
Flash-KMeans: Fast and Memory-Efficient Exact K-Means
Scaling K-means on GPU is IO-bound; Flash-KMeans provides an efficient memory allocation level solution to reduce memory footprint and improve speed while maintaining an exact solution space.

Table of contents
Introduction
Parametric vs. Non-parametric methods
How exactly KNN works?
Problems with Memory Allocations and Speed
Why we need KNNs to work really fast? : (Spatial Partitioning: Voronoi and Delaunay, HNSW, From Hard-assignments to soft-assignments; from EM → VI)
The Ideal Case
Lloyd’s Algorithm and Standard GPU Implementation
Kernel-Level Bottlenecks
System-Level Constraints in Real Deployments
Methodology
FlashAssign: Materialization-Free Assignment via Online Argmin
Sort-Inverse Update: Low-Contention Centroid Aggregation
Efficient Algorithm-System Co-design
Results and Outcomes
Thoughts
Conclusion
Introduction
In the current landscape of Artificial Intelligence, the spotlight is almost exclusively held by Large Language Models (LLMs) and the generative magic they perform. However, the most sophisticated RAG (Retrieval-Augmented Generation) pipelines are only as good as their silent engine: the search and clustering layer.

Clustering isn’t just a classic data science task; it is the fundamental mechanism we use to organize high-dimensional vector spaces so that an LLM can find the right memory in a sea of billions of documents/Parameters. But as datasets scale, the standard algorithms we’ve relied on for decades are hitting a wall.
This article dives into Flash-KMeans, a recently proposed framework that challenges the status quo of GPU-accelerated clustering. Inspired by the Flash philosophy of minimizing data movement, this paper presents a way to perform exact K-Means that is both faster and significantly more memory-efficient than industry-standard implementations like FAISS. We aren’t just looking at an incremental speedup; we are looking at a fundamental shift in how we handle the materialization of data during the clustering process.
Parametric vs. Non-parametric methods
Before we dissect the mechanics of modern retrieval, we must ground ourselves in the fundamental divide of statistical learning: Parametric versus Non-parametric models.
Parametric Methods: These models assume that the underlying data follows a fixed functional form or distribution, defined by a finite set of parameters (e.g., Linear Regression or Logistic Regression). The complexity of the model is constant; it does not grow, regardless of how much data you throw at it.
Non-parametric Methods: Methods like K-Nearest Neighbors (KNN) make no such assumptions. The parameters are the data points themselves. Consequently, the model’s complexity and its ability to capture intricate, non-linear patterns grows as the dataset expands.
Intelligence as Symmetry and Compression
To understand why we obsess over these methods, we have to look at the very nature of intelligence. At its core, intelligence is the ability to find symmetry in chaos and compress information without losing its essence. Raw data is high-entropy and noisy. Intelligence functions by identifying recurring patterns/symmetries across different data points and mapping them to a unified concept. This is where clustering becomes indispensable. By grouping similar information together, we transform a massive, unmanageable dataset into a compressed set of representative centroids.
In a sense, every time we cluster, we are performing a form of lossy compression that retains the most vital semantic relationships. Without this ability to categorize and condense, a system would be forced to treat every new experience as a unique event, making generalized reasoning impossible. We cluster so that we can navigate the world through abstractions rather than raw bits.
How exactly KNN works?
To appreciate the optimizations in Flash-KMeans, we must first look at the raw mechanics of its precursor: the K-Nearest Neighbors (KNN) algorithm. While K-Means is an iterative clustering process, each iteration fundamentally relies on a nearest neighbor search to assign points to their closest centroids.
Algorithm:
The logic of KNN is mathematically elegant but computationally heavy. For every query point, the algorithm follows these steps:
 Algorithm - GeeksforGeeks")
Distance Computation: It calculates the distance (usually Euclidean or Cosine) between the query point and every single point in the dataset.
Sorting: It sorts these distances in ascending order.
Selection: It identifies the
Kpoints with the smallest distances.Decision: In classification, it takes a majority vote of those
Kneighbors; in clustering, it assigns the point to that specific neighborhood.
Time and Memory Complexity Analysis
In a research environment, we evaluate algorithms based on how they scale as data grows. Let N be the number of data points and D be the number of dimensions (features):

The Bottleneck: Because KNN is non-parametric, it doesn’t learn a simplified model; it searches therough the entire weight space of the dataset. At search time, calculating the distance to every point (O(N*D)) becomes a massive overhead.
The Materialization Problem: The memory complexity is equally daunting. To perform these calculations on a GPU, we traditionally materialize (store in memory) the intermediate distance matrices and cluster assignments. As N and D scale, we eventually run out of VRAM, leading to the crashes or slow-downs that Flash-KMeans aims to solve.
Problems with Memory Allocations and Speed
While the theory behind KNN and K-Means is robust, the implementation on modern hardware specifically GPUs hits a physical wall. In high-performance computing, we often find that the bottleneck isn’t the raw floating-point operations (FLOPs), but rather how the hardware manages the flow of data.
IO-Bound Bottleneck in Assignment
In the standard assignment stage, the GPU must calculate the distance between every data point and every centroid. Traditionally, this requires materializing a massive distance matrix in the GPU’s global memory.
