
Multimodal embeddings are so counter-intuitive!
Somehow, the idea of an image being present in a vector space is very counter-intuitive to me. Let us understand how it works.

1. A figure to start with
I am going to show you a figure and you have to tell me the first thing that comes to mind:
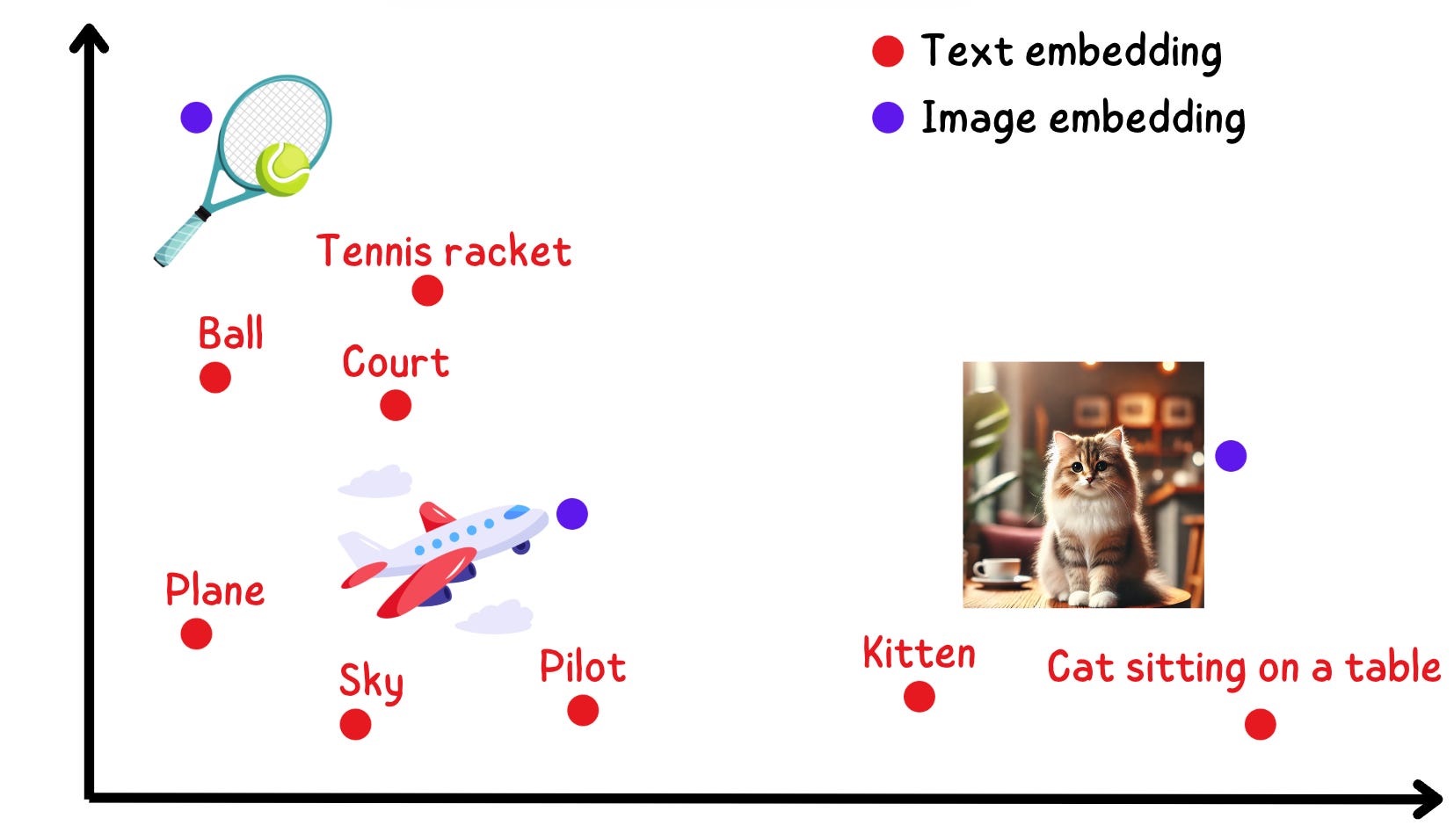
Here is what I think:
When I see the cat image sitting in the same vector space, and being very close to the texts “Kitten” and “Cat sitting on a table”, it feels incredible to me.
