
Technical Deep-dive into Gemma3 🤖: Next generation models for small and mid range tasks
Gemma3 is a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. Much efficient and performant than previous and other Larger LMs.

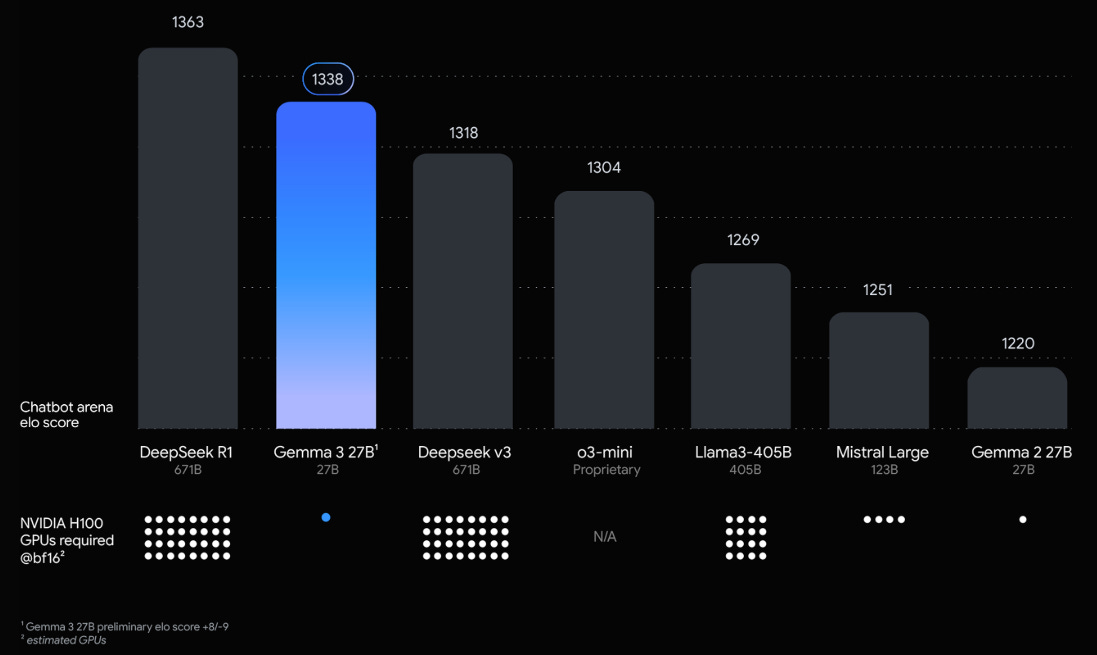
Table of content
Introduction to Gemma family
Gemma & Gemma 2 – Brief Overview
Gemma3 (Third generation) : Technical deep-dive
Training methodology
Outcome/Results
Thoughts
Conclusion
Introduction to Gemma family

Gemma & Gemma 2 – Brief Overview
Google DeepMind's Gemma and Gemma 2 are lightweight AI models optimized for efficiency, designed as open-weight alternatives for AI research and deployment in real-world applications.
Overview of Gemma (First Generation)

The original Gemma was released in February 2024 by Google DeepMind. It was designed for low-latency inference on consumer GPUs (NVIDIA RTX 30/40 series) and Google Cloud TPUs, against the conventional large language model trend
The training pipeline and architecture is roughly inspired by Gemini, but optimized for efficiency. The Gemma is purely a Language only model focussing on language generation and coding like tasks.
It comes in two distinct variants
Gemma 2B → ~2 billion parameters, designed for local AI applications.
Gemma 7B → ~7 billion parameters, offering better reasoning and language capabilities.
On the architecture level,
It is a Decoder-only Transformer (similar to LLaMA, Falcon, and GPT models) and uses Google's SentencePiece tokenizer. Looking at the available architecture choices at that time, Gemma probably uses a MoE as backbone. To make the inference fast and efficient they used optimized Rotary Position Embeddings (RoPE) (efficient sequence modeling) and Flash Attention 2 for lower memory overhead. It also Supports 4-bit and 8-bit quantization for consumer hardware. The entire optimization/training is performed over TPU v4/v5 and NVIDIA H100 GPUs.
Result wise, Gemma works almost on par with competitive with models like LLaMA 2 and Mistral-7B at similar parameter sizes. Also it is much efficient for fine-tuning and adapter-based learning (LoRA, QLoRA), hence making it optimal for downstream tasks.
Overview of Gemma 2 (Second Generation)

