
How does Group Relative Policy Optimization (GRPO) exactly work?
Why did GRPO become the most popular Reinforcement Learning algorithm for reasoning models?

Reinforcement learning systems typically involve an agent-environment interface.
The agent is the entity whom we want to teach something. This could be a “master chess player” making a move, a “gazelle” learning to run, a mobile house cleaning “robot” making decisions or “you” eating breakfast.
In all these examples, the agent is interacting with the environment which takes the form of a chess board, nature, room or our internal state of mind. The goal of the agent is to achieve a reward, which for the above examples would be winning the chess game, running fast, collecting maximum amount of trash and obtaining nourishment.
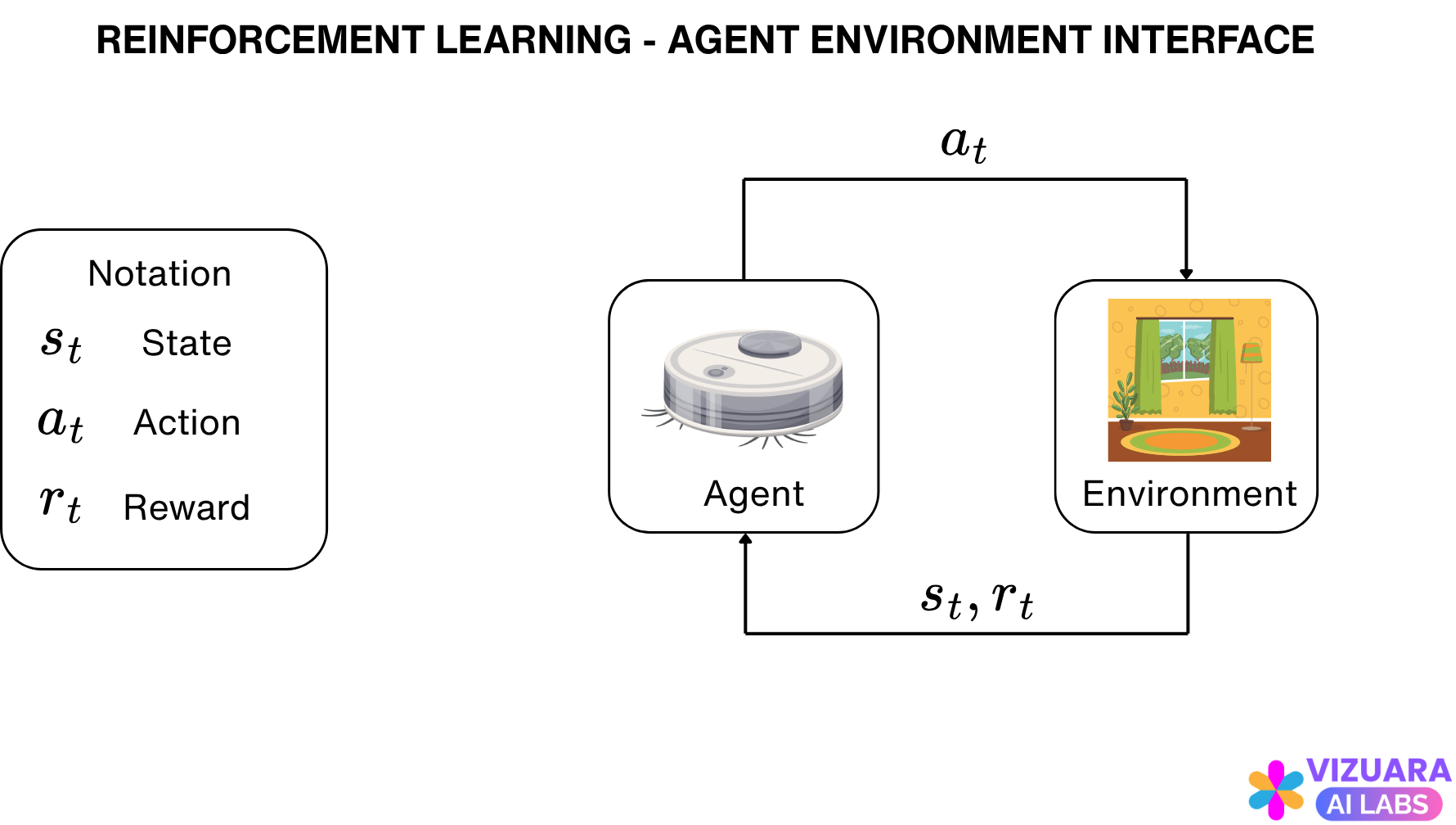
While the agent interacts with the environment, at each time step, it receives information of the state of the environment. Based on the state, the agent takes an action and receives a reward.
The goal of all reinforcement learning problems is to help the agent choose actions in such a way that the total cumulative rewards received by the agent is maximized.
The decision of choosing an appropriate action at each state is taken with the help of the agent’s policy.
Question 1: How do we apply Reinforcement Learning in Large Language Models?
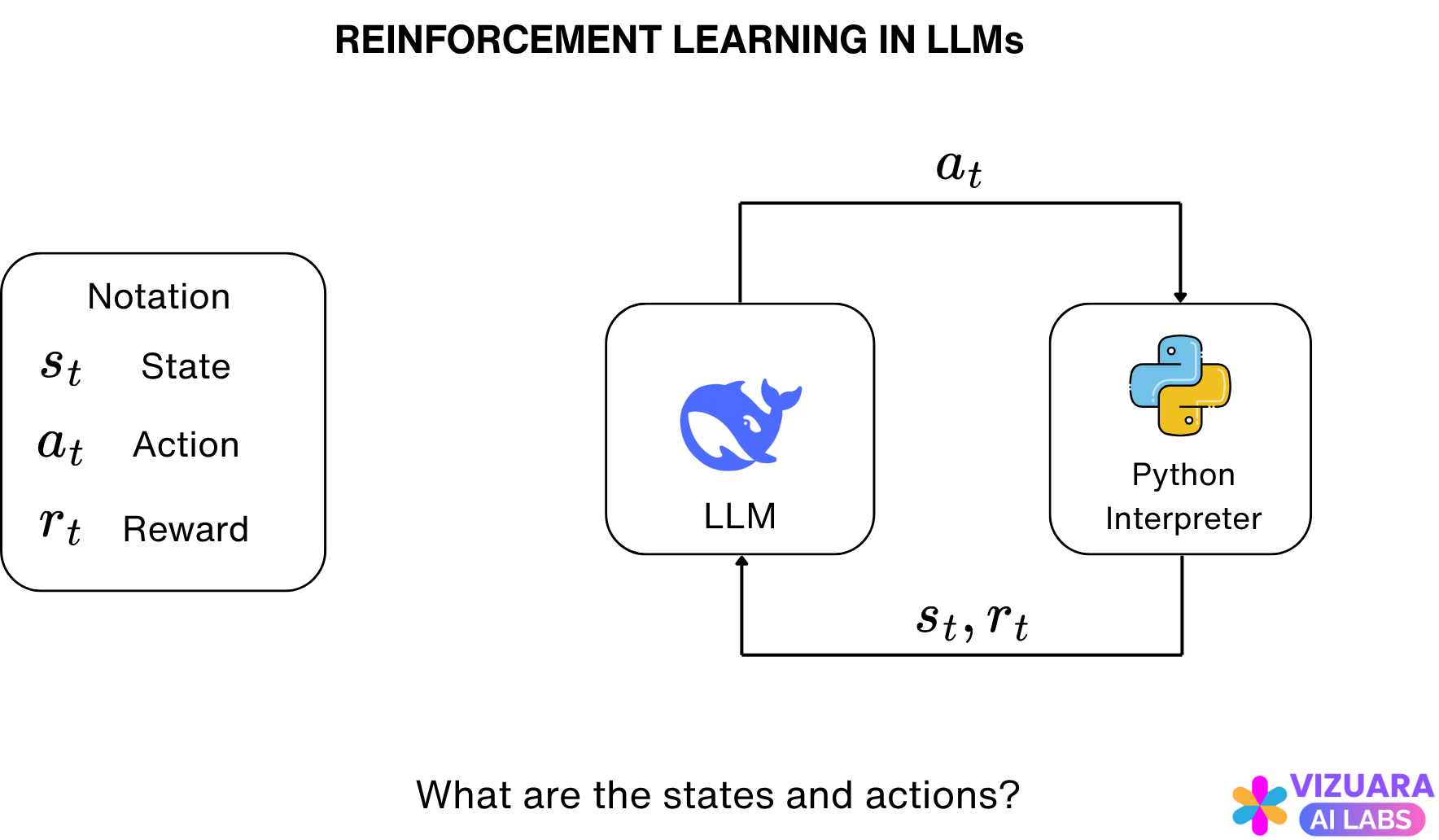
If one attempts to formulate LLMs in terms of an agent-environment interface, it does not seem straightforward.
