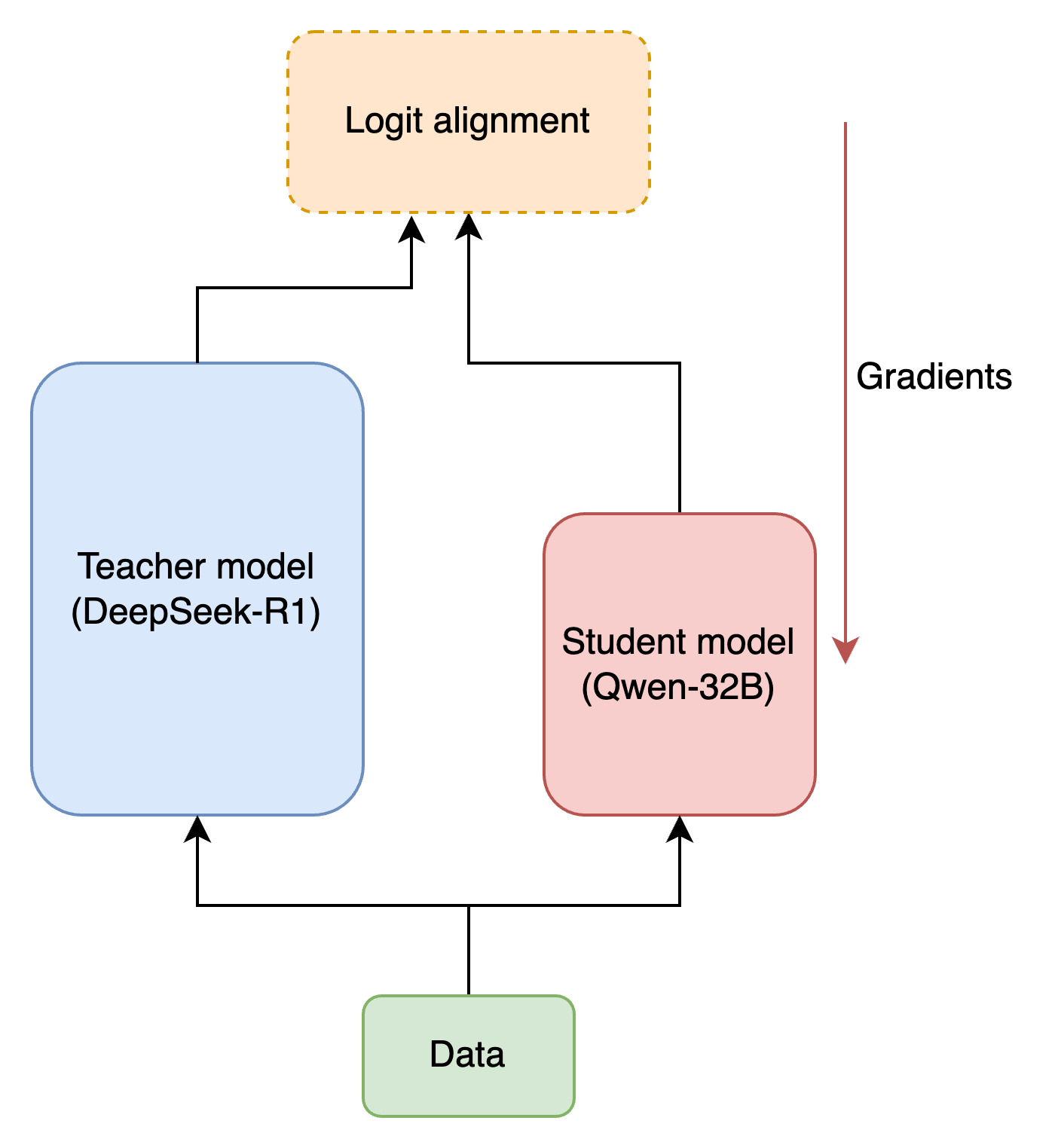
Utilizes open-sourced architectures like Qwen and llama as student and DeepSeek R1 as teacher to perform alignment based distillation.
