


Janus-Pro: A Unified Multimodal system 🤖 for understanding 🤔 and generation 🎨
DeepSeek launched another open-source and open-weight model capable of generating and understanding images in a unified architecture, keep reading to understand What? Why? and How? of Janus-pro-7B.


Table of contents
Introduction
What? And Why? of multi-modal models
Multi-modal understanding
Multi-modal generation
Ideal case
Problem with unified architecture
Methodology
Architecture choice
Training Process
Scaling
Outcome/Results
Thoughts
Conclusion
Introduction
Deepseek had been on an absolute roll since its advent with DeepSeekR1 (the open-source rival of much larger and closed models), another of their breakthrough came in quite recently when they launched Janus-pro-7B a completely open-weights multi-modal understanding and generation model that performed better than Dalle3 (from openAI) for generation and Llava (open-sourced) for understanding, one important thing to point out is that they were able to beat both with an unified architecture (some nuances here, which we will cover further), which in itself is a huge achievement.
The Janus pro in itself is not the single shot to glory, before this specific model they had two prior attempts, namely, Janus and Janus-flow. In this article we will try to understand the knitty-gritty details around the ideas that lead to Janus-pro-7B.

What? And Why? of multi-modal models
Multi-modal models are systems that can interpret/utilize inputs from multiple domains like text, visual, audio, etc. the tasks in itself could be again broken into multi-modal understanding and multi-modal generation.
Multimodal Understanding
 | Papers With Code")
Multimodal understanding refers to a model's ability to interpret and reason across different types of data, such as text, images, and audio, to extract meaningful insights. Unlike unimodal models that process only one type of input, multimodal understanding requires aligning multiple representations and identifying relationships between different modalities. This capability is essential for tasks such as visual question answering, where a model must analyze an image and generate a relevant textual response, or image captioning, where an image is described in natural language. Another key application is multimodal retrieval, where a model finds relevant images for a given text query or vice versa, relying on learned associations between language and visual features. More advanced forms of multimodal understanding involve reasoning across modalities, such as explaining why an object in an image belongs to a particular category or inferring the sentiment of a scene based on both textual and visual cues. Models like CLIP, which learn a shared embedding space for images and text, and BLIP-2, which generates captions and answers questions about images, have made significant progress in this domain. However, the challenge remains in ensuring that these models generalize well to diverse, unseen scenarios without requiring extensive labeled data.
Multimodal Generation

Multimodal generation, on the other hand, involves creating new content that spans multiple modalities, such as generating images from textual descriptions or synthesizing speech from text. This task requires not only understanding the input prompt but also producing coherent and high-quality outputs that align with the given constraints. One of the most well-known applications of multimodal generation is text-to-image synthesis, where models like DALL·E 3 and Stable Diffusion take natural language prompts and transform them into realistic or artistic images. Similarly, text-to-video generation models like OpenAI’s Sora extend this capability to dynamic sequences, creating short videos from descriptive text inputs. Another example is image-to-text generation, where a model analyzes an image and generates a detailed textual description, making it useful for accessibility applications like screen readers for visually impaired users. The primary challenge in multimodal generation lies in maintaining consistency between the modalities, ensuring that the generated content remains relevant to the input. This is particularly difficult in cases where fine-grained details matter, such as generating images that accurately reflect complex textual prompts or producing videos where actions unfold naturally over time. Improving coherence, reducing inference time, and enhancing the quality of generated outputs remain key research areas in this evolving field.
Multi-modality could be considered the closest to human perception which an artificial model is capable of. Imagine a model that only understands/interpret language like our current day LLMs, it is then bounded by tokens/words/sentences, whereas any model that looks at images only is bounded by spatial information/pixels, hence, it is vehemently clear that any uni-modal model is restricted by the axiom/base token representation.
Now to summarize, on task level multi-modal systems has two components (we are obviously making simplistic assumption and not going by the probabilistic modelling perspective, but, for now this is good enough to categorize the tasks)
Generation : text2img, img2img
Understanding : VQA (image2Text), boxes, segments
Ideal case
As per our discussions above we understand that we have two important tasks at hand, multiple architectures like Llava, dino, Florence, etc. that are really good with understanding an image whereas models like SDXL, DallE3 are fairly good with generation tasks, but, in an ideal case, a single encoder should be capable of both understanding and generation without requiring separate models.