To answer this question, let us first understand what does an LLM actually do.
LLMs are trained on huge amounts of data to predict the next word or sequence of words.
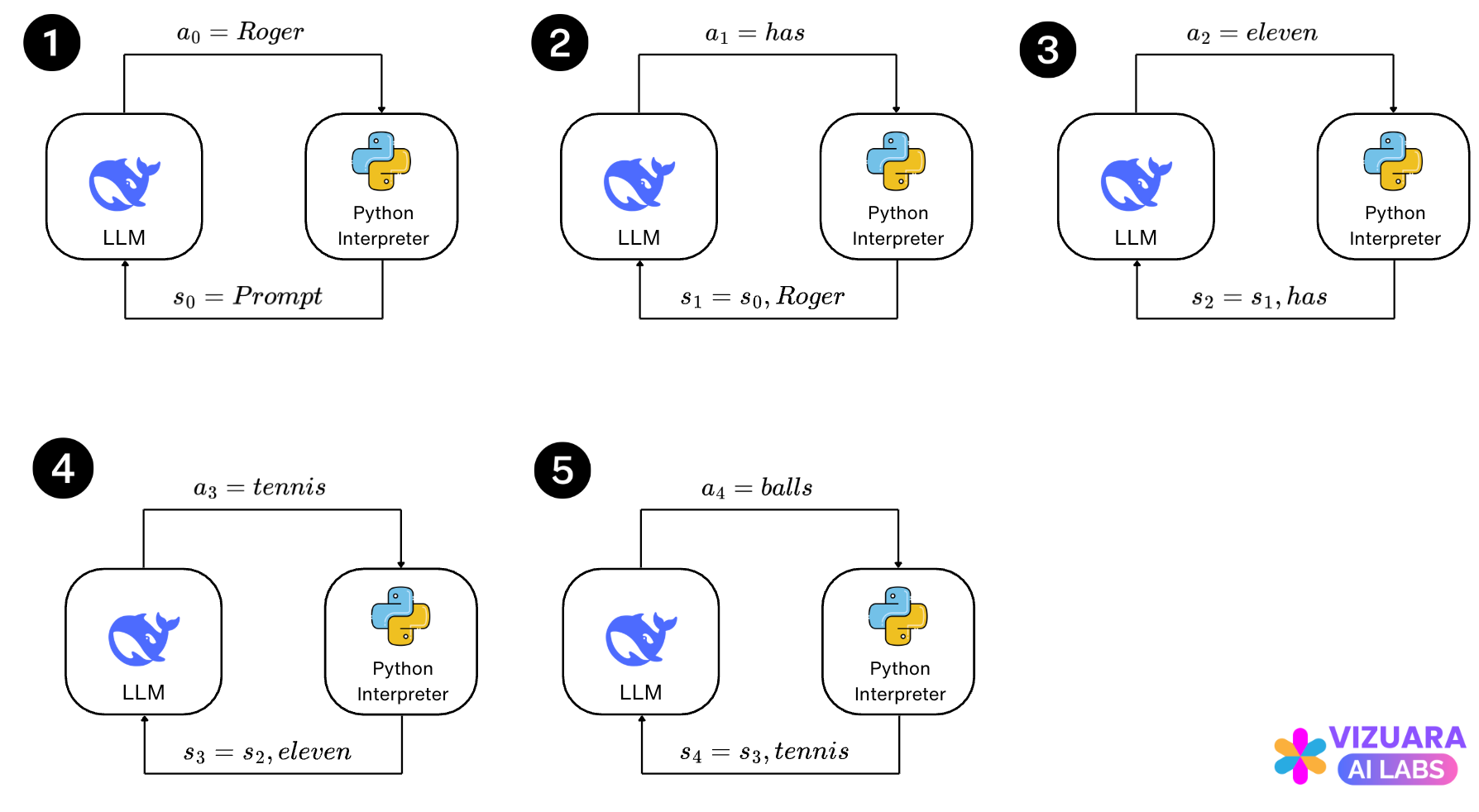
What if we think of the LLM as the agent and the next word prediction as the action taken by this agent? So, the states would be the prompt given by the user and the previous set of words predicted by the LLM.
Okay, let us take an example to clarify this:
The user types the following prompt:
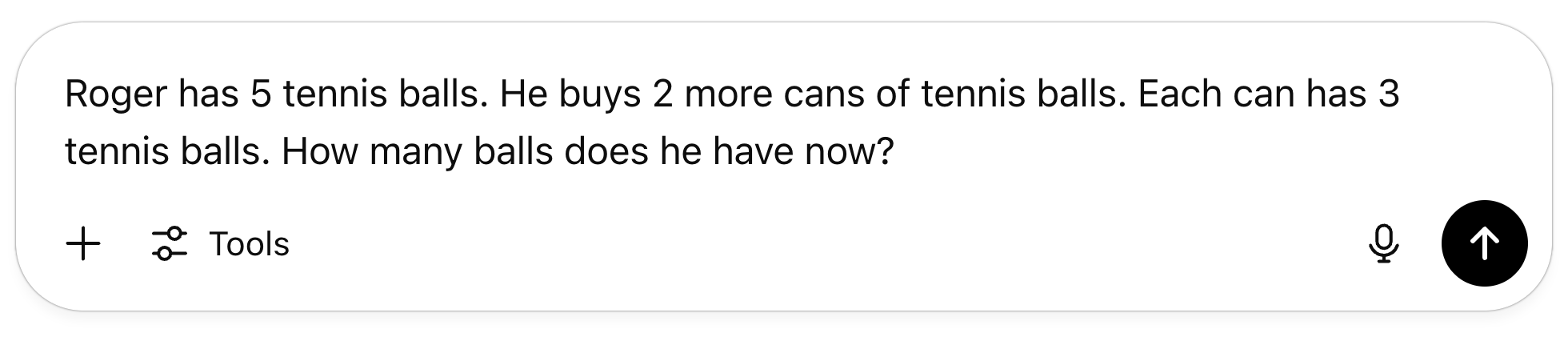
The LLM gives this answer:
“Roger has 11 tennis balls”
Now, let us understand the states and the actions:
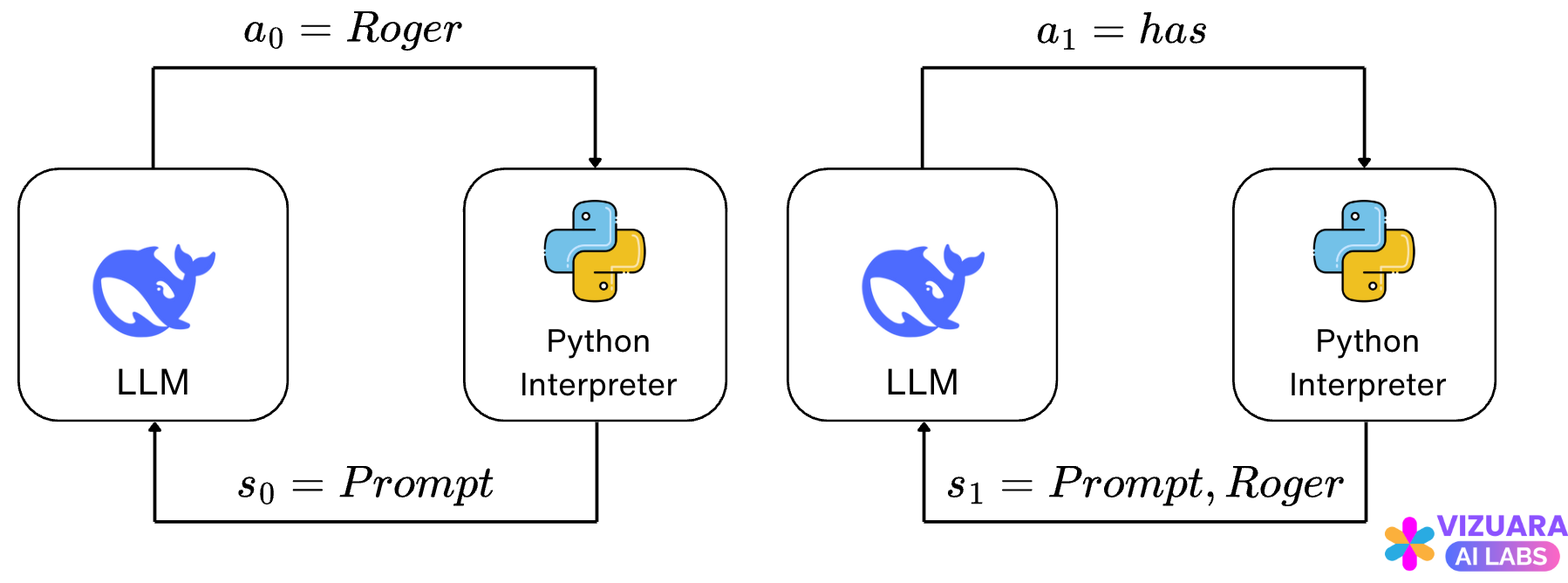
The action is the next word predicted by the LLM and the state is the combination of the user prompt and the previous words predicted by the LLM.