A huge yet high quality sample of 800k datapoints are generated by deepseekR1 and then used to tune smaller models.
This helps in developing strong instruction alignment and reasoning capabilities, for which very large architecture was considered to be required.
Hence, to summarize the three step phase we discussed above,
1. Deepseek-R1-zero : trained from scratch using GRPO over a crafted prompt template. The RL procedure allows model to learn contextual thinking and reasoning through CoT. Though model is large and capable, it faces issues with language mixup and readability.
2. DeepseekR1 : The trained model from step 1 serves as parent/teacher model which is utilised across a multi-task training objective to tune a smaller yet more capable model.
3. Distillation for smaller models : DeepseekR1 is then leveraged as teacher model for tuning even smaller architectures like Qwen and llama.
Glimpse on Ablations
The authors also tried out conventional methods for reward assignment and solution search. But, these methods either are computationally expensive or doesn't make the cut for the language modelling tasks at scale. Some of them are discussed below:
Process reward models (PRMs) : This is similar to intermediate rewards generally targeted for continuous objectives across time. But, the process for allocation of rewards itself is hard to define, firstly, reward allocation to partial set of tokens is hard to perform and second it's very prone to reward hacking (the model can learn to generate sub-optimal sequence long enough to get good quality rewards, example repetition) to prevent this the mechanism has to be done manually, which is time and resource intesive.