Somehow, the idea of an image being present in a vector space is very counter-intuitive to me.
Formally, the above image conveys 2 pieces of information:
Although text and images are different modalities, they can be close to each other in the same vector space.
How is this possible and what’s the best way to think about multimodal embeddings?
2. Information and embeddings
Let’s say that we have the following information: Cat sitting on a table.
This same information can be conveyed in multiple modalities:
Text: “Cat sitting on a table”
Image:


Now let’s say that I want to take this information and compress it into a vector representation.
Embeddings can be thought of as compressed information vectors. From now on, we will refer to these compressed vectors as embeddings.
Here is how the text embedding for “Cat sitting on a table” can look like:

Now let’s take this image:

The image embedding for this image can look like:
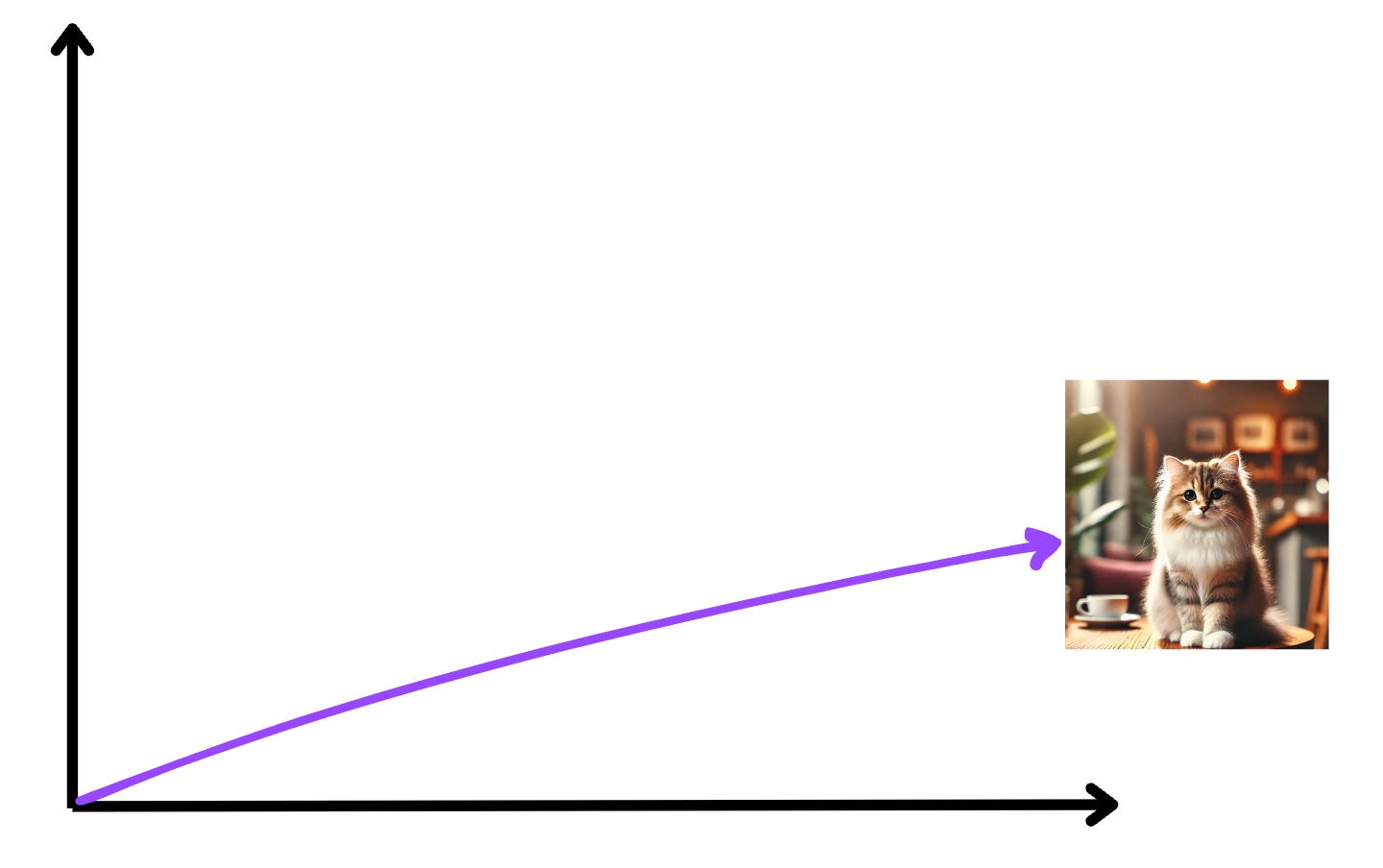
Now we can superimpose both of these in the same vector space:
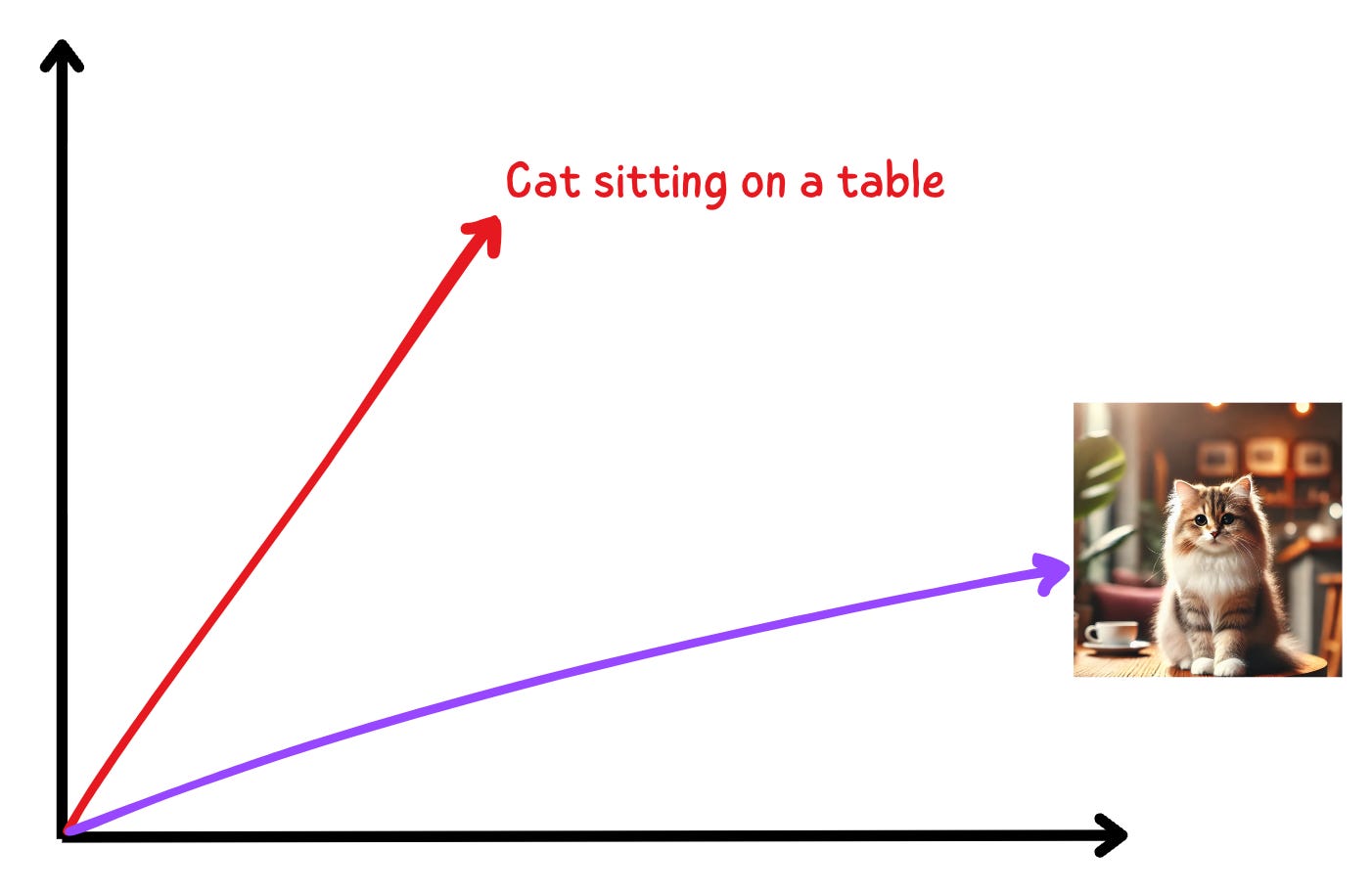
Does this above graph make sense?