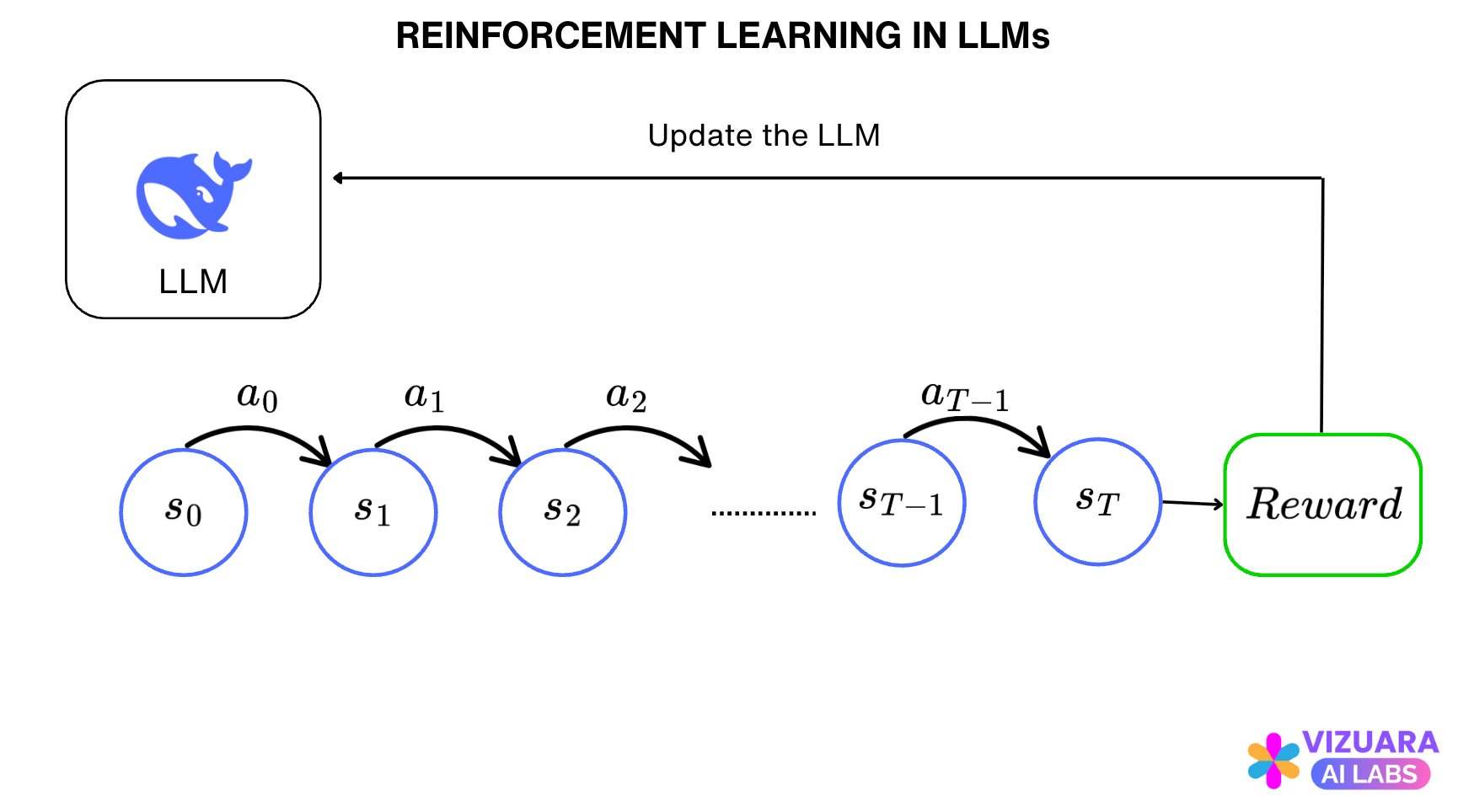
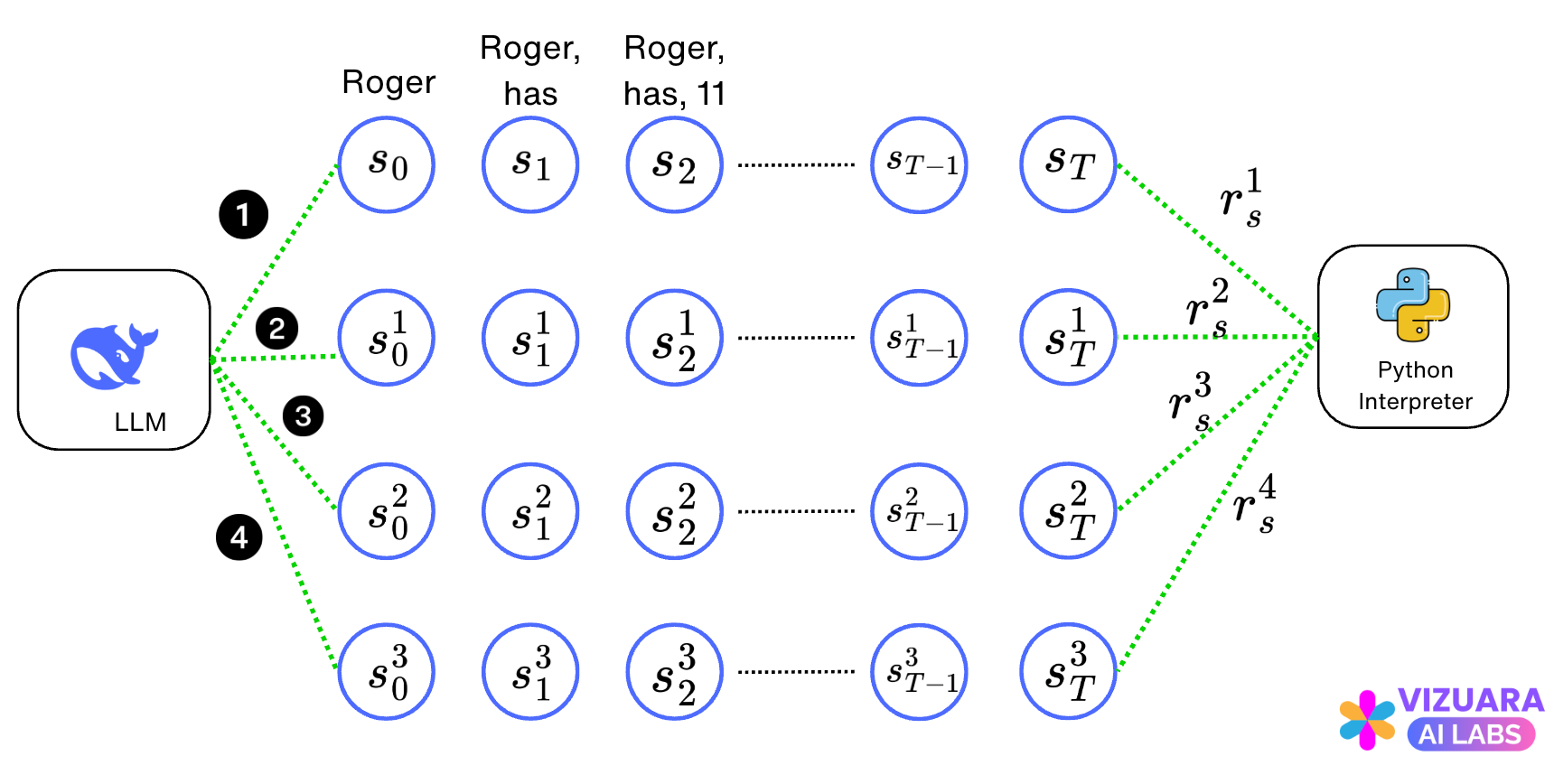
The agent-environment interface for all states and actions now looks like this:
Next, we turn to rewards.