To overcome this authors used a seperate rule based format and accuracy reward model. The setup is sparse in nature which means given the sequence is as per the ground truth you get reward 1 else 0. This forces the model to learn strong alignment and generate high quality token sequences eventually preventing it from reward hacking.MCTS (Monte Carlo Tree Search) : This serves as primary backbone of famous algorithms like AlphaGo. It utilizes a value model to evaluate each branch of sequence tree and then performs an aggregation to find the best possible trajectory/path to solution, but, training a value model in itself is really challenging, also token level assignment blows up the search space hence rendering the method unusable.

Typical state exploration in MCTS In paper MCTS is eventually replaced by rejection sampling through the R1 models intermediate RL checkpoints, this method is like selective sampling but your previous/lagged versions serve as value function.

Cost and compute optimization
Further for reducing the cost of training and optimizing the compute to best suit the model, the authors used following
1. Mixture of Experts (well known, during Inference only N/k params are active)
2. Multi-headed latent attention: instead of performing attention at token level, it is performed in much lower dimensional sub-space.
3. FP8 precision, leading to significant memory saving as compared to fp16 or fp32, it also significantly improved the time for matrix multiplication by around 4x against fp16.
Though these ideas/methods are pre-existing/not new, team at deepseek found a way to bring everything together and make it work in a profound manner, resulting in a accurate and scalable solution.
Outcome and results
Let's go through achievement of each step one-by-one
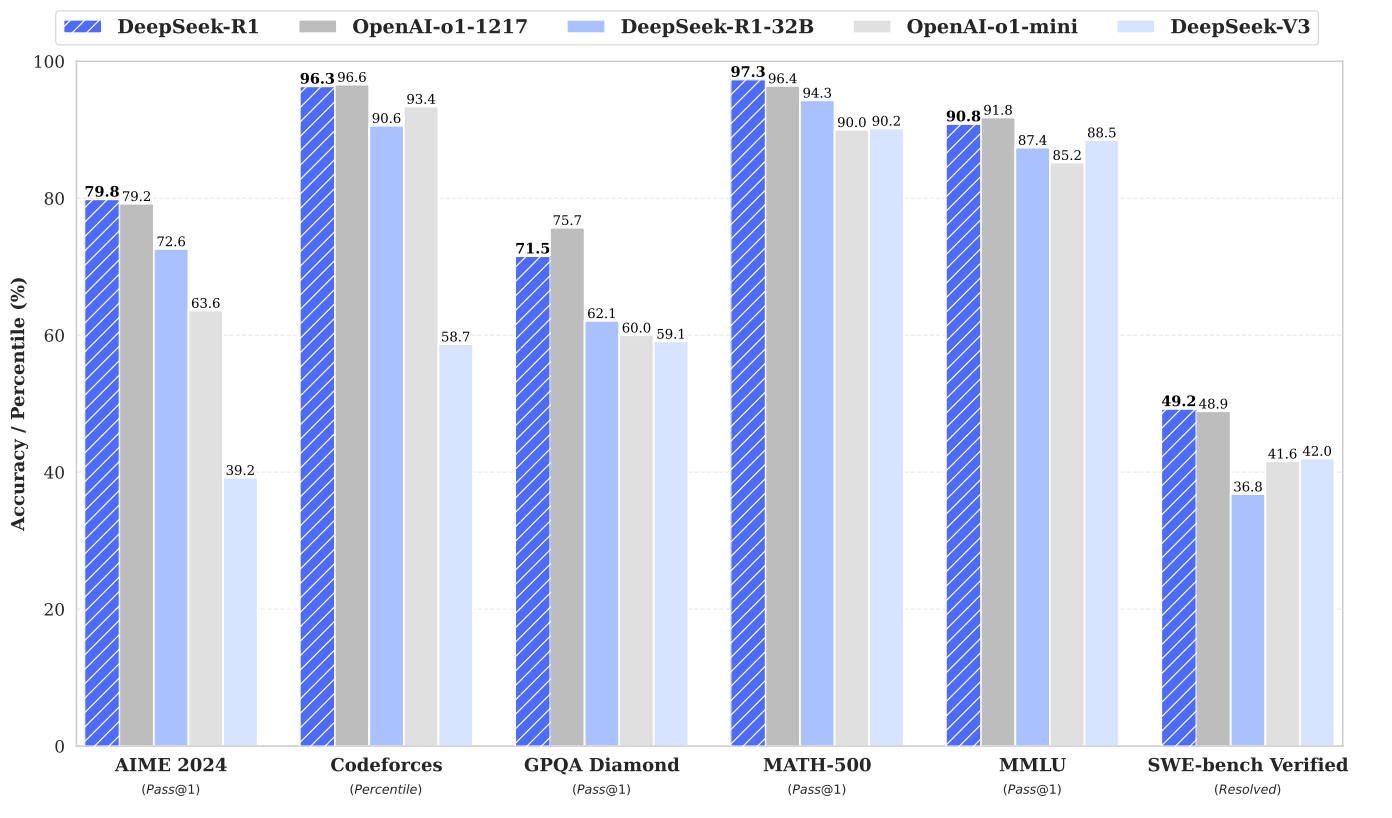
Deepseek-R1-zero
comparable results to O1 without any instruction tuning or fine-tuning on reasoning benchmarks.
Deepseek-R1
for reasoning tasks, R1 scores on par with OpenAI o1 on MATHS500, whereas beats O1 on AIME.
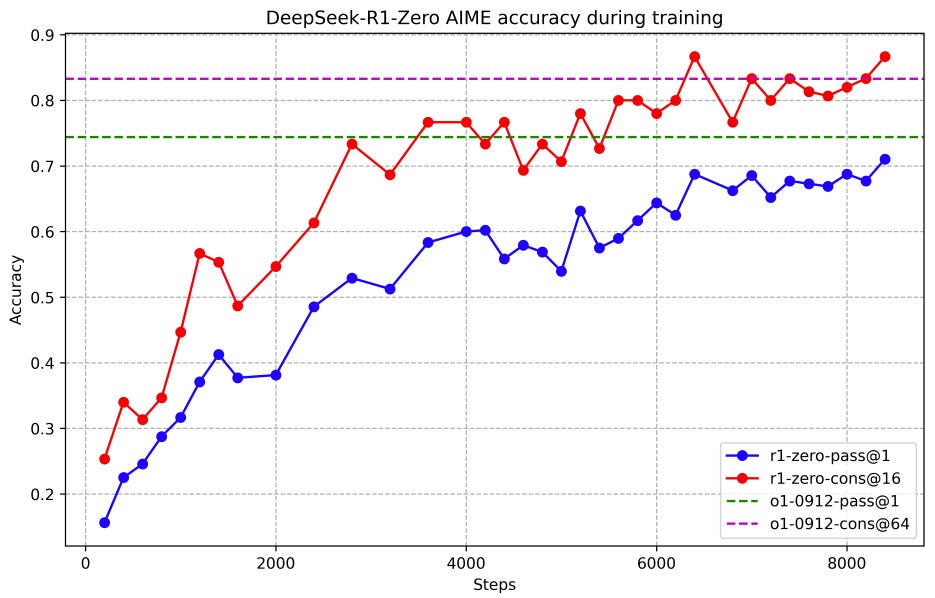
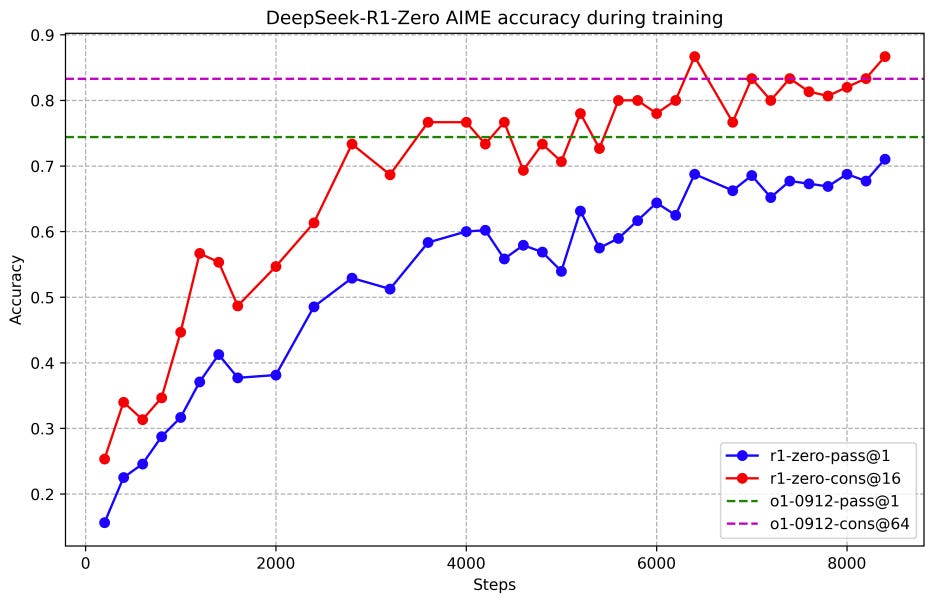
AIME accuracy of DeepSeek-R1-Zero during training. For each question, authors sample 16 responses and calculate the overall average accuracy to ensure a stable evaluation. for long-context understanding, R1 perform almost on-par with O1 again, while beating pervious DeepSeekv3 model on FRAMES and ArenaHard.
for general tasks, scores 92.3% on ArenaHard and 87.6% on AlpacaEval2.0, which is much more than any other open model out there.
Smaller tuned language models
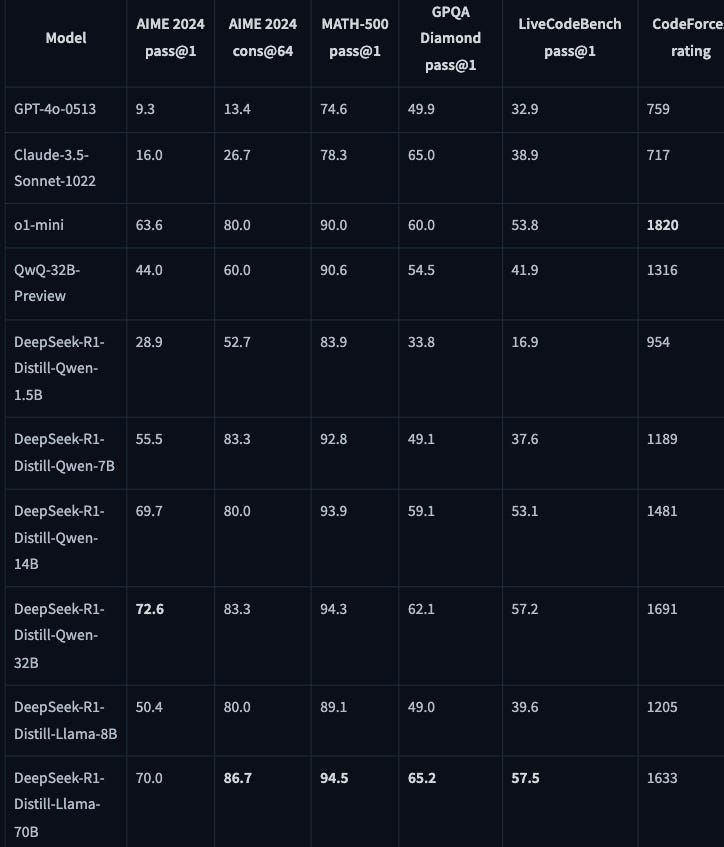
even the smaller tuned models outperformed much larger counterparts on coding and reasoning benchmarks.