This is not only intuitive to think of, but, the definition of probabilistic models itself allows the possibility of sampling/generation i.e P(X,z) and conditioning/understanding P(y|X).
Problem with unified architecture
If an model is capable of following prompt and generating corresponding image or if it is able to find objects, caption it, ground it, then it should be able to form this link between text and image, also for the alignment of tasks, the type of distribution which required to approximate this could be used to sample and condition both.
However, current architectures face practical limitations that make separation beneficial:
Different Feature Requirements
Understanding tasks require extracting high-level semantic features from images, which help in tasks like captioning, reasoning, and answering questions.
Generation requires a spatially-aware representation that can be used to synthesize images pixel by pixel while maintaining fidelity to the input prompt.
A single encoder struggles to balance these two demands, leading to suboptimal performance in one or both tasks.Training Stability Issues
A unified encoder often causes conflicts during training because the optimization objectives for understanding (contrastive/embedding learning) and generation (diffusion/decoder-friendly representations) differ. Previous models like CogView and early versions of DALL-E faced mode collapse or degraded performance in at least one task. Separating the encoder heads helps decouple these objectives and train each component optimally.
Current Model Limitations
While ideal architectures should support both tasks within a single block, existing transformers and diffusion models still struggle to efficiently switch between high-level and low-level feature needs.
In future multimodal models, advancements in adaptive representations (e.g., latent-space conditioning, shared embeddings) might allow a unified encoder without trade-offs.
Given all these practical issues, the methodology proposed in paper makes Janus one of the only successful models in performing both of the tasks at extremely strong levels, comparable/better than there individual counterparts.
Methodology
Now we are clear about importance of multi-modality, it's ideal case (aggregation into single model) and the problems associated with it. Janus in itself is an amalgamation of multiple pre-existing yet isloated developments happening in multi-modality field over last few months, deepseek very similar to how they formulated R1 (bringing the right components at right place), executed the same process here. Let's see how Deepseek tackled the issue through Janus:
1. Architecture choice

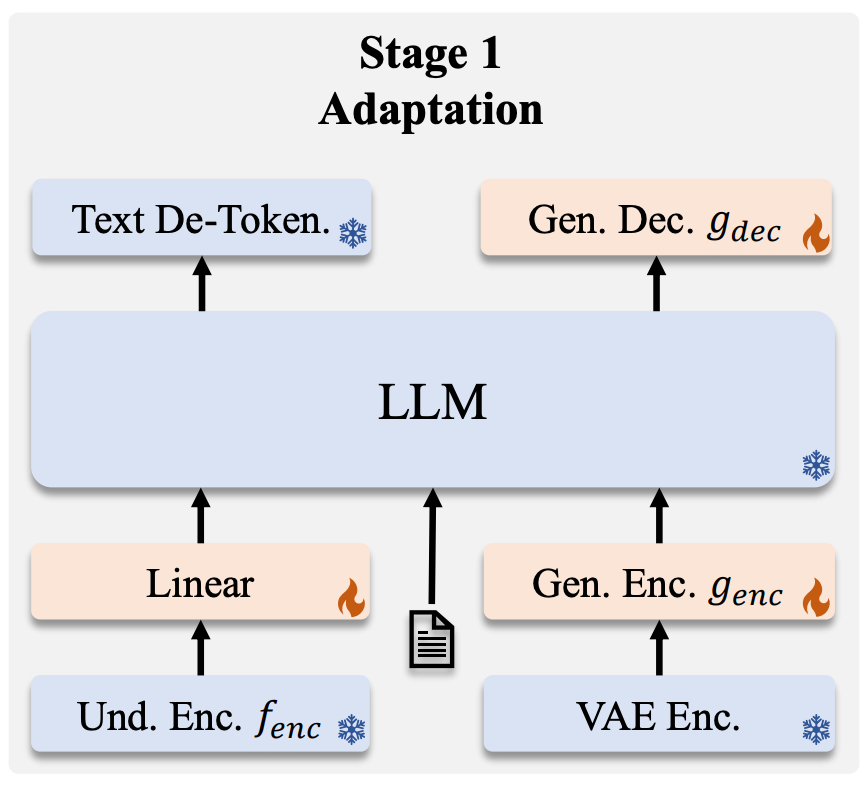
Authors tried to find out a common ground between two separate model and one common backbone. They kept encoding and decoding head seperate to optimize objective specific tasks. The backbone is kept common and it serves as transition between input and output space, hence works as a mediator between different modalities in embedding space (check out the diagram below)