Reinforcement Learning in LLMs differs from other applications, mainly because the reward is only received at the end of the sentence or thought completion.
In our example, the reward is positive if the answer is correct, else the reward is zero.
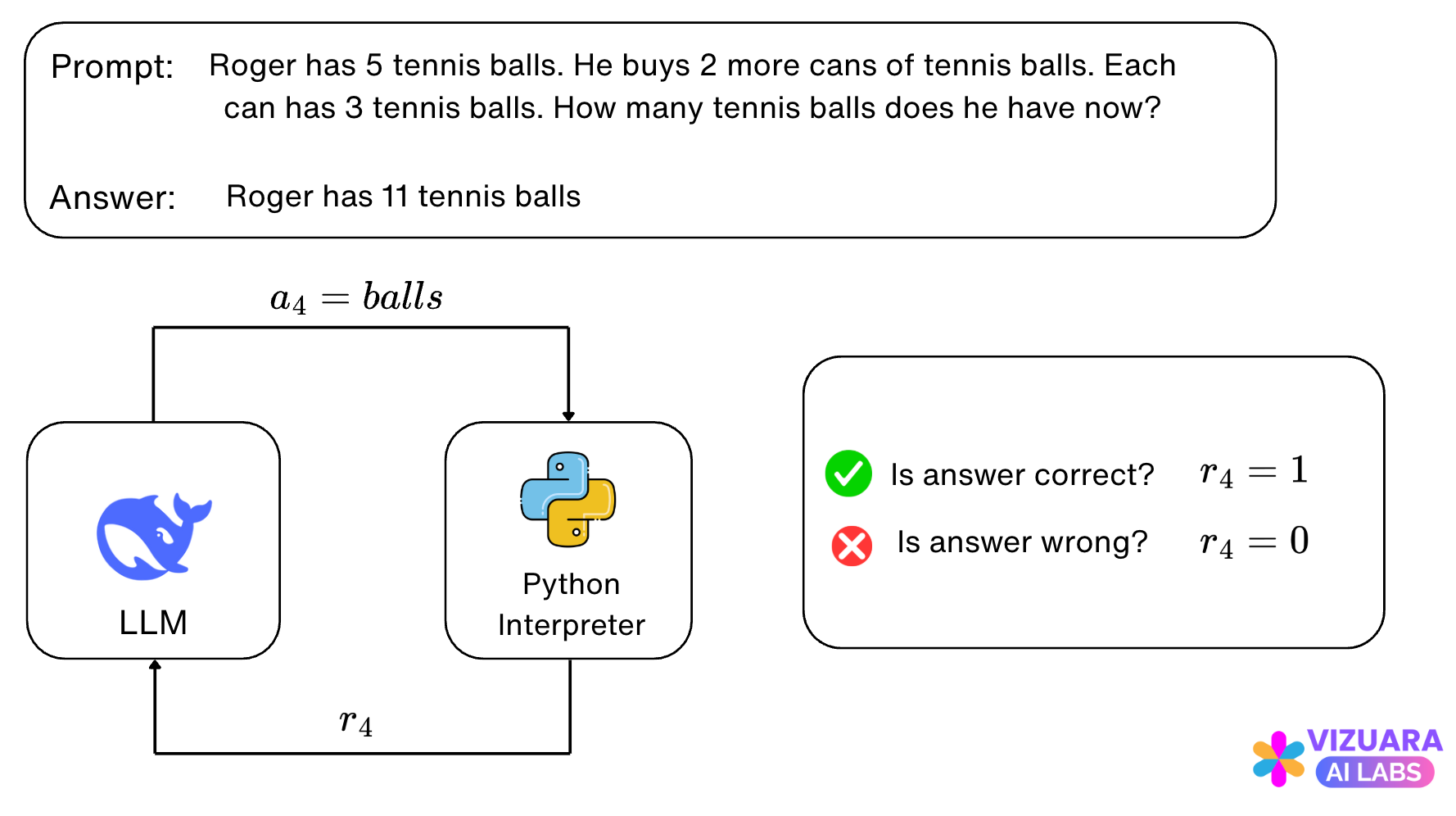
If the reward is positive, then a signal is sent to the LLM which tells it to reinforce all the actions in the answer completion. If the reward is zero, the actions are penalized.
Question 2: How is the LLM updated after receiving feedback from the reward score?
For every state seen by our agent (the LLM), it is selecting an action which has the highest probability of being the next word. Along with this action, there are many other actions also with lower probabilities.
Consider the above example of “Roger has 5 tennis balls..”. If the LLM has generated the word “Roger” already and is considering choosing the next action, it creates a probability distribution for all actions.
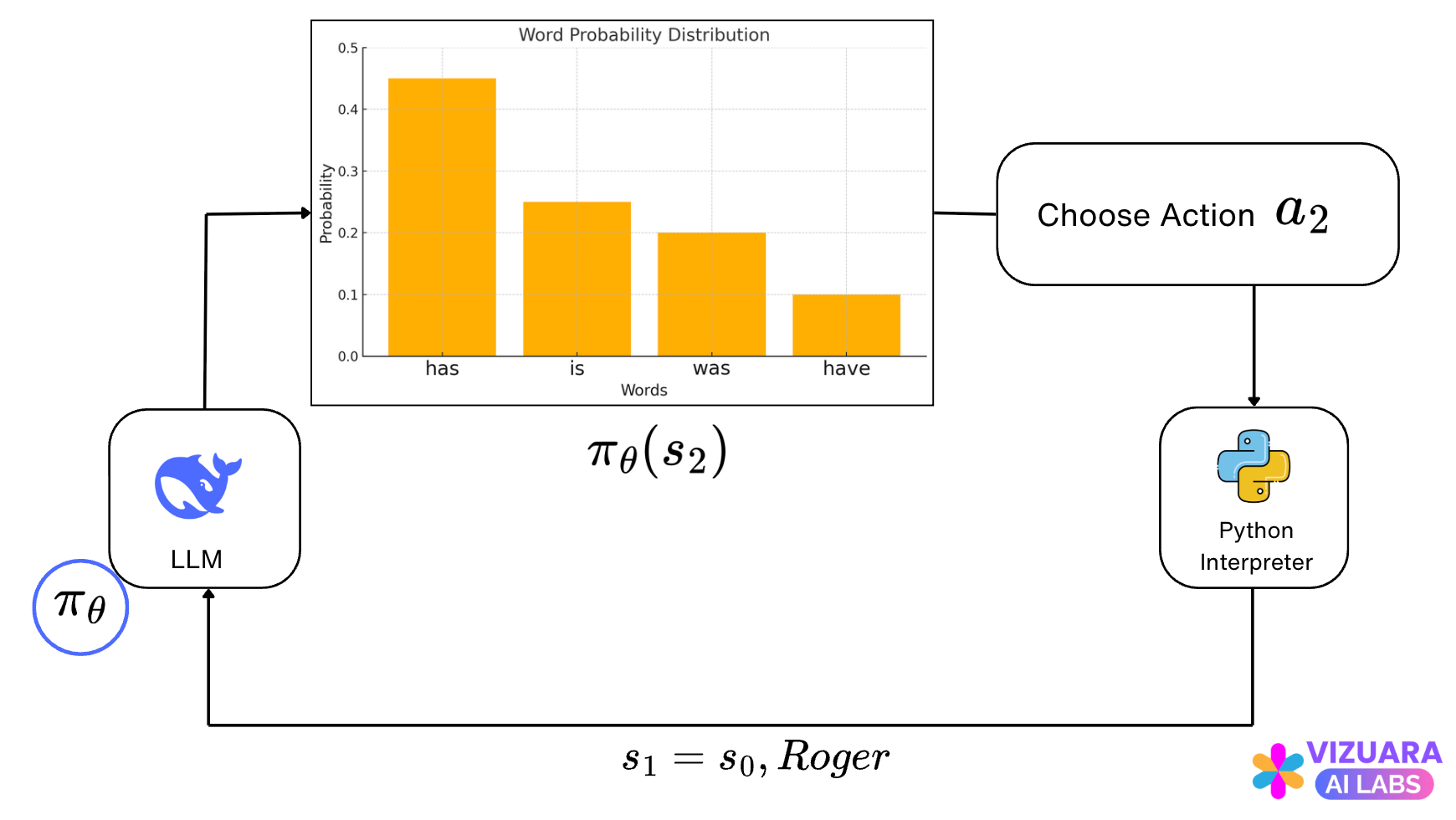
And then picks the action with the highest probability, “has” in this case. Now if the reward is positive, the action is reinforced, else it is penalized.