Gemma2 is the next in line to its predecessor focusing on better efficiency and scaling. It is specially designed for longer context lengths and more efficient inference hence targetting industrial use-cases. Authors improved model alignment with better pretraining (knowledge distillation) and post-training process (on-policy/RL based distillation); these policies could be different and adhering to different objectives. One interesting technique they utilized along with on-policy tuning is called as Warp, which simply is a model merging technique.
They perform merging in three distinct stages
1. EMA (Exponential Moving average) based model merging during RL fine tuning.
2. SLERP (Spherical Linear Interpolation) after tuning multiple model across fine-tuning policies.
3. LITI (Linear interpolation Towards initialization) is utilised in final step for a more robust and stable model.
Similar to its predecessor, Gemma2 also comes in multiple flavours like Gemma 9B and 27B, both were really powerful and optimized for scalable inference. Also, both are available as base and instruction-tuned variants.
For architecture improvements,
It uses Grouped Query Attention (GQA) for faster inference and a extended context window (~8K or 16K tokens) for better long-form reasoning.

MQA vs GQA vs MHA (source : https://www.linkedin.com/posts/thegenaipod_thegenaipod-verticalserve-activity-7209271885434384384-iF3n) Furthermore, the authors proposed things like soft-capping instead of hard truncation over logits which stabilizes training.
It also leveraged weight-sharing optimizations for better GPU/TPU performance and more robust training corpus (less bias, more diverse data).

Gemma2 showcases really strong reasoning abilities in coding and logic-based tasks beating counterparts like llama3 and grok1.
Both of these models are highly optimised architecture with multiple small yet effective training and tuning technique. But, as we can see the gemma2 architecture solved a lot of issues with previous Gemma architecture and we expect from the next in family the Gemma3.
Gemma3 (Third generation) : Technical deep-dive

Overview
It is a family of multiple models available across variety of parameter sizes, like, 1B, 4B, 12B and 27B. It supports context length of 128k tokens.
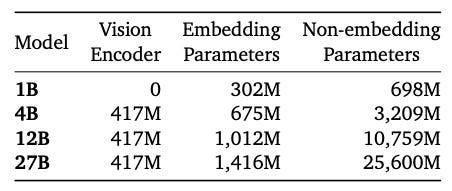
Unlike the previous variants it is a multi-modal system, simply put it is a high performance Visual-Langauge model. Also, Gemma3 is born out of same research stack as that of gemini and even uses its tokenizer.
The primary advantage of this architecture is the smaller size allows possibility of fine-tuning on specific datasets. The tuning could be performed on free-tier colab using vertex.ai or unsloth.
Interestingly, though it is much smaller in size, it is still able to beat much larger models like DeepseekV1 (which is around 671B).
Now we have gone through a brief overview of Gemma3, let's understand it's components and the training process.
Architecture
Gemma3 is also a decoder only architecture (basically the GPT head) with most of the components similar to previous two models.
Interleaving attention blocks: Instead of performing full attention for each block, authors alternated between local (sliding window) and global (full) attention in 5:1 manner (5 local-1 global). The 5:1 local-to-global ratio (used in Gemma 3) has minimal impact on perplexity compared to the 1:1 ratio in Gemma 2. Also the sliding window size reduction for local attention layers doesn’t significantly affect perplexity. For further tests, Interleaving attention helps in reducing KV cache memory overhead from 60% (global-only) to below 15% with 1:3 ratio and a 1024 sliding window.

difference between full vs sliding window attention (source : https://huggingface.co/blog/gemma3) For visual modality they utilized SigLIP which is a 400M params model (quite famous now), simply put it is exactly the CLIP architecture but with sigmoids instead of softmax, hence optimizes global alignment instead of local/relative comparison. The input size in vision encoder head is (896x896).
The Vision head is tuned using data from visual assistant tasks. It also utilizes pan-and-scan during Inference. This is a simple windowing approach where the image is broken into non-overlapping crops if the image size is more than (896x896)/non-square aspect ratio (results in artifacts while performing visual understanding), each of this crop is then fed to the model. The entire module could be disabled for faster inference.