If both these vectors represent the same underlying information, shouldn’t they be more aligned to each other?
Shouldn’t they look like this?

3. CLIP (Contrastive Language-Image Pretraining)
This is exactly what multimodal embedding models try to do.
They take text and convert the text into embeddings. They take images and convert the images into embeddings.
They then aim to maximize the cosine similarity between these embeddings so that the vectors are closely aligned.
One such multimodal embedding model is CLIP: Contrastive Language Image Pre-training.

4. How CLIP works?
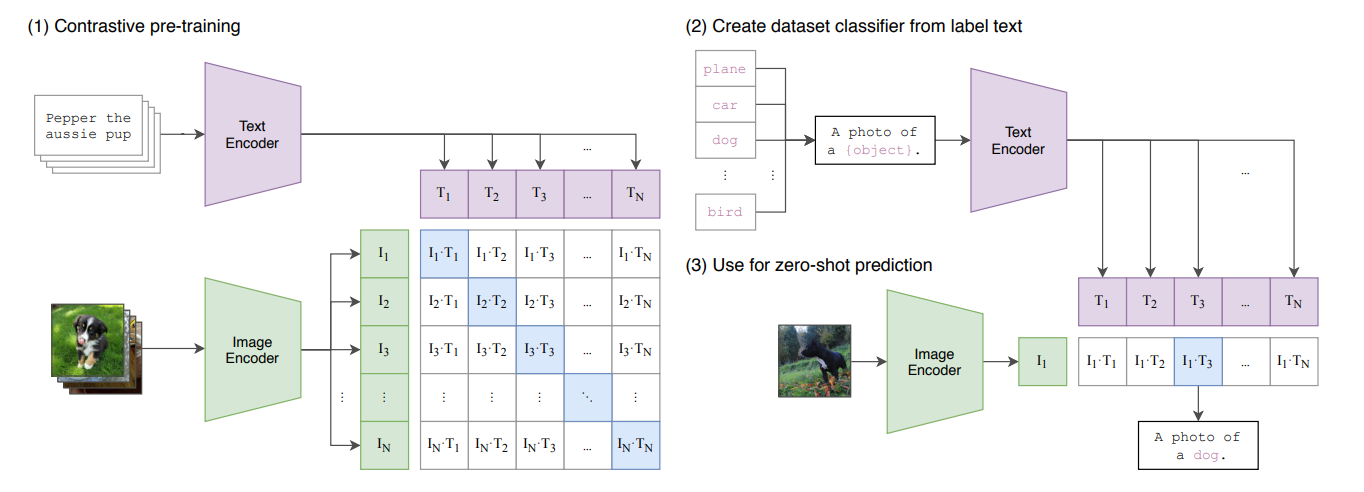
We can understand the CLIP architecture in 3 steps:
Step 1: CLIP produces text embeddings
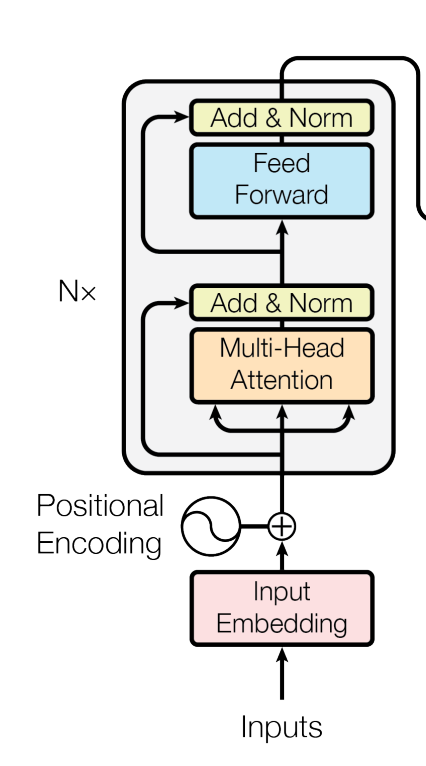
To create text embeddings, the multimodal models use the transformer encoder block.