Let's go through each component from the diagram one by one
Understanding encoder head : The encoder used here is an pre-existing model called SigLIP. SigLiP is an improved version of CLIP. Simply explained, SigLIP (Sigmoid Loss Image-Text Pretraining) is a vision-language model designed to improve contrastive learning between images and text by replacing the traditional softmax-based loss with a sigmoid loss function. Unlike CLIP, which normalizes image-text pairs into a shared embedding space using softmax-based contrastive learning, SigLIP treats each image-text match independently, hence optimizes global objective between image-text pairs instead of relative comparison, hence, eliminating the need for global batch comparisons. This approach enhances training stability, reduces computational overhead, and improves performance on zero-shot and retrieval tasks. Compared to CLIP, SigLIP is more robust to dataset biases and noise, making it better suited for real-world applications where training data might be noisy or imbalanced.
Generation encoder head : For understanding the generation tasks, authors used LlamaGen which is a VQ-VAE (Vector Quantized Variational Autoencoder) based architecture. Unlike traditional diffusion-based models like DALL·E, LLaMaGen leverages transformer-based autoregressive generation, making it more efficient in handling complex image synthesis tasks. It integrates token-based image generation, where images are represented as discrete tokens rather than pixel-level diffusion, allowing better alignment with text inputs.
Tokenizer : The authors used an unified tokenizer from Tokenflow paper. The proposed tokenizer here uses a dual codebook architecture that decouples semantic and pixel/spatial features. Hence, a single tokenizer is able to handle both images and text, which was earlier supposed to be done by seperate/independent tokenizer. More nuances of this paper is beyond the scope of this article (maybe in next blog we can discuss on the attempts of unified tokenizer through unitoken, Tokenflow, etc.)
LLM backbone : This backbone is simply an conventional auto-regressive language model (token-to-token). Here they utilized Pre-trained Deepseek-llm with max sequence length of 4096.
Text decoder/de-tokenizer : This is simply a de-tokenization step based on the predicted tokens by the backbone.
Image decoder : The image decoder head is pretty similar to patching based prediction operation in VIT architectures, here each patch/pixel-groups is generated as a tokens. This method aligns with the backbone model's transformer architecture, facilitating seamless integration between text and image modalities (you can think of image decoder as more like a refiner, while the LLM backbone does most of the heavy-lifting). The more important thing is how does the alignment between generated vs expected patch happen, and that is a flow-based method, more specifically the generation process is optimised through rectified flow (as in Janus-flow paper).
To read and understand flow matching in detail read this article (flow matching), but, in summary, Rectified Flow is a technique that reformulates diffusion models by directly learning a straight-line transformation between noise and the target data distribution, rather than relying on stochastic sampling through complex intermediate steps. Intuitively, instead of taking a noisy, winding path to denoise an image (as in standard diffusion models), Rectified Flow learns a direct and efficient trajectory from pure noise to a high-quality image. This approach reduces generation time, improves stability, and often results in higher-quality outputs with fewer inference steps.
![fly51fly on X: "[CV] Improving the Training of Rectified Flows https://t.co/b0EhY3NoVz - Rectified flows can generate high-quality image samples with fewer function evaluations than diffusion models, but still require more evaluations than](https://substackcdn.com/image/fetch/$s_!jL-9!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fce46056a-833a-4cfc-8924-2e0cf29f00f2_1740x684.jpeg "fly51fly on X: \"[CV] Improving the Training of Rectified Flows https://t.co/b0EhY3NoVz - Rectified flows can generate high-quality image samples with fewer function evaluations than diffusion models, but still require more evaluations than")
![fly51fly on X: "[CV] Improving the Training of Rectified Flows https://t.co/b0EhY3NoVz - Rectified flows can generate high-quality image samples with fewer function evaluations than diffusion models, but still require more evaluations than](https://substackcdn.com/image/fetch/$s_!jL-9!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fce46056a-833a-4cfc-8924-2e0cf29f00f2_1740x684.jpeg "fly51fly on X: \"[CV] Improving the Training of Rectified Flows https://t.co/b0EhY3NoVz - Rectified flows can generate high-quality image samples with fewer function evaluations than diffusion models, but still require more evaluations than")
Now we understand each component in isolation, let's go through the entire process/training pipeline.
2. Training process
The training process looks very similar to how we typically train LLMs. The entire process is broken into three sections.
Adaptation