The Problem: Global memory (VRAM) is significantly slower than the GPU’s on-chip SRAM.
The Impact: The system becomes IO-bound. The processing cores sit idle, waiting for the distance data to be moved from the slow VRAM to the fast SRAM. As K (number of clusters) or N (number of points) increases, the sheer volume of data movement chokes the throughput.
Atomic Write Contention in Update Stage
Once assignments are made, we must calculate the new centroids by averaging the coordinates of all points assigned to them.
The Problem: Multiple GPU threads, each processing a different data point, may attempt to update the same centroid simultaneously.
The Impact: This creates atomic write contention. To prevent data corruption, the hardware must serialize these writes, or use atomic add operations that become incredibly slow when hundreds of threads are fighting over the same memory address.
System-Level Constraints
Beyond the algorithm itself, we face hard system-level limits:
VRAM Ceiling: If your dataset or distance matrix exceeds the GPU’s memory (e.g., 80GB on an H100), the process fails entirely or relies on swapping to system RAM, which is orders of magnitude slower.
Latency in Real-Time Systems: In a production scenario such as a large-scale recommendation engine or an automated fraud detection system clustering needs to happen in milliseconds to be useful for real-time inference.
Why we need KNNs to work really fast?
In theory O(N*D) complexity is not a huge issue (at smaller scales). In production scenarios like high-frequency trading, real-time recommendation engines, or large-scale legal document analysis it is a catastrophic bottleneck. To understand why we are obsessed with optimizing this, we have to look at how we currently partition our data to make sense of it efficiently.
Spatial Partitioning: Voronoi and Delaunay

To avoid comparing a query to every single point, we could use geometric shortcuts to structure our search space:
Voronoi Diagrams: These partition the space into cells based on proximity to a set of seeds (centroids). Each cell contains all points closer to its seed than any other, allowing us to narrow our search region immediately.
Delaunay Triangulation: This is the dual of the Voronoi diagram. It connects centroids that share a boundary, forming a graph that allows us to hop from one region to another with mathematical efficiency.
In high-dimensional vector space, we organize data by partitioning it into “neighborhoods.” This is done through two intertwined structures:
Voronoi Diagrams (The Country Level): This represents node-level sovereignty. Each centroid (the “capital”) defines a boundary. If you are searching for a specific Name, you use the Voronoi partition. If your query falls within the boundaries of “France,” you have immediately narrowed your search to that specific node. You don’t need to look at the rest of the world.
Delaunay Triangulation (The Cuisine Level): This represents edge-level connectivity. These are the bridges between neighboring countries (features); could be anything like cuisine, favorite sport, GDP, etc. Let’s say; you are already at the “France” node but your query is about “Mediterranean Pasta,” the Voronoi boundaries alone won’t help you move. You look at the Edges. Since France and Italy share a boundary, they share a Delaunay edge which could be a shared feature like Cuisine.
The power of the dual system lies in the Next Hop logic:
You use the Voronoi cell to find where you are currently standing (e.g., France).
To find a more relevant result, you use Delaunay to see where you can go. If the “Expected Condition” of your search is “Food,” the edge leads you to Italy.
You bypass “Germany” because, while it is a neighbor, it doesn’t share that specific “Cuisine” edge.
In the standard K-Means algorithm, every iteration relies on this Voronoi logic to function. During the Assignment Phase, the algorithm must determine which “Country” (Voronoi cell) every single data point belongs to.
If you have a billion points and 10,000 centroids, the algorithm has to measure the distance from every point to every capital city. This creates the massive O(N*K) computational tax. Standard K-Means is essentially the process of redrawing these “Country” borders (Voronoi cells) over and over again until the capitals (centroids) are perfectly centered within their respective territories.
The Core of Retrieval: HNSW

Modern vector databases rely on Hierarchical Navigable Small Worlds (HNSW) to perform approximate nearest neighbor search.
Think of HNSW as a multi-layered graph which is a skip-list for high-dimensional space.
The top layers have fewer points and long-range connections for fast traversal, while lower layers provide fine-grained density.
At every layer, the algorithm performs a local KNN search to find the next entry point. If the underlying KNN is slow, the entire graph traversal lags; hence the entire retrieval component of RAG suffers.
From Determinism to Variational Inference
KNNs as methodology are simply a discretized variant of Variational Inference:
KNN is Deterministic (Hard Bounded); hence a point belongs to a cluster or it doesn’t; it is a rigid geometric assignment.
On the other hand; GMMs are Probabilistic (Soft Bounded). This means Gaussian Mixture Models represent the world as overlapping distributions where a point has a probability of belonging to multiple clusters. GMMs are optimized via algorithm called as Expectation-Maximization (EM).
EM is essentially a discretized, specific version of Variational Inference (VI).

Since VI is the mathematical heart of nearly all generative models (including VAEs and the loss functions of modern LLMs), a simple K-Means assignment is actually a simplified, hard version of the complex probabilistic reasoning used in the most advanced AI today. We need KNN to be fast because it is the fundamental base case for understanding how information is distributed.
