


The necessary (and neglected) evil of Large Language Models: Tokenization
Why we should pay more attention to tokenization and why it is more important than you think.

This article is heavily inspired by Andrej Karpathy’s video on building tokenizers from scratch. You can watch the video here: Link.
(1) The relay race of two athletes:
Ever since I understood the importance of tokenization, I have started looking at Large Language Models (LLMs) in a completely different light.
My earlier understanding of LLMs was that we have a huge corpus of data on which we train gigantic neural network architectures for the next token prediction task. This process works beautifully not just for predicting next tokens, but for a wide range of other tasks like text summarization, code completion, grammar checking, storytelling and whatever tasks you currently use ChatGPT for.
If I am pre-training an LLM from scratch and it’s not working well, here were my usual suspects:
Not enough training data
Poor hyperparameter optimization
Poor inference strategies like temperature scaling, top_k sampling etc
Now I realize that there is one more suspect, which can play a major role:
Poor tokenization
Here is how Andrej Karpathy builds the schematic of the tokenizer + LLM:

First the tokenizer is trained on a dataset.
Every single sentence, words and characters are broken down into tokens and token IDs.
The token IDs are then passed to the Large Language Model (LLM).
Then the Large Language Model is trained on a dataset which might be completely different from the dataset on which the tokenizer is trained.
After the tokenization step, the LLM only sees the tokens. It never deals directly with text.
This sentence really hit me hard.
When we pre-train LLMs, the LLM is solely relying on the tokenized text.
If we mess up the tokenization, no matter how hard we try to pre-train, our LLM will always lead to a poor performance.
That’s when I started thinking of LLMs as a relay race of two athletes:

No matter how good the second athlete (the LLM pre-training) is, we won’t win the race unless the first athlete (the tokenizer) is equally good.
(2) The atoms of Large Language Models (LLMs)
Tokenization is the process of translating strings into a sequence of tokens.
Tokens are fundamental units (atoms) of LLMs.

Tokens are converted into token IDs and then the second athlete starts.
So when we think about tokenization, the real question which we should be asking ourselves is this:
“How do we convert a given piece of text to tokens?”
(3) The art of tokenization: Tale of the egg
Tokenization is way more tricky than it sounds.
Let’s look at some examples of how gpt-2, gpt-3.5 and gpt-4o tokenize variations of the word “egg”

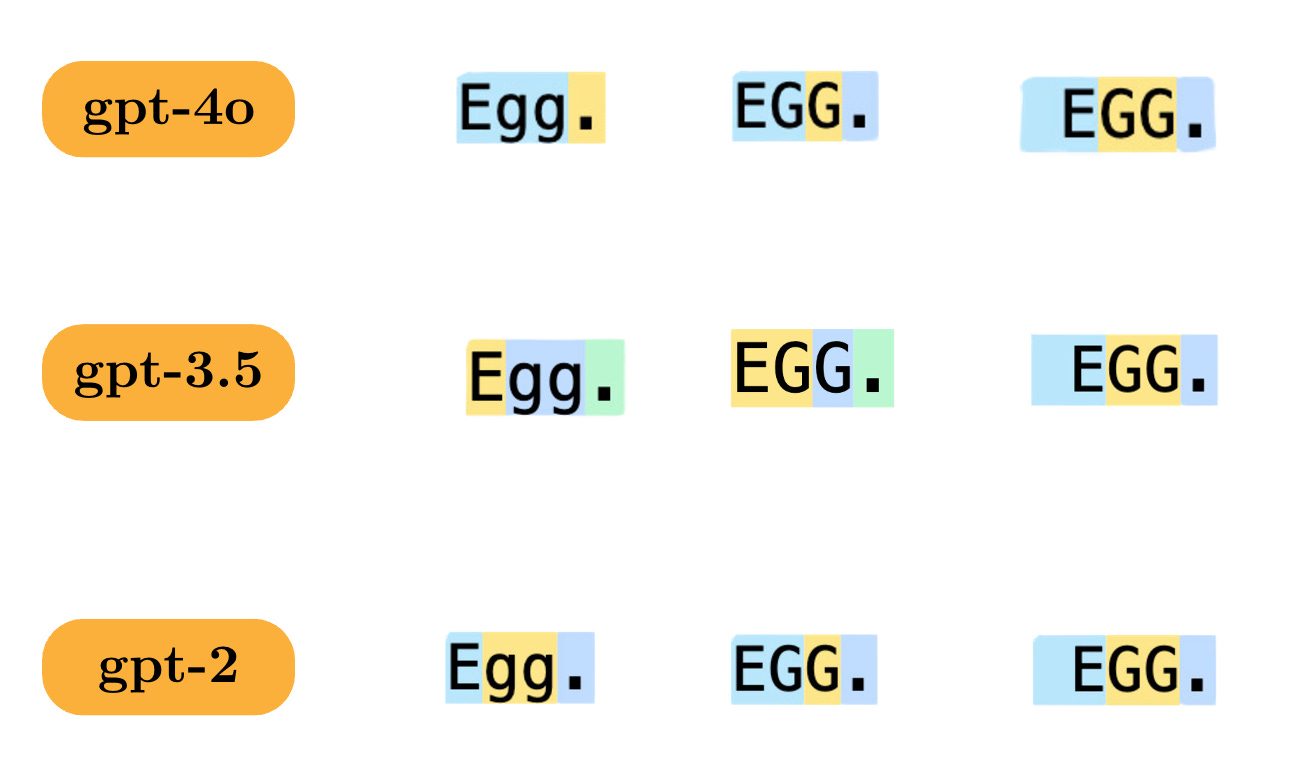
As we can see, there are a lot of variations in which the simple word is tokenized as we go from gpt-2 to gpt-3.5 to gpt-4o.
This shows 2 things:
After tokenization, the LLM has no clue that “egg”, “Egg”, “EGG” all mean the same thing. It has to learn that during pre-training.
OpenAI is clearly changing the way it is doing the tokenization itself as we advance from gpt-2 to gpt-3.5 to gpt-4o. I’ll make a separate blogpost on tokenization strategies and tokenization training algorithms.
(4) The art of tokenization: Lost in translation
One great example to showcase the difficulty of tokenization is using “non-English” languages.
Hindi is an Indian language spoken by more than 500 million people.
I took a sentence in Hindi which translates to “My Prime Minister is Narendra Modi”
Here is how the sentence looks like in Hindi:
मेरे प्रधानमंत्री नरेंद्र मोदी हैं।
I then saw how different versions of GPT tokenized this sentence.