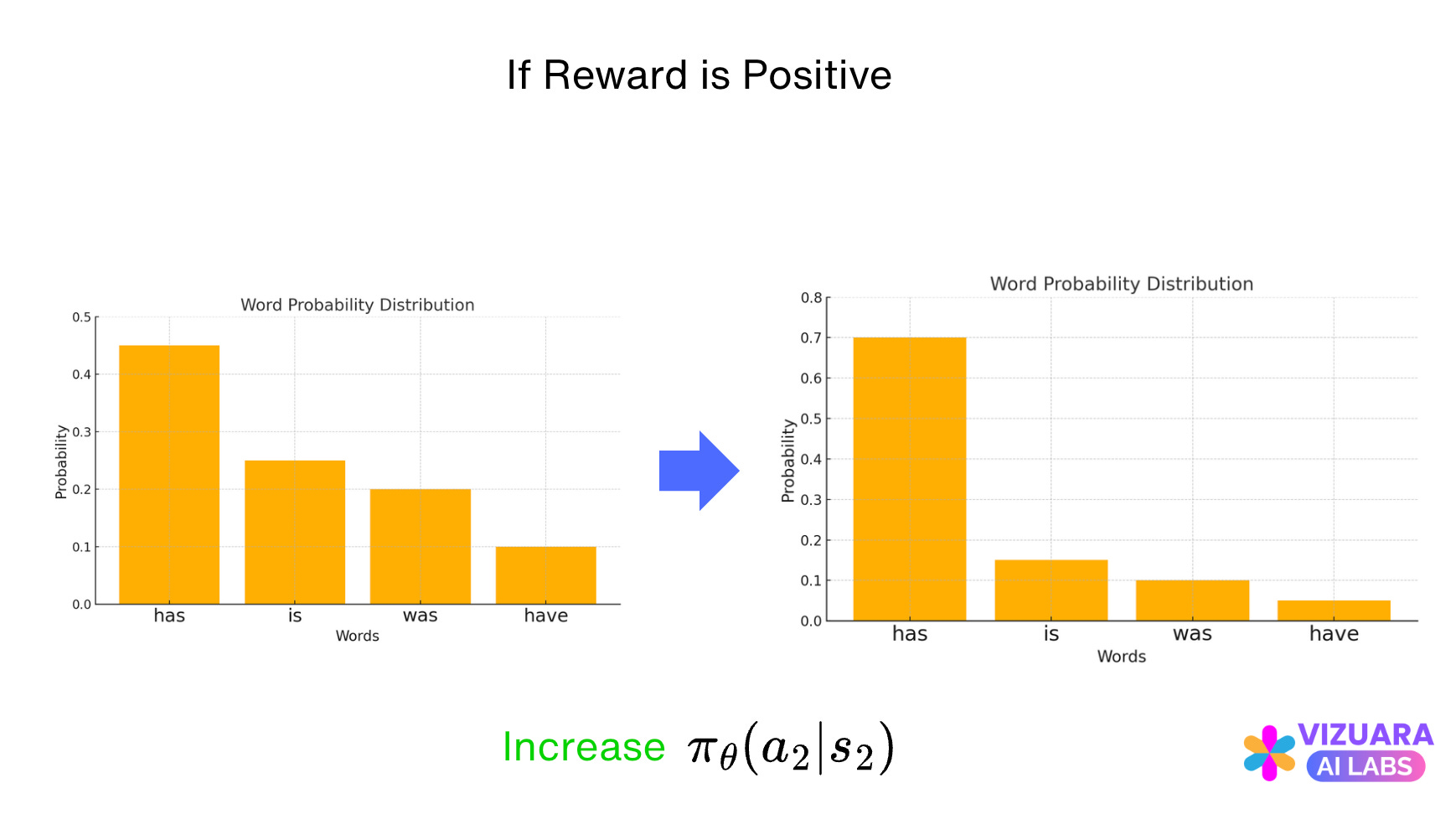
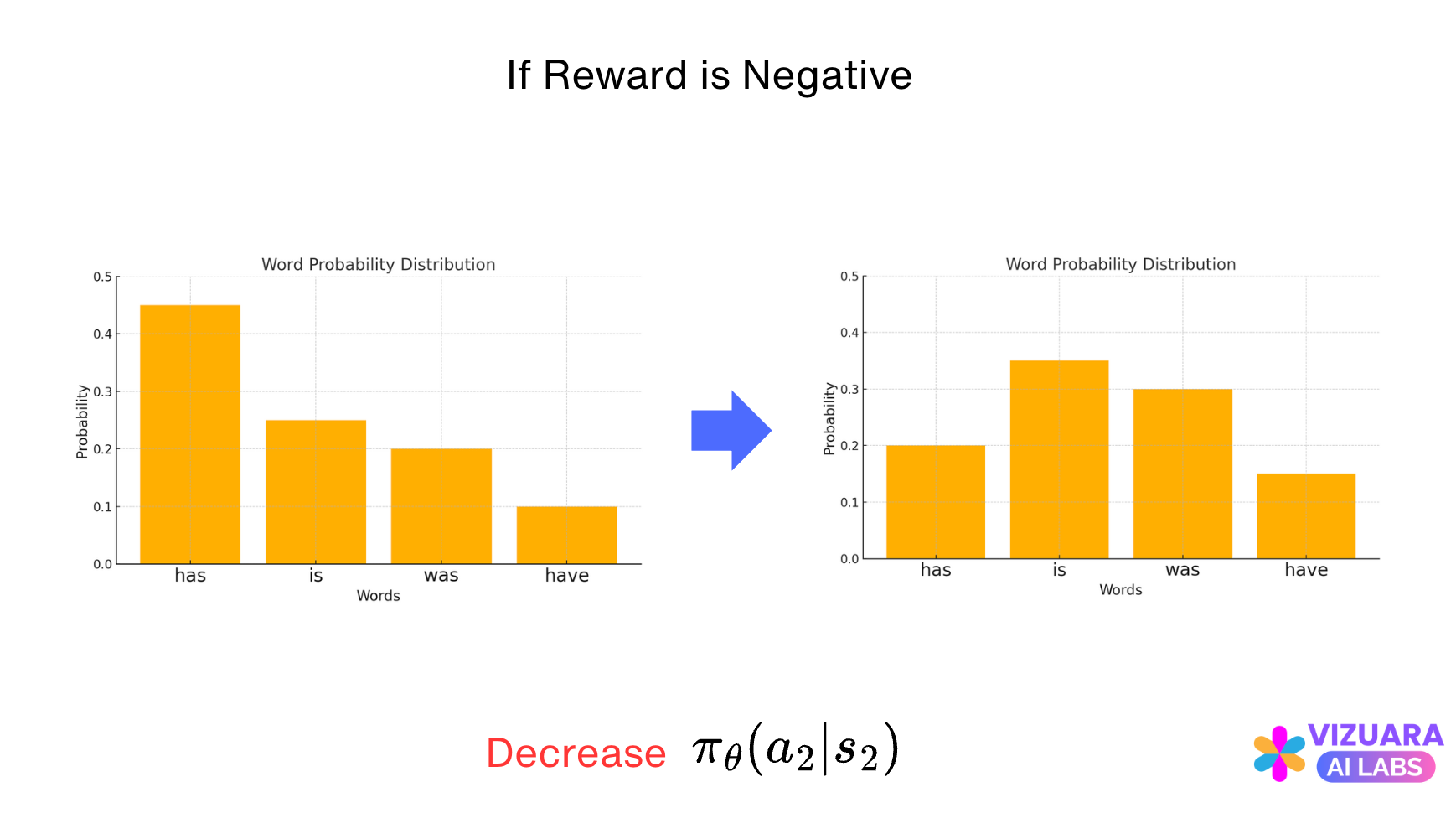
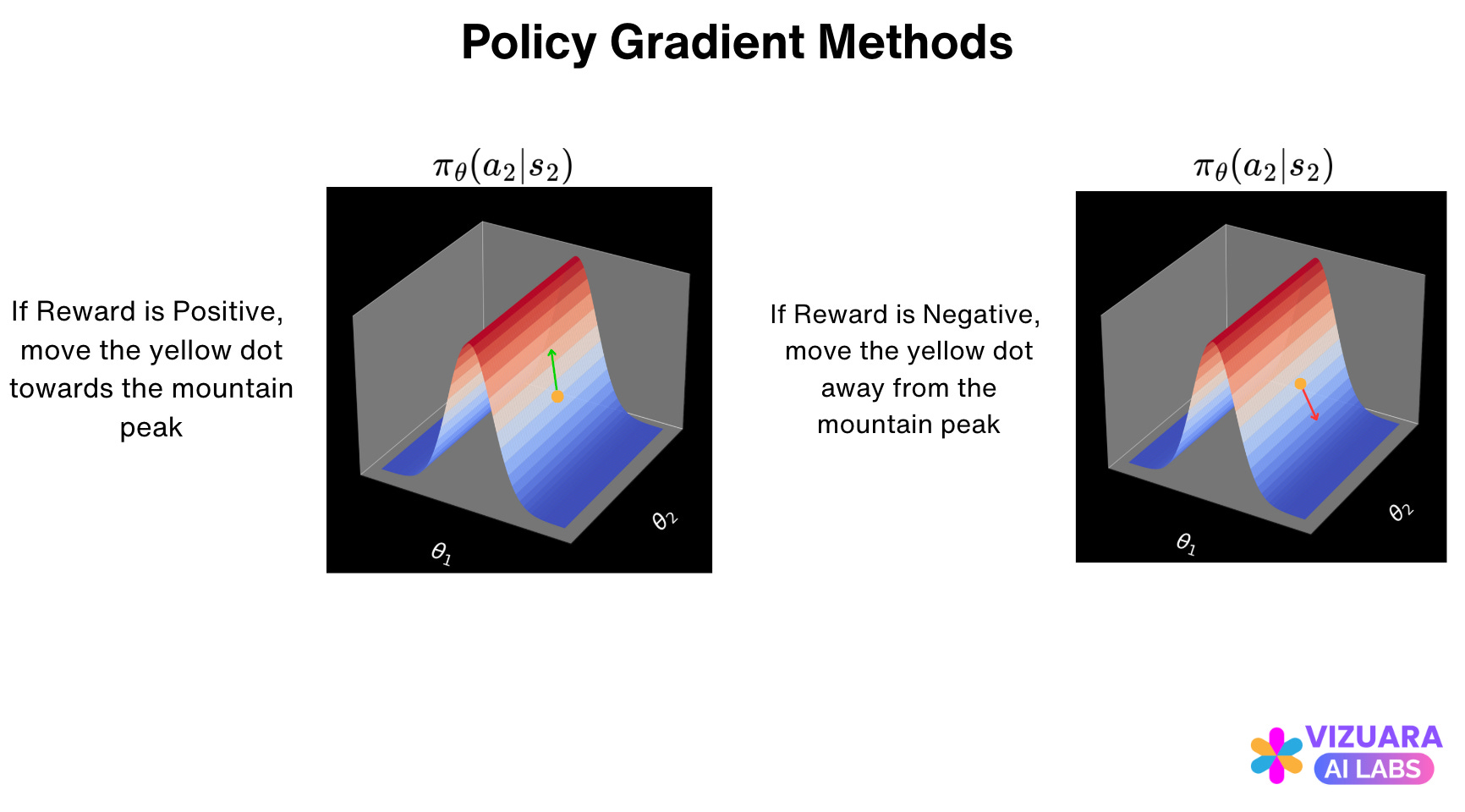
Methods which do this are called as Policy Gradient Methods. They tell us how to change our policy (the LLM) such that actions which receive positive rewards are reinforced and actions which receive negative rewards are penalized.
The parameters of the policy are updated using the gradient ascent rule as given below:
Here, R is the reward received after the end of the sentence completion. The “log” in the above expression appears after performing simplifications to the gradient ascent rule. Notice how the reward appears after the gradient, which allows us to reinforce or penalize the action depending on the sign of the reward.