The Ideal Case
To design a superior system, we must first understand exactly where the standard implementations fail. Standard GPU-accelerated K-Means which are utilized in libraries like FAISS or scikit-learn is built on Lloyd’s Algorithm, which iterates through two distinct phases: Assignment and Update.
3.1 Lloyd’s Algorithm and Standard GPU Implementation
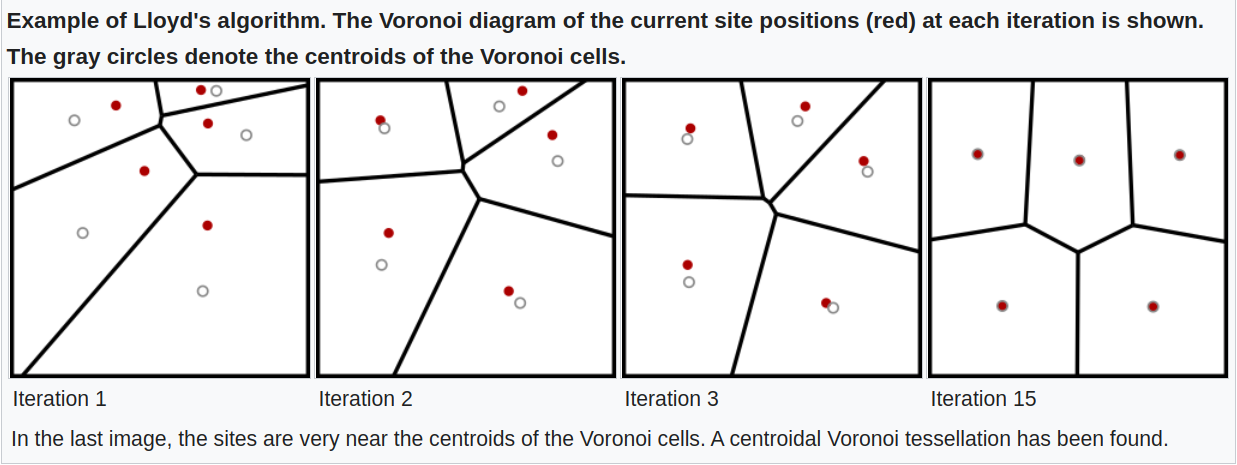
Assignment Phase: Each data point is compared against all
Kcentroids to find the nearest neighbor using a distance metric (typically Euclidean distance).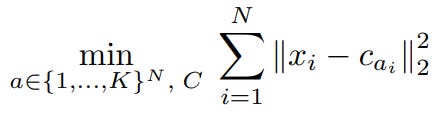
Update Phase: Centroids are recalculated by taking the mean of all data points assigned to them.
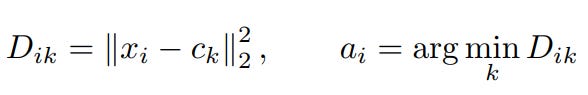
Data Materialization: In standard implementations, the GPU materializes (writes to global memory) a large assignment vector to track which point belongs to which cluster.
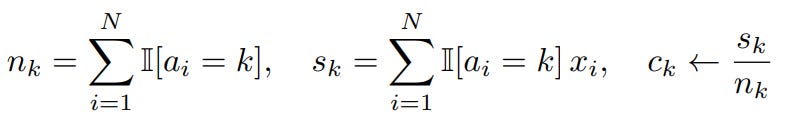
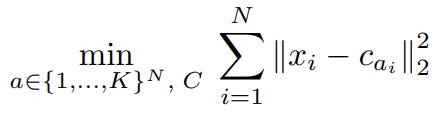
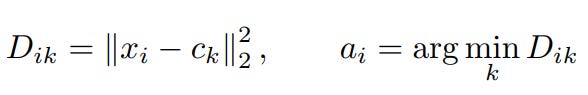
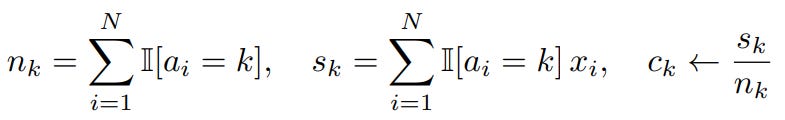
Does this sound familiar? Yes, this is exactly how Kmeans is performed right now. Modern day implementation of Kmeans is written using Lloyds algorithm; which doesn’t scale very well with GPUs.
Kernel-Level Bottlenecks
Here the Ideal Case remains out of reach for standard implementations due to two primary kernel-level issues:
Memory Bandwidth (The IO Wall): The assignment phase is inherently IO-bound. Standard implementations spend more time moving distance data from slow VRAM to the GPU cores than actually performing the calculations.
Atomic Write Contention: During the update phase, multiple threads processing different data points often attempt to update the same centroid at the same time (example atomic_add in algo). This forces the hardware to serialize these writes, creating a massive queue that stalls the entire pipeline.


System-Level Constraints in Real Deployments
In real-world scenarios, these bottlenecks manifest as hard limits on scalability:
Excessive VRAM Usage: The need to store large intermediate assignment matrices means that as
Kincreases, the memory footprint grows linearly, often exceeding the 80GB limit of even top-tier A100 or H100 GPUs.Low Compute Utilization: Because the system is stuck waiting for memory IO, the high-performance Tensor Cores or CUDA cores sit underutilized, leading to inefficient bubbles in the execution timeline.