This step serves as the precursor to actual training. Here task in hand is to inline the projections from encoders (both understanding and generation) to corresponding LLM backbone, basically learning mapping from input to output distributions. This is done through usage of adapter layers; which simply are few layered deep MLPs. Here we also align the image generator with our encoders through the rectified flow we discussed above. Hence, here we train both of our module adapters, image generator/decoder to align and work alongside each other, the alignment step ensures that there exists projection operation which can take/sample from one domain/distribution to other distribution (encoder -> decoder).
By initially optimizing for the alignment, the authors ensured to have a stable yet working end-to-end flow, the quality of this flow is further tuned/optimised in the next step. The procedure is exactly same for both Janus and Janus pro, but, authors proposed to train janus pro for more steps/number of iterations on ImageNet data.Unified Pre-training

This is presumably the first step in training, here we tune almost the entire architecture to ensure stronger semantic coherence during generation. While training, we re-tune both of our adapters along with our backbone LLM as well as de-tokenizer and image decoder/generator. You can visualise the step as pushing a ball already very close to valley region on a large manifold to the minima. After this step all the components are optimised the effectively peform projection from one domain to other to ensure good quality results. Here, instead of imageNet data; the authors leveraged text2image samples, this inherently teaches the model to handle both multimodal understanding and generation tasks by exposing it to large-scale image-text data, improving its foundational capabilities.
SFT (supervised fine-tuning)

This is final step in the training process, every single component is unfrozen and tuned with dialogues and text2image samples, this refines the model on high-quality, task-specific datasets, enhancing performance in real-world applications like image captioning, reasoning, and generation. By, performing pretraining and adaptation we ensured stable model weights while performing full fine tuning.
Compared to standard LLM SFT, which primarily improves text-based instruction-following and coherence, multimodal SFT has the added challenge of aligning vision-language embeddings to ensure consistency across modalities. Additionally, SFT in multimodal models must prevent catastrophic forgetting of pretraining knowledge while improving specific downstream performance, making it more complex than SFT in pure language models, hence the previous two steps become really important.


3. Scaling
Another very important aspect is how they scaled from Janus to Janus pro
At Data level,
In the Janus-Pro model author scaled data by expanding the training dataset to enhance the model's performance in both multimodal understanding and visual generation tasks. This expansion includes incorporating approximately 90 million new samples, such as image caption data (e.g., YFCC) and document understanding data (e.g., Docmatix), to improve multimodal understanding. For visual generation, Janus-Pro introduces about 72 million synthetic aesthetic data samples, balancing the ratio of real to synthetic data at 1:1. This synthetic data accelerates model convergence and significantly enhances the stability and aesthetic quality of generated images.
At model level,
Janus-Pro scales up to a 7 billion parameter model, compared to its predecessor's 1.5 billion parameters. This increase in model size leverages a larger language model, resulting in faster convergence and improved performance in both multimodal understanding and visual generation tasks.