Tokenization: The text is first tokenized into subwords using a pre-trained tokenizer (e.g., BPE).
Input Embeddings: Each token is mapped to an embedding vector using an embedding layer. Positional embeddings are added to retain order information.
Transformer Layers:
The embeddings pass through several layers of multi-head self-attention, feedforward networks, and normalization.
The model captures contextual information by learning relationships between tokens in the sentence.
Representation Extraction:
The output from the final layer of the Transformer is pooled. Specifically, CLIP uses the embedding of a special [EOS] token to represent the entire sentence.
Step 2: CLIP produces image embeddings
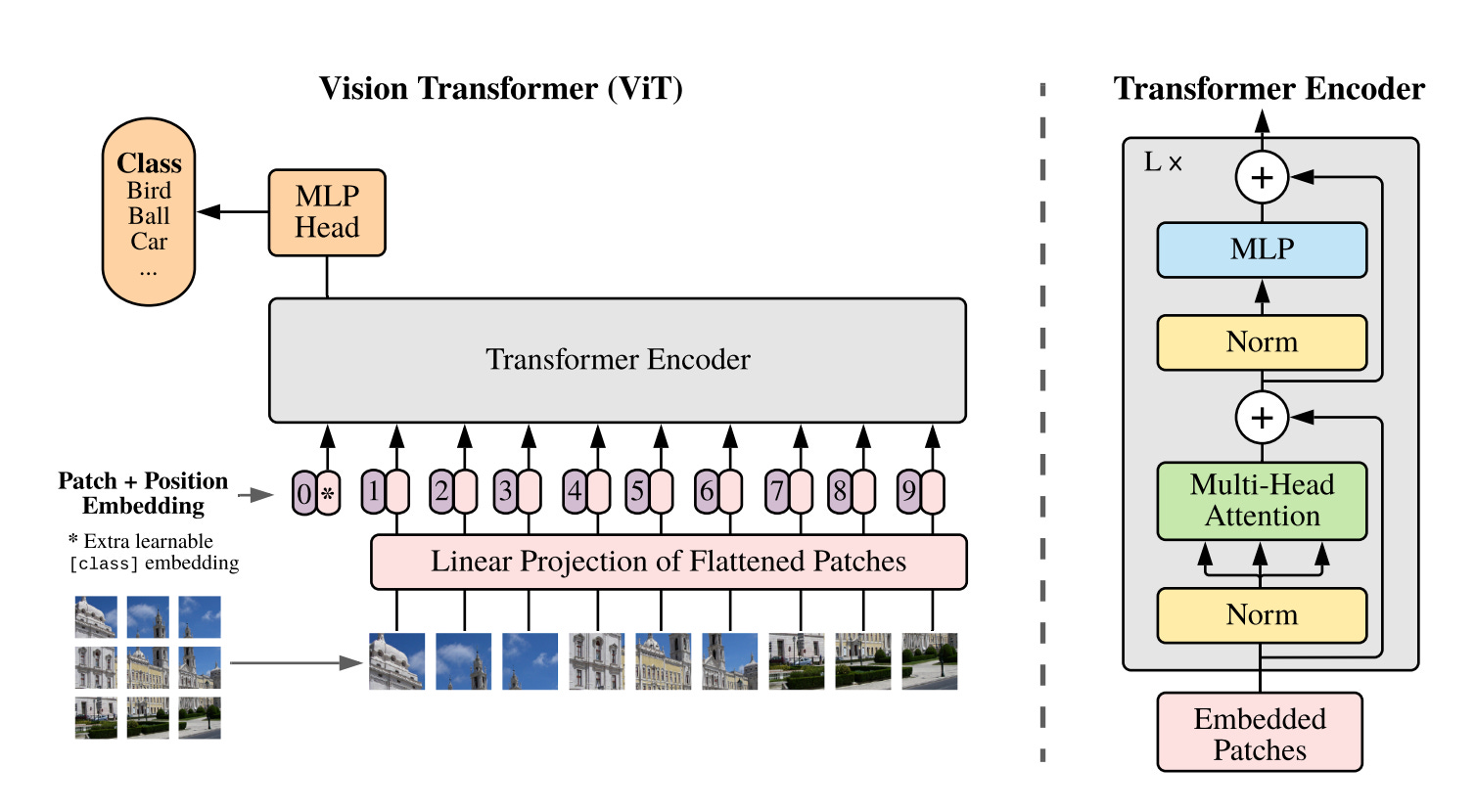
CLIP generates image embeddings using a deep neural network as its vision encoder. The vision encoder is typically a Convolutional Neural Network (CNN) (e.g., ResNet) or a Vision Transformer (ViT).