To reduce the variance in the policy updates, the above expression is modified slightly by subtracting a baseline from the reward R. This baseline is typically the value function of the state.
In Reinforcement Learning, the value function of a state is the expected return received by the agent after starting in that state.
The policy update rule then can be written as follows:
The difference between the reward and the value function is called as Advantage.
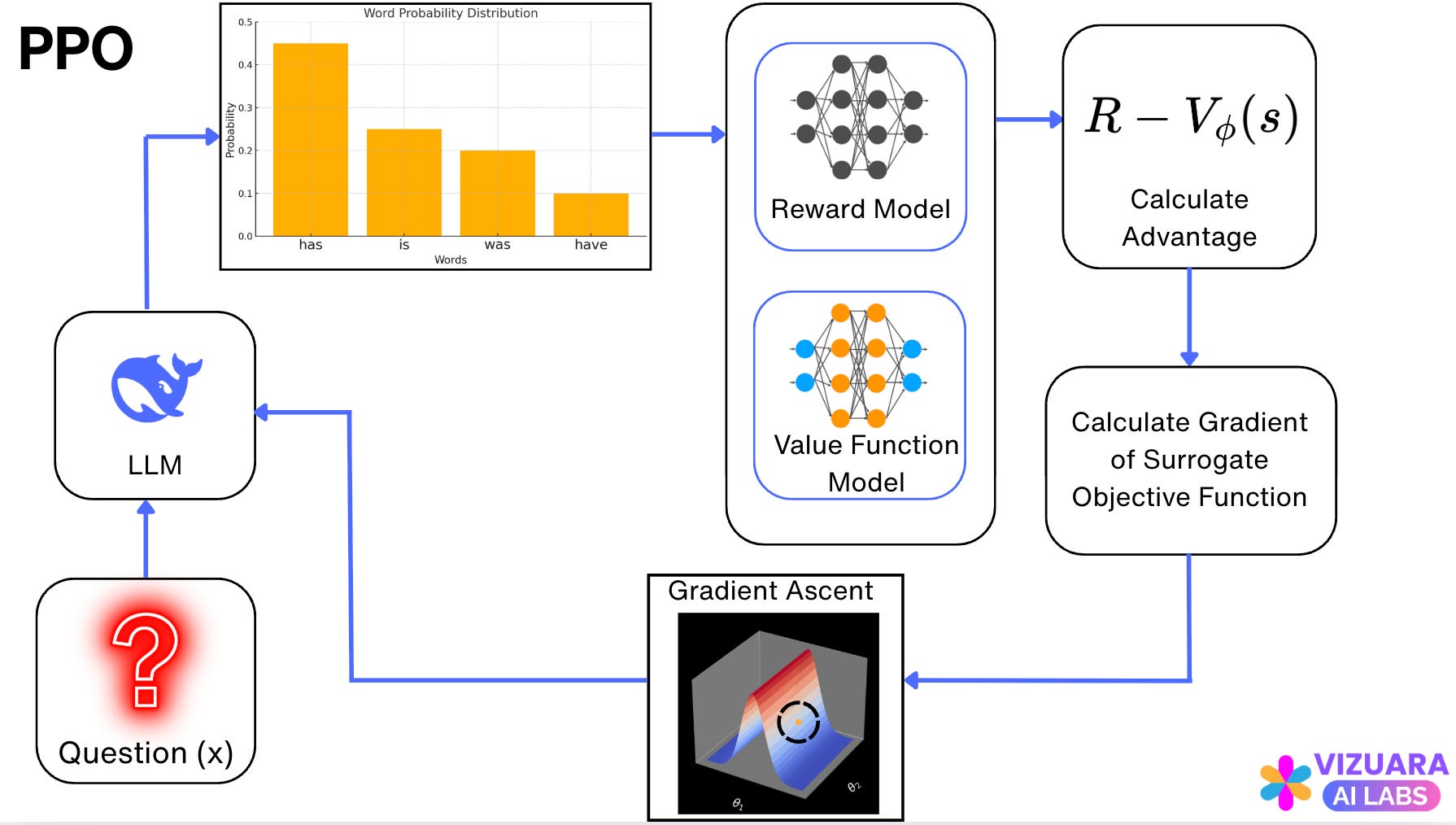
Before GRPO came out, the popular algorithm was Proximal Policy Optimization (PPO). Now, PPO relied on two models to estimate the advantage - (1) Reward Model to estimate the rewards and (2) Value Function Model.