An Ideal implementation would avoid writing intermediate assignments to global memory entirely. It would keep data in the fastest possible memory tier which is the on-chip SRAM and only commit the final, aggregated results to the main memory.
To bridge this gap, we must move away from generic, off-the-shelf clustering libraries and toward a system-level co-design ones. This means rewriting the very kernels of the algorithm to respect the physical hierarchy of silicon prioritizing on-chip speed over global capacity. In the next section, we see how Flash-KMeans achieves this by introducing two key architectural innovations that turn these hardware bottlenecks into parallelized strengths.
Methodology
The innovation of Flash-KMeans lies in its Algorithm-System Co-design, which re-engineers the execution flow of the K-Means algorithm to bypass the physical limitations of GPU hardware. The framework introduces two pivotal components: FlashAssign and Sort-Inverse Update, along with system-level optimizations for real-world deployment. Let’s go through each component one-by-one as referenced in paper.
1. FlashAssign: Materialization-Free Assignment via Online Argmin
To address the severe High Bandwidth Memory (HBM) traffic overhead identified in traditional implementations; specifically the IO wall caused by materializing a massive N*K distance matrix, the paper introduces FlashAssign. FlashAssign fuses distance computation and reduction into a single streaming procedure, ensuring the full distance matrix is never explicitly constructed in memory.
Online Argmin
The heart of FlashAssign is the online argmin update. Traditionally, a GPU would calculate all distances, store them, and then find the minimum. FlashAssign flips this:
Running States: For each data point x_i, the kernel maintains only two running states in local registers: the current minimum distance (m_i) and the corresponding centroid index (a_i).
Tile-Based Scanning: Centroids are scanned in tiles. For each tile, the kernel computes local distances on-chip, finds the local minimum within that tile, and compares it with the running (m_i, a_i).
Registers over HBM: By repeating this over all centroid tiles, the global minimum is identified entirely on-chip, using registers instead of global memory.
Latency Hiding: Tiling and Asynchronous Prefetch
To ensure the GPU cores are never idling for data, FlashAssign employs a two-dimensional tiling strategy over both points and centroids.
Double Buffering: The implementation uses a double-buffer pattern.
Overlap: While the GPU is busy computing distances for the current centroid tile (t), it asynchronously prefetches the next tile (t+1) from HBM into the alternate on-chip buffer. This overlaps memory latency with computation, keeping the throughput high.
Algorithm Breakdown
The process follows a strict streaming logic:

Initialize: Initialize on-chip states to m = +infinity and precompute norms.
Streaming Loop: Scan through centroid tiles sequentially.
Compute and Update: Calculate local distances on-chip, compute tile-local minima, and update the global running state via the online argmin logic.
Final Write: Once all centroids are processed, only the final assignment a is written to HBM.
By fusing these steps, FlashAssign fundamentally alters the dataflow. It reduces the dominant IO complexity from O(NK) to O(Nd + Kd), effectively removing the 2*Θ(NK)$ HBM traffic penalty that plagues standard FAISS-style implementations
2. Sort-Inverse Update: Low-Contention Centroid Aggregation
To resolve the severe write-side serialization that occurs in the centroid update stage, the paper proposes the Sort-Inverse Update. Traditional implementations use a scatter-style update where tokens are directly scattered to their assigned centroids, leading to high atomic contention when multiple threads update the same centroid simultaneously.
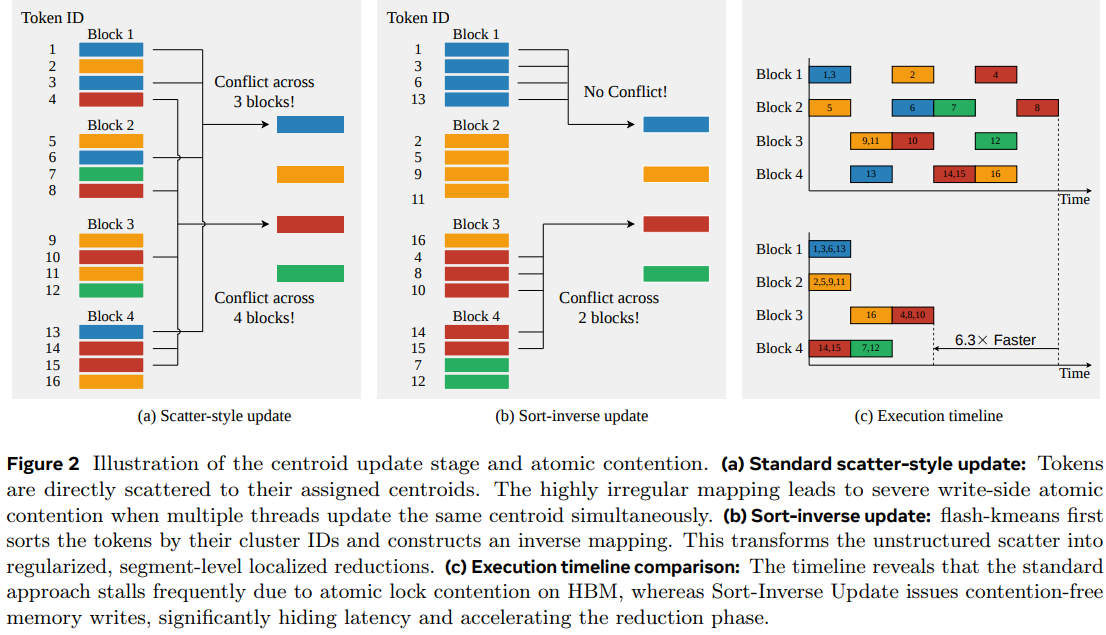
The Core Innovation: Explicit Inverse Mapping
Instead of struggling with irregular mappings, Flash-KMeans transforms the token-to-cluster update into a cluster-to-token gather.