Here are several things we can learn from the above image:
The number of tokens needed for this sentence was 65 for gpt-2. After that, it steadily decreased to 35 tokens for gpt-3.5 and only 7 tokens for gpt-4o.
The number of tokens needed by gpt-4o was 90% less than gpt-2.
What is the reason for this much change? What did OpenAI do differently from gpt-2 to gpt-4o.
Although the details have not yet been revealed by OpenAI, it is very likely that the tokenization training data for regional languages increased a lot as we went from gpt-2 to gpt-4o.
To form tokens, we need to apply tokenization algorithms such as Byte Pair Encoding (BPE) or SentencePiece to a dataset.
Application of these algorithms to a dataset is called training the tokenizer.
During tokenizer training, characters which appear together very frequently are merged and added to the vocabulary.
That’s how the vocabulary of tokens grows in size.
While training the dataset for gpt-2 tokenization, what might have happened is that OpenAI did not have consider enough data for Hindi language.
Since the data is very limited, characters won’t frequently appear together and hence, they won’t be merged.
As a result, the vocabulary of tokens for Hindi language remains very limited for gpt-2. The vocabulary remains mostly at the character level.
If you inspect the tokens from gpt-2 in the above figure closely, you will observe that they are individual characters. There are very few “merged” characters as tokens.
We will explore the tokenization algorithms “Byte Pair Encoding” and “SentencePiece” in a latter blog. There is too much information to be added about these algorithms, and that will increase the size of this newsletter edition by a lot.
(5) The art of tokenization: Careful with code
It was a very well known fact that GPT-2 was not really good at Python coding.
We can understand a bit more if we look at the tokenization of Python and how it progressed from gpt-2 to gpt-3.5 to gpt-4o.
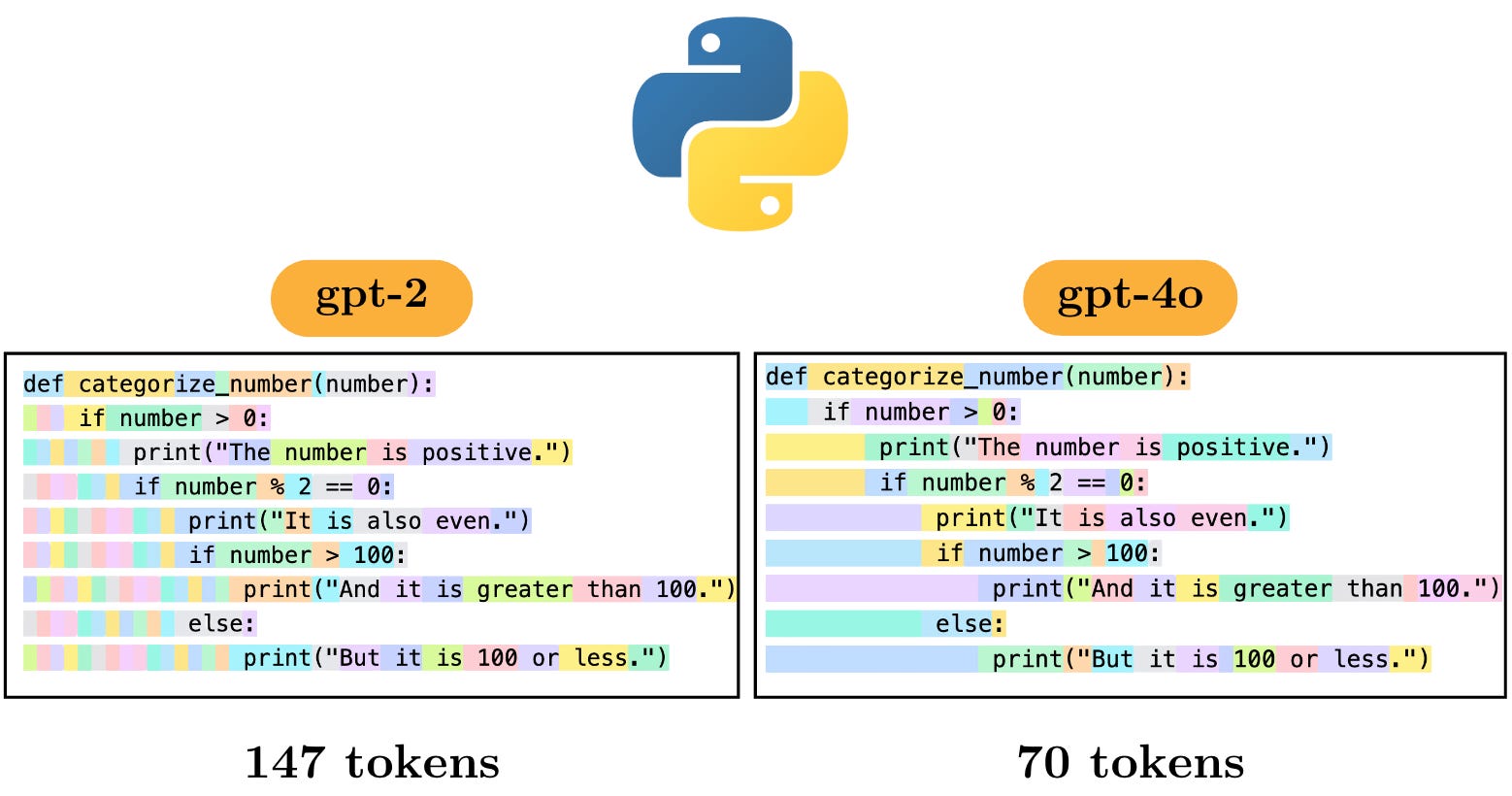
Here is what we understand from the above figure:
The same Python code took 147 tokens for gpt-2 and only 70- tokens for gpt-4o.
The major difference seems to be in the indentations.
What gpt-2 seems to be doing is assigning a separate token to each indentation. gpt-4o on the other hand, allocates very less number of tokens to indentations.
Each indentation in gpt-2 is assigned a token ID of “220”.
In gpt-4o, many of the small indentations are merged. That significantly reduces the number of tokens for indentations.
Why does reducing the number of tokens for indentations improve Python performance for gpt-4o over gpt-2?
Every token the model uses to represent whitespace or indentation is one less token available for representing meaningful code elements such as keywords, variable names, and function calls.
By compressing multiple indentation spaces into fewer tokens, gpt-4o frees up a larger portion of its token budget for the actual logic and structure of the program.
This means gpt-4o can handle more lines of code within the same token limit, increasing its capacity to grasp context and maintain continuity.
Here is the reason why gpt-2 performs poorly on Python code:
When each indentation space is treated as a separate token (as in gpt-2), the model effectively ends up with sequences of repetitive, low-information tokens. These tokens consume mental “bandwidth,” potentially making it harder for the model to understand patterns in the code structure.
(6) The art of tokenization: Maths is tough for a language model

