
Tiny Recursive Model (TRM)
How does TRM work?

These days, we have LLMs which can do powerful tasks. These tasks can greatly vary from writing poetry, doing mathematics, suggesting jokes, doing complex reasoning, and symbolic tasks.
These LLMs have billions of parameters and are huge in size. They cannot fit on our computer and we have to use GPUs to run these models.
These LLM architectures are based on the Transformer block, which was invented in the year 2017. Since then, this architecture has become a boilerplate for refining LLMs, improving LLMs, and making them better either in the pre-training or post-training.
However, no one has paused to think that are these complex architectures optimized for all kinds of tasks that we have? For example, for coding tasks, a different architecture may be optimal for solving complex Sudoku puzzles, maybe an even simpler architecture is optimal.
Researchers are so fixated on using the traditional LLM architecture that we have stopped thinking from the fundamentals.
That is why when I came across this paper, I really liked the thought process of rethinking the architecture which can take us from the input to the output from scratch without being biased by something which has worked in the past.
Let us understand this paper of Tiny Recursive Model in complete detail.
Motivation:
Large language models are auto-regressive, which means that they generate one single token at a time. This is not very optimal because even if a single token is incorrect, it can render the entire answer to be invalid.
Let us take an example of a Sudoku puzzle:
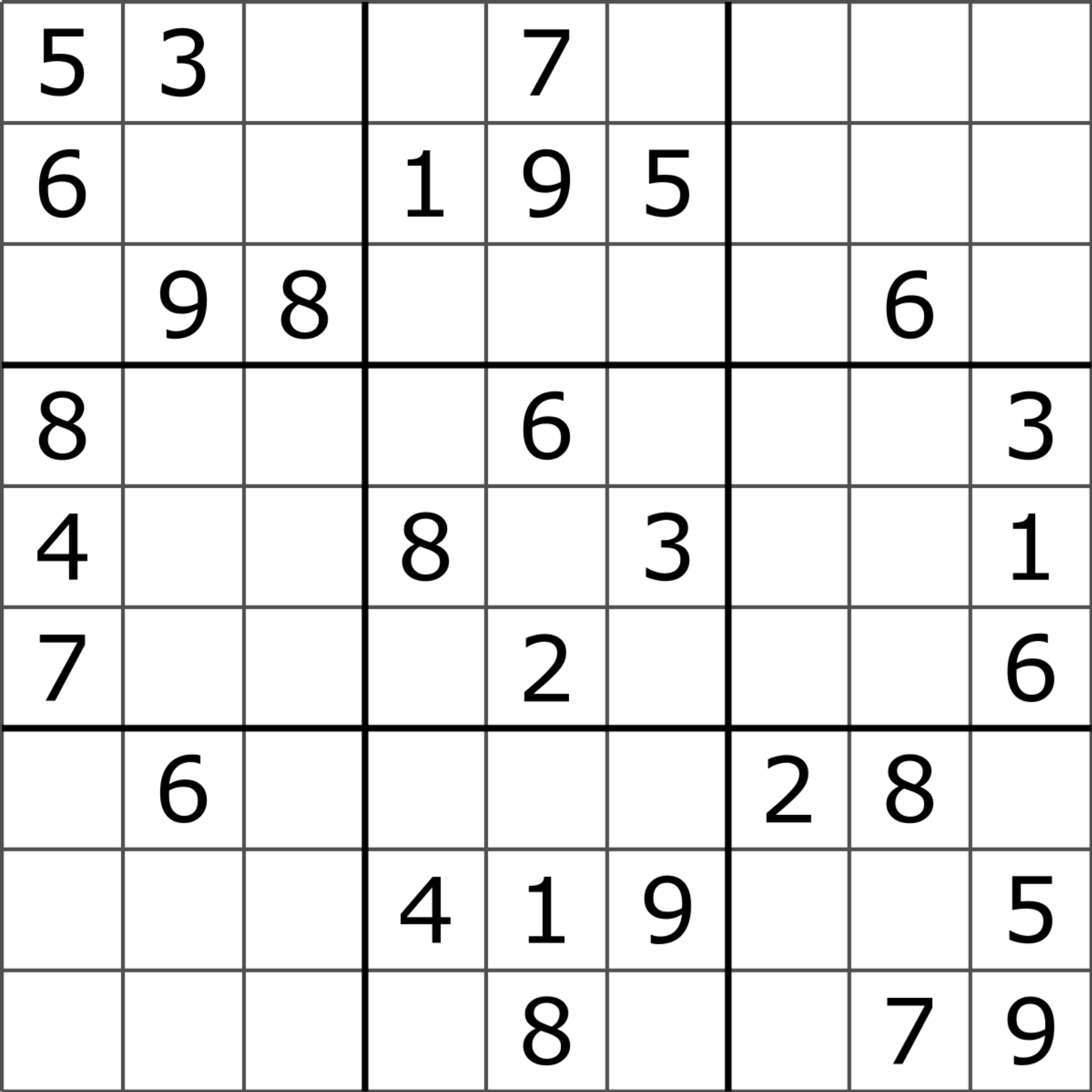
If we think of solving the Sudoku puzzle from scratch, we understand that as humans, we attempt a lot of trial and error before we get to the final answer.