Argsort Operation: The framework first applies an
argsortto the assignment vectorato obtain a permutation index,sorted_idx.Logical Grouping: This creates a sorted cluster-ID sequence where identical cluster IDs are naturally grouped into contiguous segments.
Memory Efficiency: Crucially, this sorting is only performed on the 1D assignment vector; the heavy point matrix X is never physically permuted in memory.
Segment-Level Localized Aggregation
Once the inverse mapping is constructed, the actual reduction moves from global memory to the GPU’s fast on-chip memory.
On-Chip Accumulation: Each thread block (CTA) processes a contiguous chunk of the sorted sequence and identifies segment boundaries.
Localized Reduction: Partial sums and counts are accumulated entirely in registers or shared memory for each segment.
Bypassing the Bottleneck: The CTA only issues global
atomic_addoperations to HBM at segment boundaries rather than for every token.
Complexity and Contention Analysis
This reorganization drastically reduces the number of atomic operations required.
Reduction in Atomics: In a standard update, atomics scale as O(Nd).
Optimization Scale: In the Sort-Inverse design, the number of atomic merges drops to:
\(O((K + \lceil N/B_N \rceil)d)\)Result: This theoretical reduction directly translates to the elimination of write contention, allowing for contention-free memory writes that hide latency and accelerate the reduction phase.
Algorithm Breakdown

Sort: Compute
sorted_idxviaargsort(a)and construct sorted cluster IDs.Initialize: Set centroid sums (s) and counts (n) to zero.
Identify Segments: Iterate through chunks of the sorted sequence to find contiguous identical cluster IDs.
Gather & Accumulate: Gather token features from the original order and accumulate local partial sums and counts on-chip.
Atomic Merge: Issue a single
atomic_addto HBM per segment boundary.Final Update: Recalculate centroids as c_k = s_k / n_k.
3. Efficient Algorithm-System Co-design
The final layer of the methodology focuses on deployability. High-performance kernels are useless if they cannot scale beyond a single GPU’s memory or if they require hours of tuning every time the data shape changes. The paper addresses these practical hurdles through two co-design strategies.
Large-Scale Data Processing via Chunked Stream Overlap
In real-world systems, datasets often exceed the available VRAM. To handle this, Flash-KMeans uses a streaming pattern to stage data from the CPU (Host) to the GPU (Device):
Asynchronous Transfers: The data is partitioned into chunks.
Stream Coordination: Using CUDA streams, the system copies one chunk to the GPU while the previous chunk is being processed by the assignment and update kernels.
Double-Buffering: This ensures that the PCIe bus and the GPU cores are active simultaneously, hiding the latency of moving data from system RAM to the GPU.
Cache-Aware Compile Heuristic
One of the biggest hidden costs in high-performance ML is compilation time. Different data shapes (different N, D, or K) usually require exhaustive auto-tuning to find the best kernel configurations.
Instead of exhaustive searching, Flash-KMeans uses a cache-aware heuristic that directly selects configurations based on the hardware’s physical characteristics (specifically the L1 and L2 cache sizes).
Fast Time-to-First-Run: This approach allows the system to match near-best performance levels almost instantly, even when deployed across different hardware architectures or with dynamic data shapes.
Thanks to all the optimization in centroid allocations and chunking; we arrive at Flash-Kmeans; now let’s have a look at the outcome of the entire development.
Results and Outcomes
The performance of Flash-KMeans is evaluated against industry-standard baselines, primarily FAISS, which is widely regarded as the state-of-the-art for GPU-accelerated vector search and clustering. The results demonstrate that by solving the IO and contention bottlenecks, Flash-KMeans redefines the efficiency frontier for exact K-Means. The setup for evaluation/benchmarking is NVIDIA H200 (80GB) GPU, focusing on both execution speed and memory footprint.