The PPO pipeline looked like follows:
Question 3: What was the main contribution of GRPO?
GRPO came along and said, “Why do you need the value function model to calculate the advantages?”

But how was it done?
First, GRPO said that instead of sampling one output, multiple outputs should be sampled.
With the same example as before, we will now sample 4 different answers. Let’s say these answers are:

Now, we calculate the rewards for each of these outputs:
We will see a distribution in the reward values. Some outputs will get high rewards while some will get low.
To calculate the advantages, we simply subtract normalize the rewards (subtract the mean and divide by the variance).
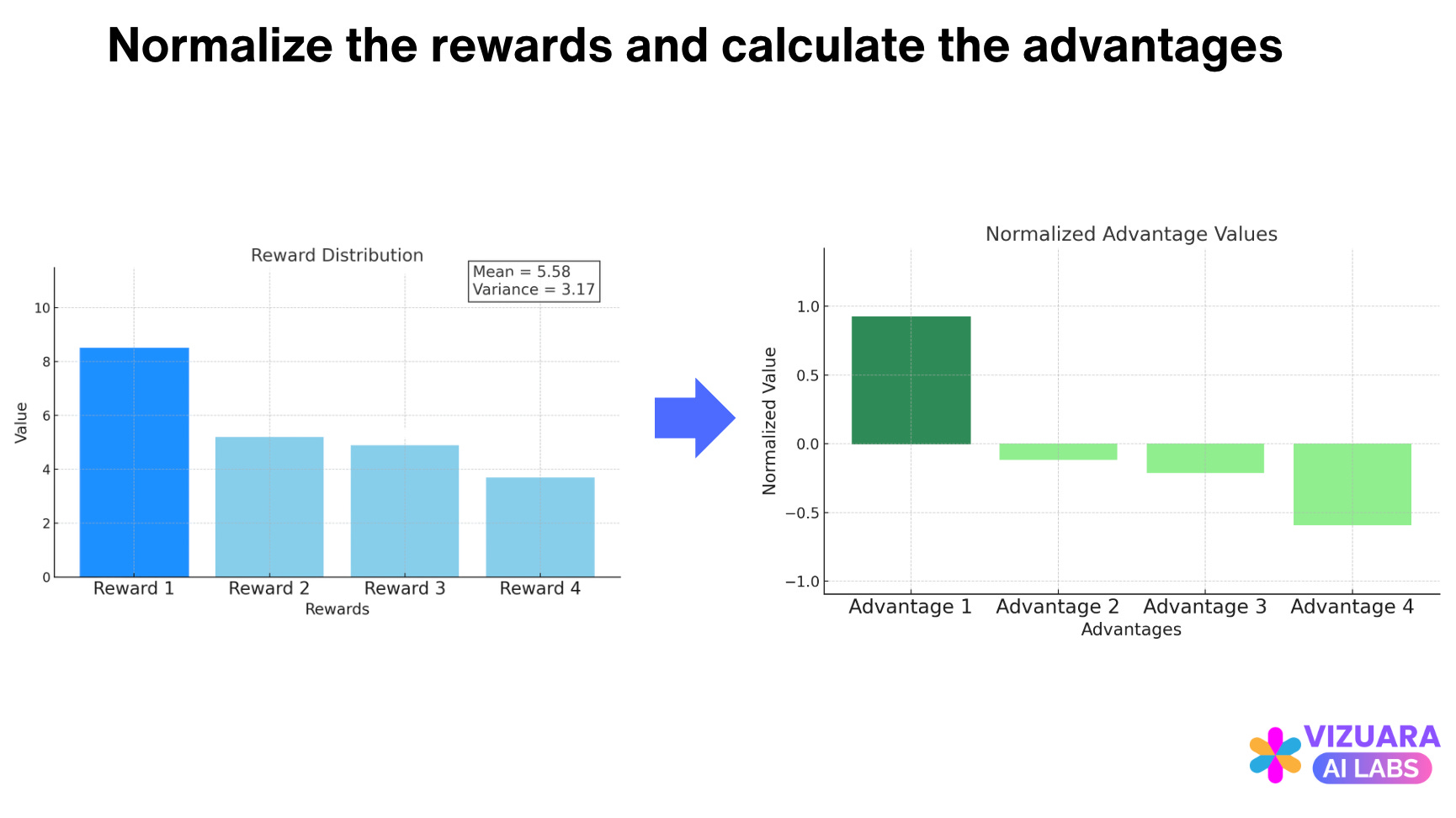
The key idea is that, the mean of the rewards of the output samples is used as an estimate for the value function of the initial state (the prompt).
This way, a separate value function model is not required.