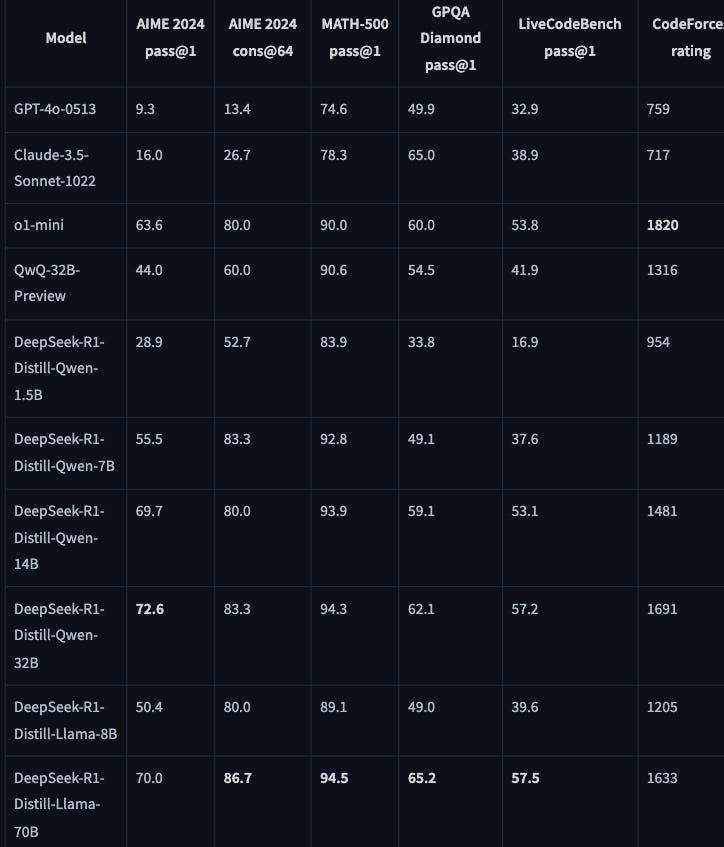
Performance of distilled modes from DeepSeek-R1
Thoughts
Though the authors were able to perform language alignment through language preference reward, yet there remains a significant room in terms of context alignment for other languages except English and Chinese.
Maybe a better moment chasing objective with GRPO to facilitate faster convergence.
Trying out more distillation techniques like Barlow twins, instead of conventional teacher-student structure.
Some work over format alignment and structuring is required, as the current method being rule-based restricts the formats across which model can generalize (some are relatively easier than others).
Some exploration in the step 1, where they had specialized prompt, instead of it being a two-way communication, can we make in N-way (like multiple users/agents).
Conclusion
Deepseek-R1-zero and R1 had been a big step up since the launch of llama and mistral. It would for sure serve as a milestone, not only in terms of innovation but also in reaffirming the possibility of sustainable development of such models without burning country size wealth and compute. Even the smaller models (especially the Qwen) are surprisingly good, which would eventually help in large scale adoption and usage of good quality models on local systems instead of wasting money over api calls, hence not only risking privacy but also the innovation (as it becomes the by-product of a closed model).
You can find more nuances and details in the paper 📄 here.
That's all for today.
We will be back with more useful articles, till then happy Learning. Bye👋