End-to-End Speedup
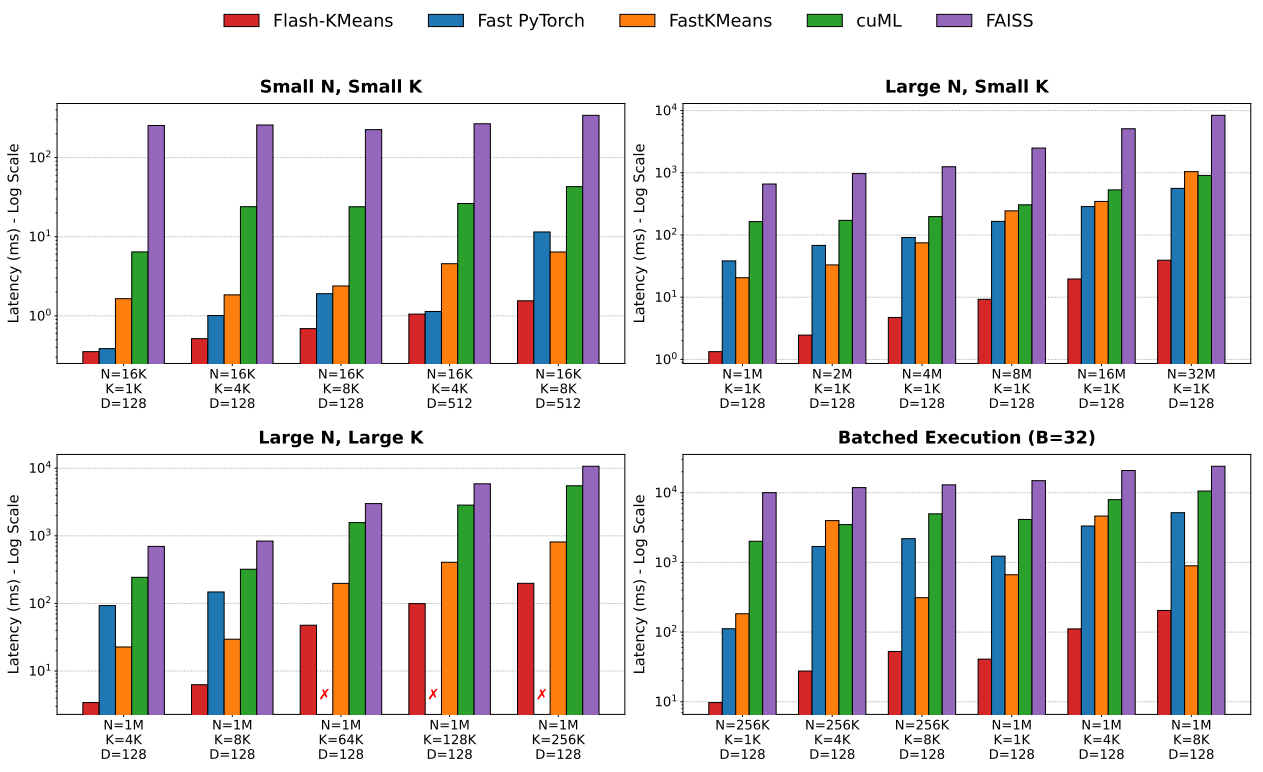
To understand the real-world impact of the framework, we examine three representative regimes that typically haunt GPU implementations:
Large N with Large K (Memory-Intensive): This is the “OOM” (Out-Of-Memory) danger zone. For a workload of N=1 M, K=64K, standard PyTorch implementations fail entirely as they attempt to materialize the massive distance matrix. Flash-KMeans, however, achieves its most dominant absolute speedup here, outperforming the best alternative (fastkmeans) by over 5.4×.
Large N with Small K (Compute-Intensive): When searching across massive datasets (N=8M), the latency is usually dominated by raw distance calculations. Flash-KMeans reduces this end-to-end latency by 94.4%, representing a staggering 17.9× speedup over traditional implementations.
Small N with Small K (Framework Overhead): Even in smaller, highly batched scenarios (B=32) where framework and kernel launch overheads usually obscure algorithmic gains, Flash-KMeans remains robust, delivering consistent acceleration and up to a 15.3× speedup.
Kernel-Level Efficiency
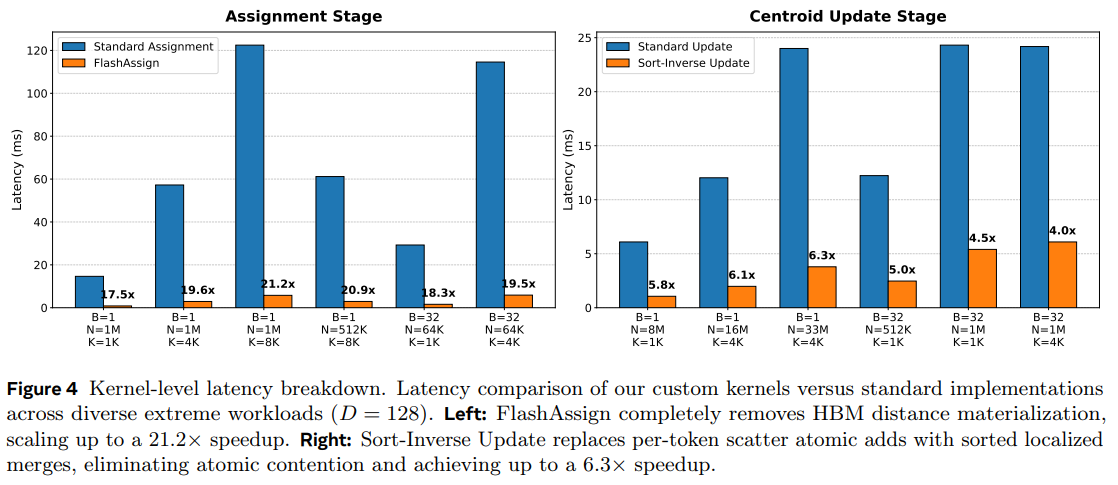
To verify that the acceleration stems from neutralizing specific hardware bottlenecks, we look at the individual performance of the two core stages:
FlashAssign (Assignment Stage): In highly demanding configurations (N=1M, K=8192), FlashAssign drastically slashes execution time from 122.5ms to just 5.8ms. This 21.2× speedup over standard assignment methods confirms that the materialization-free, online argmin approach effectively bypasses the High Bandwidth Memory (HBM) traffic penalty.