The GRPO pipeline looks like this:
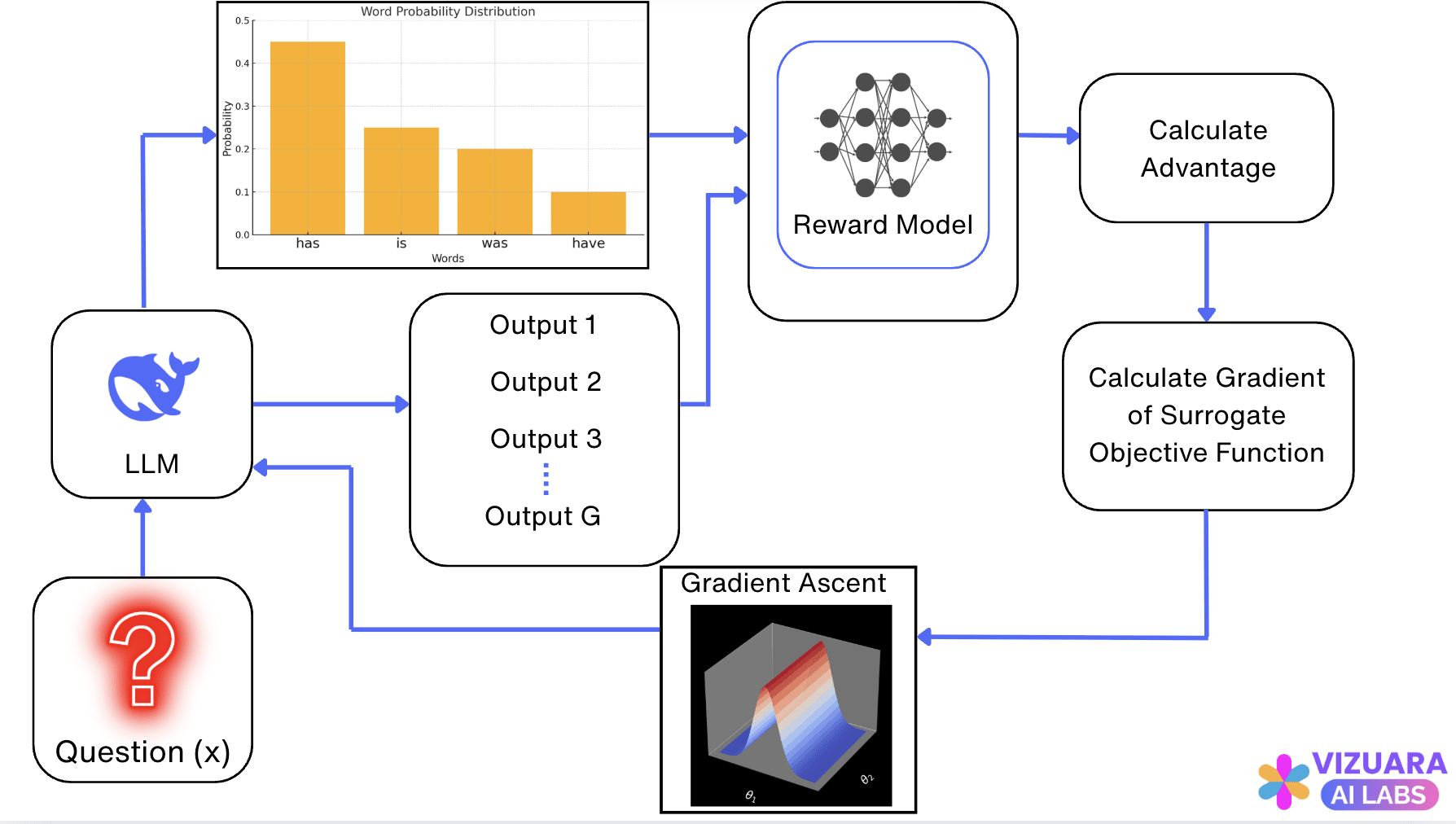
In DeepSeek-R1, GRPO algorithm is used in the Reinforcement Learning Stage. In practice, a reward model is also not required, since they use “Verifiable Rewards” which have a definite right or wrong answer.
Now, let us modify the policy update rule:
The above policy update rules tells us how to change the policy such that actions with positive advantages are reinforced and actions with negative advantages are penalized.
Question 4: How is the GRPO policy update rule written?
Researchers found out that this policy update rule does not work in practice. Largely because, the new policy has deviated too much from the old policy which is the instruction fine-tuned model before the Reinforcement Learning step.

It is better to restrict the policy updates such that they do not cross a certain “trust region”. This idea was first introduced in the paper “Trust Region Policy Optimization” and later made simpler by PPO.
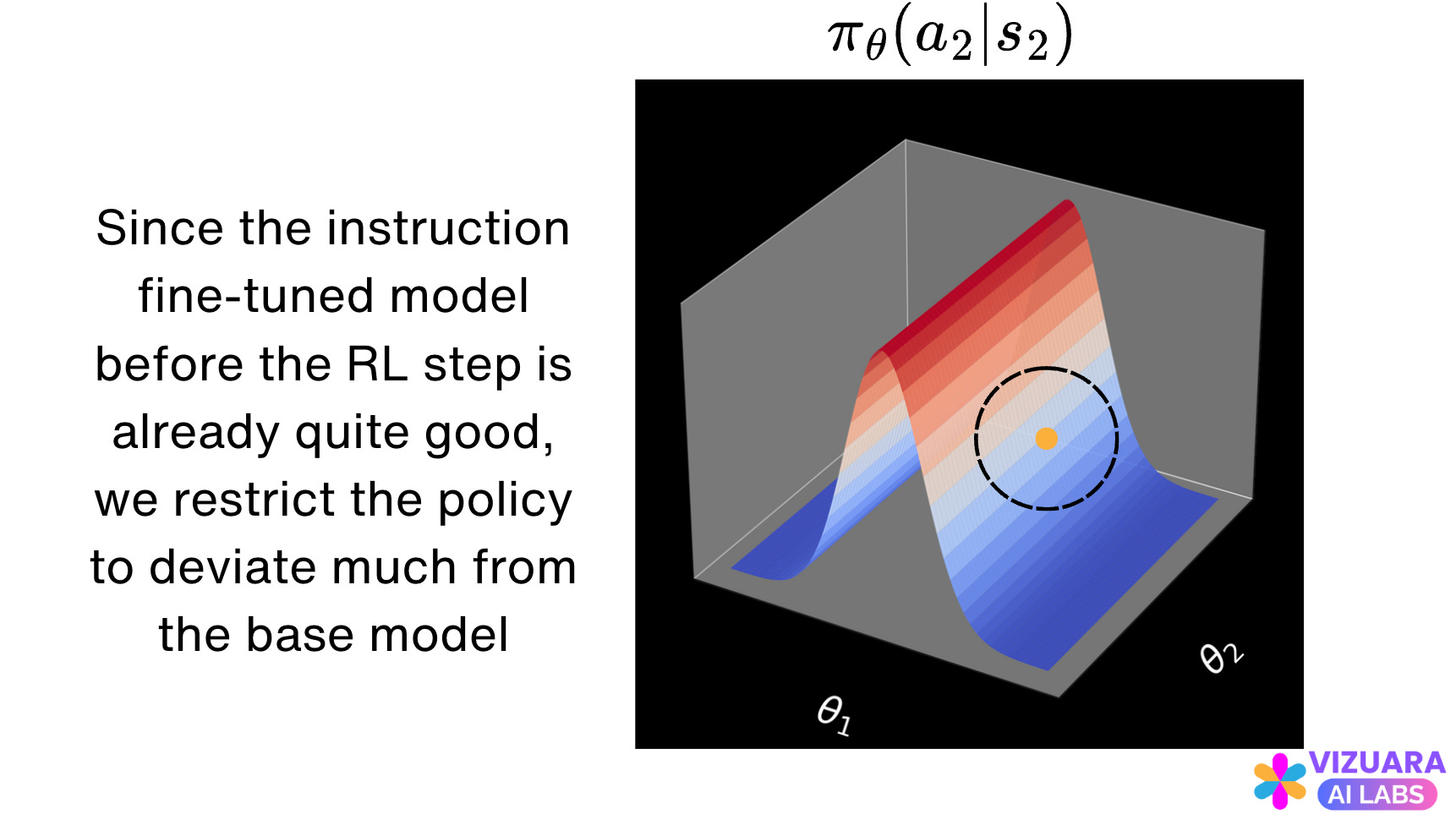
The black circle represents the “trust region” within which the policy changes will be allowed.
The ratio between the new policy and the old policy is written as:
PPO said that, “For large policy updates, clip the update and bring it back within acceptable limits”:
This can be mathematically written using the clip function:
From the gradient ascent formula for vanilla policy gradient methods, the objective function which we want to maximize can be written as:
For PPO, the objective function which we want to maximize changes to the following:
This is almost close to the actual PPO objective function.
The GRPO objective function is built upon the PPO objective function with an additional term. It looks as follows:
Here the second term denotes the KL divergence between the updated policy and the reference policy. The KL divergence measures how different the two probability distributions are. The reason why this term appears comes from the paper on Trust Region Policy Optimization (TRPO) which came out in 2015.
Question 5: How did GRPO help in building reasoning models?
When the DeepSeek-R1 paper first came out in January 2025, they showed that, large language models can be taught to reason using “pure reinforcement learning”.

At the heart of “pure reinforcement learning” was the GRPO algorithm which we looked at before.
The paper showed that, rather than explicitly teaching the model how to solve the problem, it automatically develops reasoning strategies by giving the right incentives.
Consider the example below:

The model says “Wait, wait, Wait. That’s an aha moment I can flag here”. It does this by itself, without giving any supervised input-output examples.

Now, GRPO has become the standard in the Reinforcement Learning step of Large Reasoning Models (LRMs)
Thanks for reading!