Training methodology
Pre-training (Stage 1)
Training Data: It uses a larger token budget than Gemma 2 (e.g., 14T tokens for 27B model). The data includes both text and images, with an increased focus on multilingual data using monolingual and parallel datasets. Also, it applies filtering techniques to remove unsafe or sensitive data and prevent recitation. Instead of training from scratch with 128K tokens, models were pre-trained on 32K and later scaled to 128K via RoPE rescaling. The RoPE base frequency for global self-attention increased from 10K to 1M, improving long-context generalization.
Uses quality reweighing to reduce low-quality data. They utilized GQA with pre-norm and post-norm for more stable training, also, instead of using the soft cap introduced in gemma2 they replaced it with QK norm. Performance on standard benchmarks (science, coding, factuality, multilinguality, reasoning, and vision) improved over Gemma. So, multilinguality was a key focus, though probe contamination remains a concern.
Tokenizer: Gemma3 uses tokenizer which is same as Gemini 2.0’s SentencePiece tokenizer (262K vocabulary) with split digits and byte-level encoding, improving balance for non-English languages.
Distillation: Samples 256 logits per token, with students learning teacher distributions using cross-entropy loss. Non-sampled logits are set to zero and renormalized.
Quantization: Gemma3 inherently provides support for per-channel int4, per-block int4, and switched fp8 formats for compatibility with open-source inference engines (e.g., llama.cpp). They also provide access Quantized model post-traiend through QAT (Quantization aware training) over a small epoch number.
Compute Infrastructure (important)
- It uses TPUv4, TPUv5e, and TPUv5p, optimizing model training efficiency.
- Vision encoder embeddings are precomputed to reduce training cost.
- Optimizer state is sharded using ZeRO-3 (which is an optimization techniques to optimize model training by fully sharing weights, gradients and other optimizer states across multiple GPUs/TPUs), with multi-pod training via Pathways.
- Implements Jax's "single controller" paradigm and uses the GSPMD partitioner and MegaScale XLA compiler for large-scale training. Jax’s single controller makes sure all devices work together, GSPMD splits up the work efficiently, and MegaScale XLA makes sure computations/tasks are done in the best way possible for large-scale model training.
Instruction-Tuning (Stage 2)
Pre-trained models are instruction-tuned using an enhanced post-training approach which relies on improved knowledge distillation and reinforcement learning (RL) based finetuning. In ablations the authors pointed out that small teachers perform better in early training stages, but large teachers are superior over longer training horizons which is mostly due to complexity of manifold approximated by these models. Think of it like a low resolution map (smaller model) vs high resolution map (larger model) approximation, low-res is easy to approximate but less informative, the higher-res is opposite way around.
Knowledge distillation is done from a large instruction-tuned (IT) teacher model whereas RL finetuning is performed using enhanced versions of BOND, WARM, and WARP methods. They also Includes data that improves attribution, hedging, and refusals to reduce hallucinations.
Tokenizer Adjustments : Here the authors optimize tokenizer to perform task specific tokenization. Gemma3 explicitly requires a [BOS] (beginning-of-sequence) token for both PT and IT models. Though tokenization tools like Flax can automate adding [BOS] with `add_bos=True`. Also there is difference in formatting of tokenizer, both share the same tokenizer but differ in output tokens, Pre-trained (PT) models use <eos> at the end of the generation whereas Instruction-tuned (IT) models use <end_of_turn>.
Outcome/results
On LMSys Chatbot Arena, Gemma 3 27B IT reports an Elo score of 1339, and ranks among the top 10 best models, including leading closed ones. For understanding more about this benchmarks and more visit [here].