Here are the 5 steps for how CLIP generates image embeddings:
Preprocess the Image
Resize and crop the image to a fixed size (e.g., 224x224).
Normalize pixel values to match the training distribution.
Patch or Feature Extraction
If using a Vision Transformer (ViT): Divide the image into small patches (e.g., 16x16) and flatten them into vectors.
If using a ResNet (CNN): Apply convolutional layers to extract hierarchical image features.
Add Positional Information (ViT)
Add positional embeddings to the patch embeddings to encode spatial relationships.
(Skip this step for CNNs like ResNet, which inherently encode spatial information.)
Pass Through the Vision Encoder
Use a series of Transformer layers (ViT) or convolutional layers (ResNet) to process the image and extract a global feature vector.
Extract a Global Feature Vector
For ViT: Use the output of the special [CLS] token as the image embedding.
For ResNet: Use a pooled feature vector from the final convolutional layer.
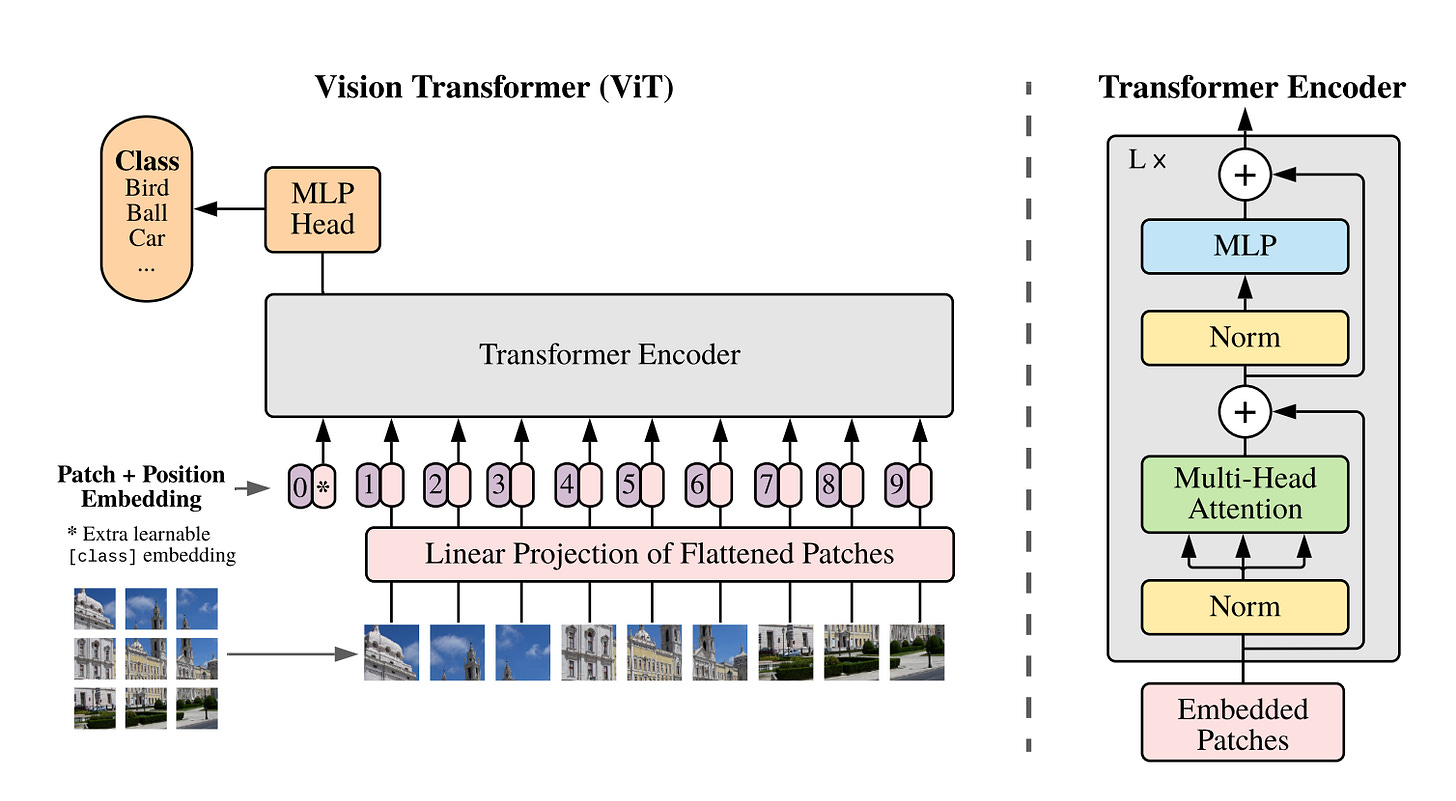
Vision Transformer architecture which is used as one option in the CLIP image encoder. Reference: An image is worth 16*16 words paper, Dosovitskiy et al 2020.
Step 3: CLIP matches the text and image embeddings
Project Text and Image Embeddings: Text and image embeddings are projected into a shared embedding space using linear layers.
Normalize Embeddings: Both embeddings are normalized to unit length for cosine similarity calculation.
Compute Cosine Similarity: Cosine similarity is calculated between all text and image embeddings in a batch.
Contrastive Loss: A contrastive loss encourages high similarity for correct pairs and low similarity for incorrect pairs.
Backpropagation: The model parameters are updated through backpropagation to improve alignment.
Output Aligned Embeddings: The trained model outputs aligned embeddings for text and images in the shared space.