Why is it so hard for GPT-4o to do a 5 digit multiplication?
You might have seen GPT models making a lot of mistakes with maths.
The reason might not be in the training of the LLM, but more related to the tokenizer.
When training a tokenizer from scratch, you take a large corpus of text and find the minimal byte-pair encoding for a chosen vocabulary size.
This means, however, that numbers will almost certainly not have unique token representations. "21" could be a single token, or ["2", "1"]. 143 could be ["143"] or ["14", "3"] or any other combination.
In essence, when the LLM is seeing numbers, it is not seeing numbers like humans do. Humans learn to understand numbers in terms of decimal systems. LLMs have no clue about the decimal system when they are looking at numbers.
For example, when GPT-4o looks at the number 54 and 72, it does not understand how they are related to each other in any way. For GPT-4o, these are just separate tokens!

Hence, the model cannot use a normal addition algorithm when given a problem like 54 + 72 = 126 since every single one of these tokens are unique.
It works off pure memorization.
Essentially almost all two and most 3 digit addition and subtraction problems must be solved with memorization instead of a coherent and generalizable algorithm.
I will wrap up this blog post here. In conclusion, we learnt the following:
Tokenization is the necessary and often neglected component of Large Language Models (LLMs)
If we mess up the tokenization, no matter how hard we try to pre-train, our LLM will always lead to a poor performance.
Tokenization is an art and every LLM engineer needs to understand it. The way we tokenize text has profound effects on regional language performance, mathematics performance, coding performance and so many other applications I have not written here.
In the next blog post, we will learn how to implement tokenization training algorithms on a dataset. Stay tuned!
Thanks for your write-up, super informative!
If math is important, why is it not a common practice to force the tokenizer to split numbers into single digits? This should make it way easier to handle math related tasks. 🤔