These scaling strategies collectively contribute to Janus-Pro's advancements in handling complex multimodal tasks and producing high-quality outputs on top of the original Janus and Janus flow idea.
Outcome/results
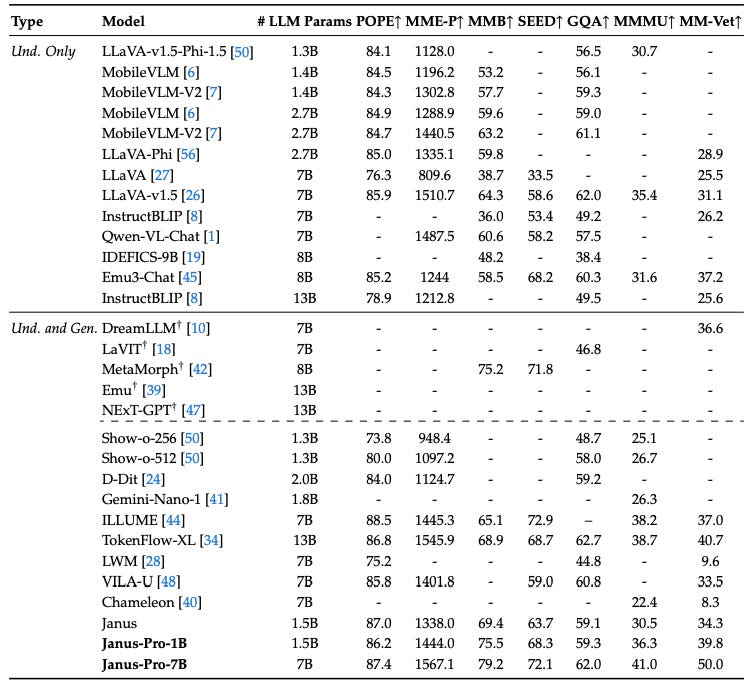
Multimodal Understanding
MMBench Score: Janus-Pro-7B achieved 79.2, outperforming previous models like Janus (69.4), TokenFlow (68.9), MetaMorph (75.2), and LLaVA-v1.5.
SEED-Bench Score: Janus-Pro significantly improved over Janus (63.7) and LLaVA-v1.5 in multimodal reasoning tasks.
POPE Score: Janus-Pro built upon Janus' 87.0 score, showcasing strong perception and reasoning abilities.
Better Alignment: Enhanced vision-language fusion, making it more effective in tasks like visual question answering and captioning.
Text-to-Image Generation
GenEval Benchmark : Achieved 80% accuracy, outperforming Stable Diffusion 3 Medium (74%), DALL-E 3 (67%), and Transfusion (63%).
DPG-Bench Score : Scored 84.19, demonstrating better instruction-following and text-image coherence.


Overall Performance
Outperforms LLaVA in Multimodal Understanding: Janus-Pro surpasses LLaVA-v1.5 in reasoning-heavy benchmarks like MMBench, SEED-Bench, and POPE.
Efficient Generation : Faster training convergence, improved image consistency, and better multimodal alignment than previous models.

Strong Benchmark Performance : Excels in both understanding and generation, proving to be one of the best multimodal AI models available.
Improved Image Quality : Generates detailed, coherent, and realistic images at 384x384 resolution, effectively capturing complex prompts. by introducing 72 million synthetic aesthetic samples, improving stability, diversity, and visual realism.



Thoughts
Unifying Understanding & Generation: Current models use separate heads for image understanding and generation, indicating conflicting requirements. Future work could explore a universal encoder with adaptive representations to handle both tasks efficiently.
Faster Image Generation: Despite using Rectified Flow the inference remains slow. Exploring alternatives like Consistency Models could reduce generation steps while maintaining quality.
Better Text-Image Alignment : It would be interesting to see better methods to optimize for instruction tuning like GRPO and contrastive alignment.
Higher-Resolution & 3D Generation: Janus-Pro is limited to 2D image generation. Extending it to 3D models like NeRF/Gaussian Splatting or something similar to LlamaMesh.
Personalization & Adaptation : Usage of techniques like LoRA-based multimodal fine-tuning would be interesting to understand as we now have multiple avenues/blocks to tune and optimize.
Conclusion
In this article we covered in detail about the Janus architecture from Deepseek, which not only is open-sourced unified but also performs at least on benchmark better than closed as well as segregated models like Dalle3. We discussed at great length about the requirement of multi-modal systems, then we discussed about problems with unified architectures, from there we discussed about ideal case and how to realize it by discussing methodology as discussed in the paper. Finally we explored potential issues and research directions to solve them.
With this we conclude another of our many paper reviews. Please go through the paper for further nuances and details,
📝Janus pro Paper : https://arxiv.org/abs/2501.17811
📝Janus Paper : https://arxiv.org/abs/2410.13848
📝JanusFlow Paper : https://arxiv.org/abs/2411.07975
That's all for today.
Follow me on LinkedIn and Substack for more insightful posts, till then; Happy Learning. Bye👋