5. CLIP in action
I ran an open source CLIP model provided by OpenAI.
The model is called: openai/clip-vit-base-patch32
The code is borrowed from this Github repository titled “Hands on Large Language Models”: https://github.com/HandsOnLLM/Hands-On-Large-Language-Models
Here are the results obtained:

Images (Columns):
The columns represent three images: a puppy in the snow, a pixelated cat, and a supercar on a road with a sunset in the background.
Text Descriptions (Rows):
The rows represent the textual descriptions associated with the images:
"A puppy playing in the snow."
"A pixelated image of a cute cat."
"A supercar on the road with the sunset in the background."
Similarity Matrix (Values):
Each cell in the matrix shows the cosine similarity between a text embedding (row) and an image embedding (column).
Higher values (e.g., 0.33, 0.35, 0.31) indicate stronger alignment or relevance between the text and the image.
Here is the analysis of the results:
First Row (Puppy Description):
The text "a puppy playing in the snow" aligns best with the image of the puppy (similarity: 0.33), confirming the CLIP model's correct matching ability.
Second Row (Pixelated Cat Description):
The text "a pixelated image of a cute cat" aligns most strongly with the cat image (similarity: 0.35), which is consistent with expectations.
Third Row (Supercar Description):
The text "a supercar on the road with the sunset in the background" aligns most strongly with the car image (similarity: 0.31), again demonstrating correct alignment.
6. Conclusions
I hope this article gave some intuition as to how multimodal embedding models like CLIP work.
Even as I finish writing this article, the idea of an image being present in a vector space is very counter-intuitive to me!
Here is the link to the original CLIP paper: https://arxiv.org/pdf/2103.00020