Scores really high on MMLU (67.5) and LCB (29.7). Interestingly it falls behind in simpleQS benchmark (~10), although better than gemma2 but relatively less than gemini1.5.

For multi-modal benchmarks, the models achieve strong results in document understanding (DocVQA: 85.6 at 27B), real-world image reasoning (ReMI: 44.8 at 27B), and chart analysis (ChartQA: 76.3 at 27B), indicating their ability to process complex visual and textual data.
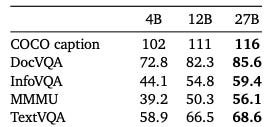
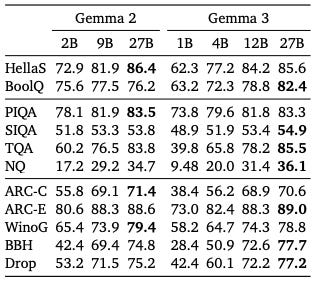
Gemma3 also performs really well in benchmarks like HellaSWAG, PIQA, ARC, suggesting strong reasoning and factual knowledge retrieval capabilities.
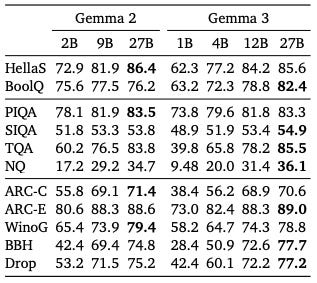
Most importantly it falls into paretos sweet spot, inspite of being a multi-modal architecture, simply put, it is the condition where a small model/parameters lead to strong performance (check the first diagram in the article), this makes it suitable for multiple downstream tasks.

source. : https://huggingface.co/blog/gemma3


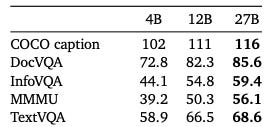

Thoughts
Gemma3 proves how a simple, efficient and scalable pipeline leads to a model that can beat even the larger architectures.
It performs really well with image understanding and OCR like tasks, all thanks to the alignment tuning for SIGLIP.

Something I would like to see in upcoming models is the usage of LDMs (Language diffusion models) instead of pure Decoder-only/auto-regressive architectures, also if they could make a unified architecture similar to janus-pro hence convering both image understanding and generation.
Model merging across multiple policies is really interesting to think about, but, what if we instead of simpler deterministic operators as in SLERP, we use Hyper-network which can dynamically merge the weights.
A great add on for these architectures would be addition of test time tuning, given their relatively smaller size hence already faster inference; which we could trade-off during inference for better results, they would prove to be ideal for such tasks.
One thing that always stands out from Google papers is their beautiful usage of TPUs and their distributed training pipeline (check out the infrastructure part which we discussed).

Conclusion
This article is presumably shorter than others; mostly due to the simplicity of the overall paper. I refrained from explaining about the infrastructure part as I am still in the exploration stage there. We started from the older generation Gemma architecture and understood how they work. From there we moved to Gemma3 where we talked about the architecture, the training pipeline (composed of Pre-training and post-training stage), from there we talked about multiple quantization schemes in which Gemma3 is available, we very briefly touched upon the compute infrastructure used for training and finally we ended with the outcomes/results.
With this we come to the closure of this article, the actual paper talks more in-depth about the methodologies and mechanism they used (and I would encourage you to go through it), but, in general this article would serve as basic building block/first hand introduction for Gemma3 paper (and the prior models in Gemma family).
Please go through the papers/Technical reports for further nuances and details,
📝Gemma report : https://arxiv.org/abs/2403.08295
📝Gemma2 report : https://arxiv.org/abs/2408.00118
📝 Gemma3 Report : https://arxiv.org/abs/2503.19786
That's all for today.
Follow me on LinkedIn and Substack for more insightful posts, till then happy Learning. Bye👋