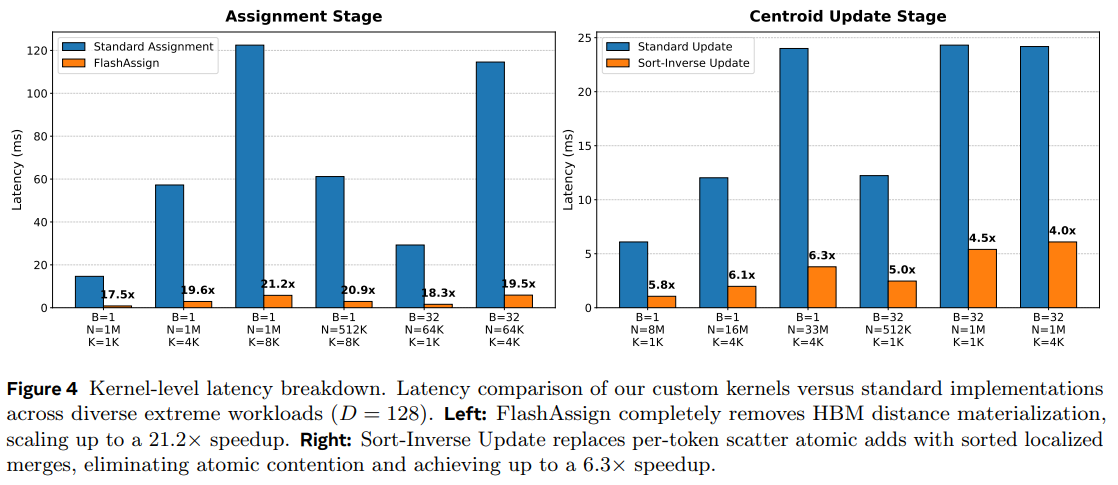
Sort-Inverse Update (Reduction Stage): Simultaneously, the sort-inverse update systematically accelerates the centroid calculation. On massive-scale workloads (N=33M), it achieves up to a 6.3× speedup by transforming unstructured, high-contention atomic scatters into regularized, segment-level reductions.
Large-Scale Out-of-Core Processing
To test the limits, the researchers benchmarked workloads where the dataset severely exceeds the GPU’s VRAM capacity, scaling up to one billion points.
The “Billion-Point” Benchmark: On an extreme workload (N=10^9, K=32768), standard PyTorch implementations immediately crash due to OOM errors. Flash-KMeans, however, completes an iteration in just 41.4 seconds compared to 261.8 seconds for the most robust baseline (fastkmeans).
Speedup at Scale: This represents a 6.3× to 10.5× end-to-end speedup in massive-scale scenarios. It proves that the framework’s pipelined execution successfully bounds the peak memory footprint while delivering order-of-magnitude acceleration for data that “doesn’t fit” on the card.
Fast Time-to-First-Run
One of the “hidden” costs of high-performance ML is the time spent on exhaustive “auto-tuning” to find the best kernel configurations for a specific data shape.
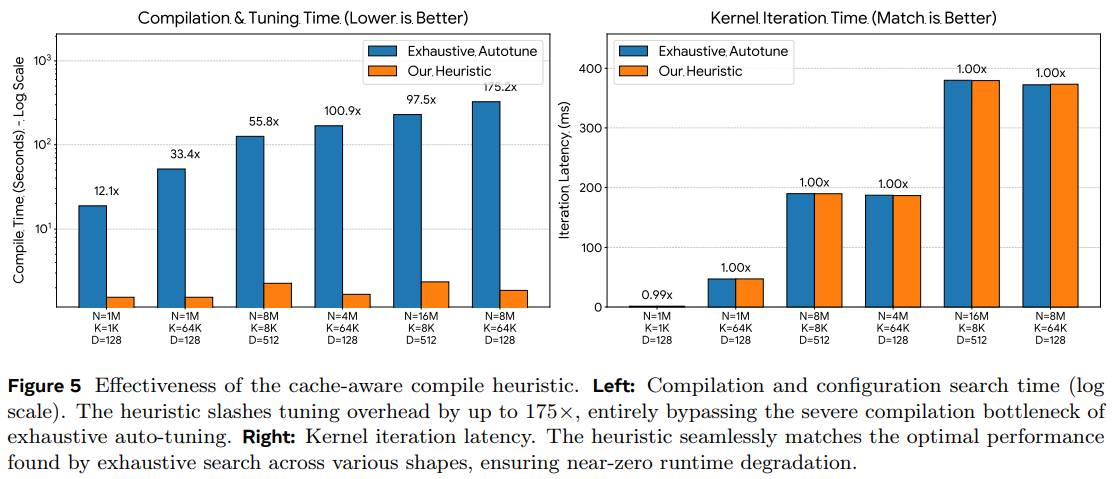
Heuristic vs. Exhaustive: In massive shapes (N=8M, K=64K), exhaustive tuning takes over 325 seconds to find an optimal configuration. The cache-aware compile heuristic analytically derives a near-perfect configuration in less than 2.5 seconds.
175× Faster Setup: This results in up to a 175× reduction in time-to-first-run.
Zero Performance Degradation: Most importantly, the heuristic matches the optimal performance of the “exhaustive oracle” within a 0.3% margin. You get the best possible speed without the minutes-long wait before the first iteration begins.
Quality vs. Speedup
A critical takeaway is that these speedups do not come at the cost of accuracy. Unlike approximate methods (like Product Quantization) that trade precision for time, Flash-KMeans remains mathematically exact. The 12.5× average speedup isn’t achieved by cutting corners in the math, but by cutting the IO overhead. It is a rare “free lunch”: you get the same mathematical convergence as Lloyd’s algorithm, just significantly faster and within a fraction of the memory footprint.
These experiments proves Flash-KMeans as the first exact K-Means implementation that can scale to very large K values on a single GPU while maintaining peak hardware efficiency. It effectively turns the memory-intensive task of clustering into a compute-bound streaming process.
Thoughts
Just as FlashAttention revolutionized LLMs by respecting the GPU memory hierarchy, Flash-KMeans proves that we are in a new era of algorithm design where FLOPS are cheap but memory movement is the true tax.
I find the move from “scatter-style” updates to “cluster-to-token gather” particularly brilliant. Instead of fighting hardware-level atomic contention in parallel programming the authors restructured the logic to align with the silicon’s physical strengths.
Unlike many speed-focused implementations that rely on approximations (like product quantization) to trade accuracy for time, Flash-KMeans is an exact implementation of Lloyd’s algorithm. You get a 12.5× speedup with zero loss in mathematical fidelity.
While Flash-KMeans excels at exact clustering, the next logical step is a deeper co-design with approximate structures like HNSW. Implementing a "Flash-HNSW" that uses materialization-free kernels for local neighborhood exploration could drastically reduce the memory overhead of maintaining large, multi-layered navigation graphs
This framework essentially kills the O(NK) HBM traffic penalty. By treating the GPU as a specialized stream processor rather than a simple memory buffer, it turns what used to be an “IO-bound” bottleneck into a “compute-bound” strength.
Dynamic K and Adaptive Tiling: The current implementation relies on a cache-aware heuristic to select tile sizes (B_N, B_K) based on static hardware profiles. A potential improvement would be a runtime-adaptive tiling mechanism that can dynamically adjust these sizes mid-iteration to account for varying cluster densities or fluctuating GPU compute availability.
The current work focuses heavily on single-GPU efficiency. Extending the Sort-Inverse Update logic to a distributed multi-GPU setting where cluster segments are partitioned across high-speed interconnects like NVLink would allow for the exact clustering of truly massive, petabyte-scale datasets that even a single A100 cannot hold.
Conclusion
Flash-KMeans reframes clustering as a function of streaming efficiency rather than static memory capacity. By abandoning the materialization-heavy orthodoxy of traditional GPU implementations and treating the algorithm as an integrated co-design of silicon and logic, we move closer to a machine that doesn’t just store data, but respects the physical hierarchy of the hardware it inhabits.
In this article, we started by exploring the Information Hypothesis, seeing how intelligence arises from identifying the low-dimensional symmetries in high-dimensional data. We established the Parametric vs. Non-parametric divide and revisited the Theoretical Bridge between deterministic KNNs and the probabilistic world of Variational Inference, framing K-Means as the atomic unit of information organization.
We then identified the IO-bound bottlenecks and atomic write contentions that have historically acted as an architectural ceiling for standard libraries like FAISS. We explored the Methodology of Flash-KMeans, seeing how it realizes an “Ideal Case” through FlashAssign (which replaces the O(NK) memory tax with a materialization-free Online Argmin) and the Sort-Inverse Update, which transforms unstructured scatter into regularized, segment-level reductions. Finally, we saw results that showed that an exact implementation of Lloyd’s algorithm delivering a 12.5x speedup, proving that Memory Efficiency is the true frontier of scaling in a world where compute is cheap but bandwidth is the bottleneck.
The key takeaway is that the Materialization Tax of traditional clustering (the need to externalize every intermediate distance into slow global memory) is an inefficiency we can finally bypass. When we decouple Centroid Calculation from HBM Traffic, we don’t just get faster tools; we get a new class of high-performance algorithms that stop fighting the silicon and start modeling the structural symmetry of the data itself.
Paper : https://arxiv.org/pdf/2603.09229
That's all for today.
Follow me on LinkedIn and Substack for more such posts and recommendations, till then happy Learning. Bye👋