The main intuition behind solving the puzzle is trying out various things and then seeing whether we can match all the rules of the puzzle. Auto-regression here does not come very naturally. It feels like we are trying to force-fit something which has worked in the past.
So now let us think about solving these kinds of problems from scratch.
Step 1: Recursion to improve reasoning
Let us think from scratch. To solve a Sudoku puzzle, I will first sit down and think, “OK, let me try the first approach (approach number one).” Then I will figure out that no, this is not correct. I will revise my approach and I’ll move to approach number two. Similarly, I will do a lot of recursions till I improve my approach to solving the problem.
This is exactly the first step for the tiny recursive model.
To improve our approaches from Approach 1, Approach 2, Approach 3, etc., we need to pass our approaches through some model.
Now, this model is not going to be the standard LLM, but we are simply going to connect two layers as shown below.
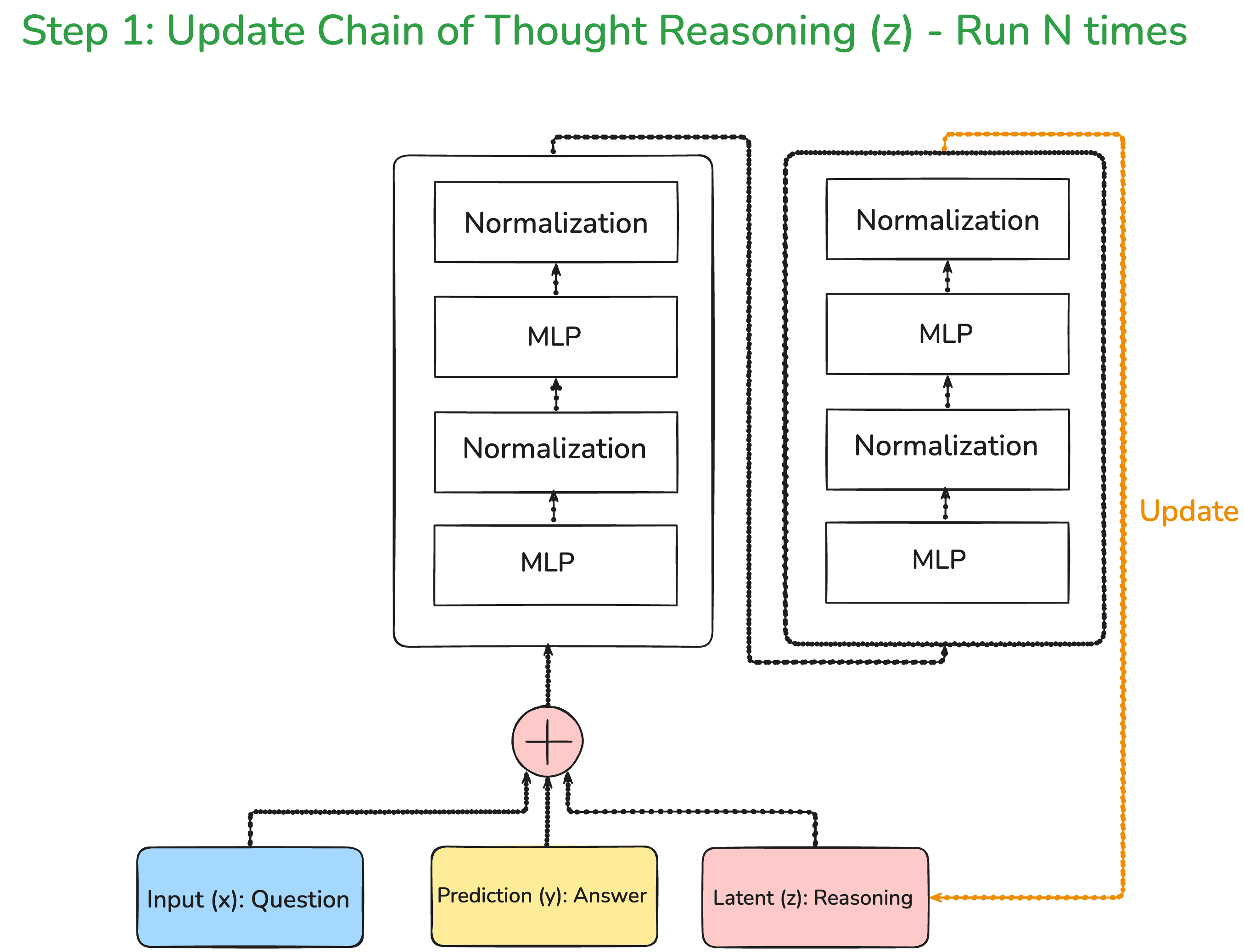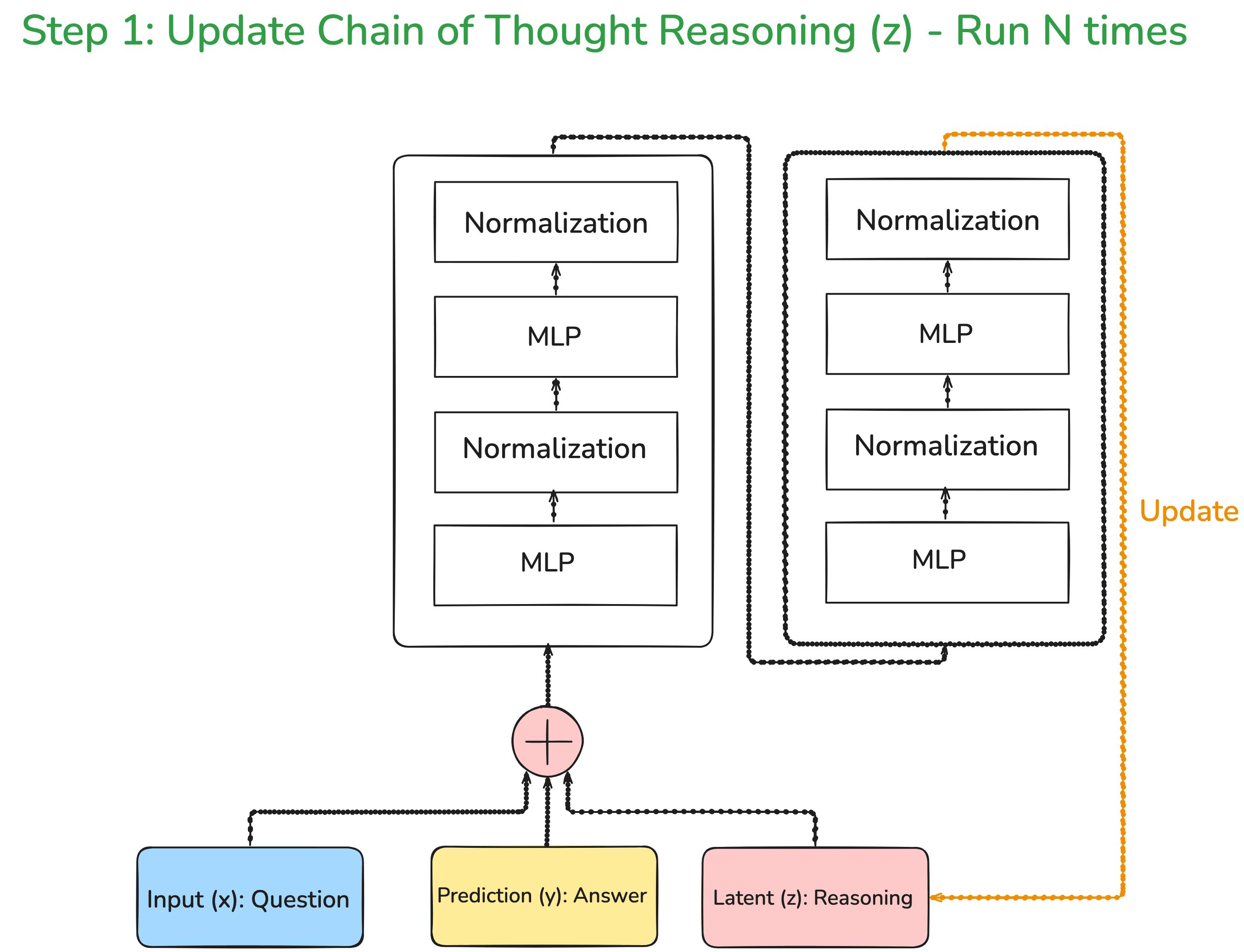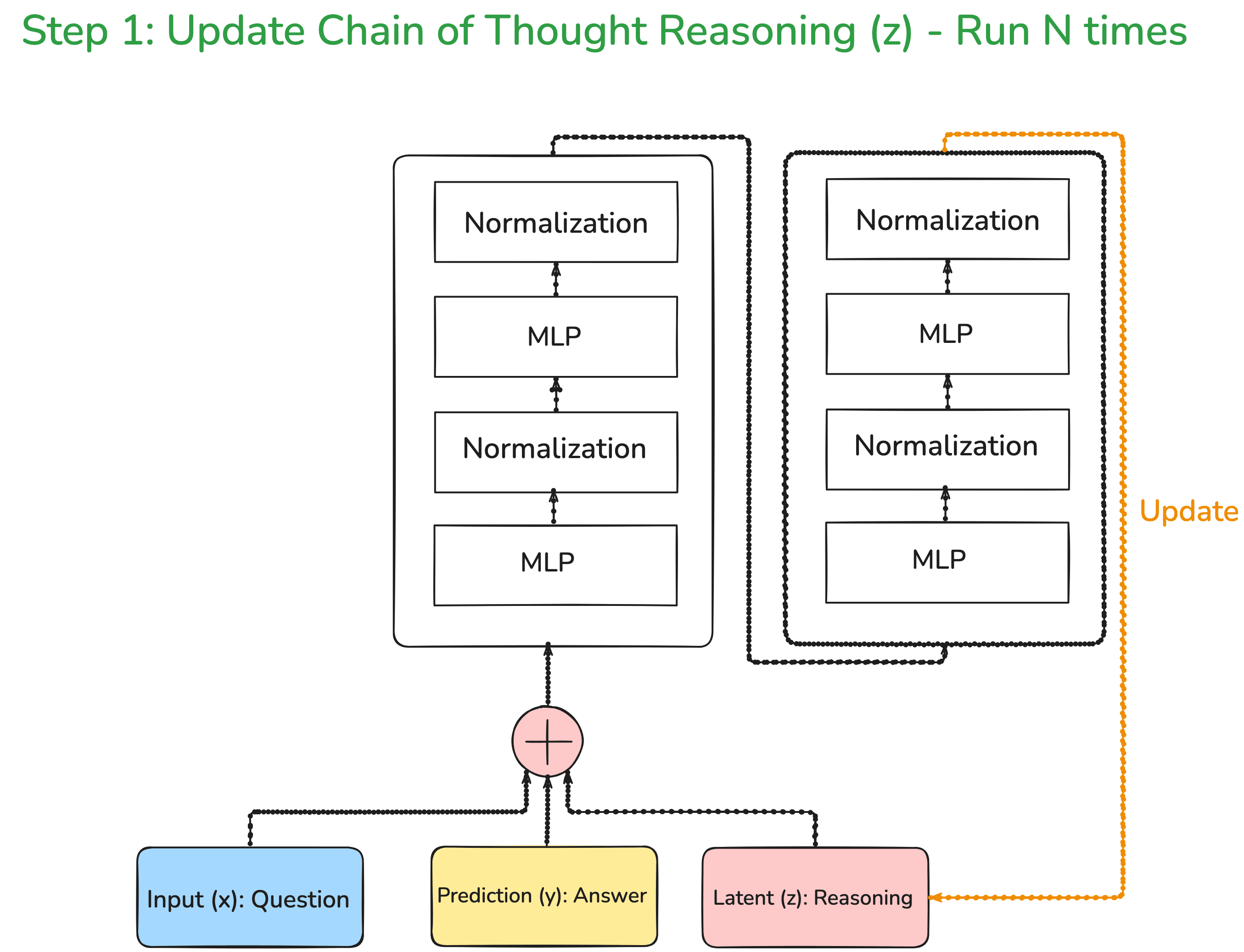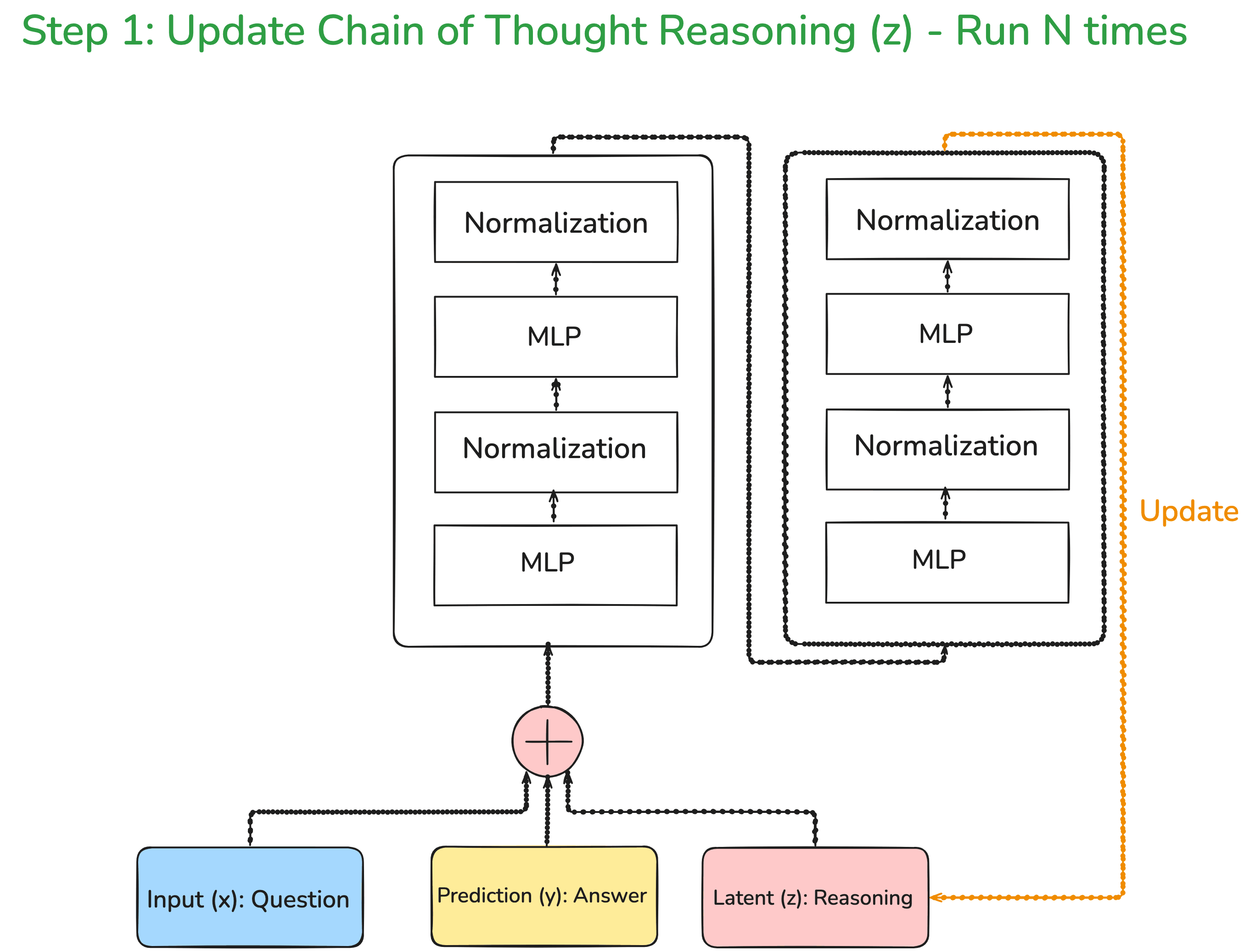
To understand the simplistic nature of this architecture, let us compare this with DeepSeek-v3. DeepSeek-v3 has 671 billion parameters and 95 transformer layers.
That is huge compared to this architecture, it simply has two layers and around 7 million parameters. That is an order of magnitude reduction of 10^6 parameters.
So, what is happening in the above architecture is that we are passing the question along with the answer and the reasoning. Every single time these three inputs are passed through the architecture, the reasoning keeps on improving. Here, it should be noted that the initial answer and reasoning are pretty random. As you pass through the network multiple times, your reasoning goes on improving.
Another point which is very key to note is that these improvements in the reasoning are not passed along through the backpropagation steps, which means that we are not going to update the weights of our neural network. We are simply going to improve the latent reasoning.
A very interesting intuition behind the latent reasoning is that it can simply be considered as a chain of thought. What we are doing is that we are improving the chain of thought before we come to the answer.
Now you might be thinking that the chain of thought is improving but the answer itself is not improving. How does that make sense? We will cover that in the next step of the tiny recursive model architecture.
Step 2: Improve the answer prediction
To improve the answer, we pass it along with the improved latent reasoning through the same network.
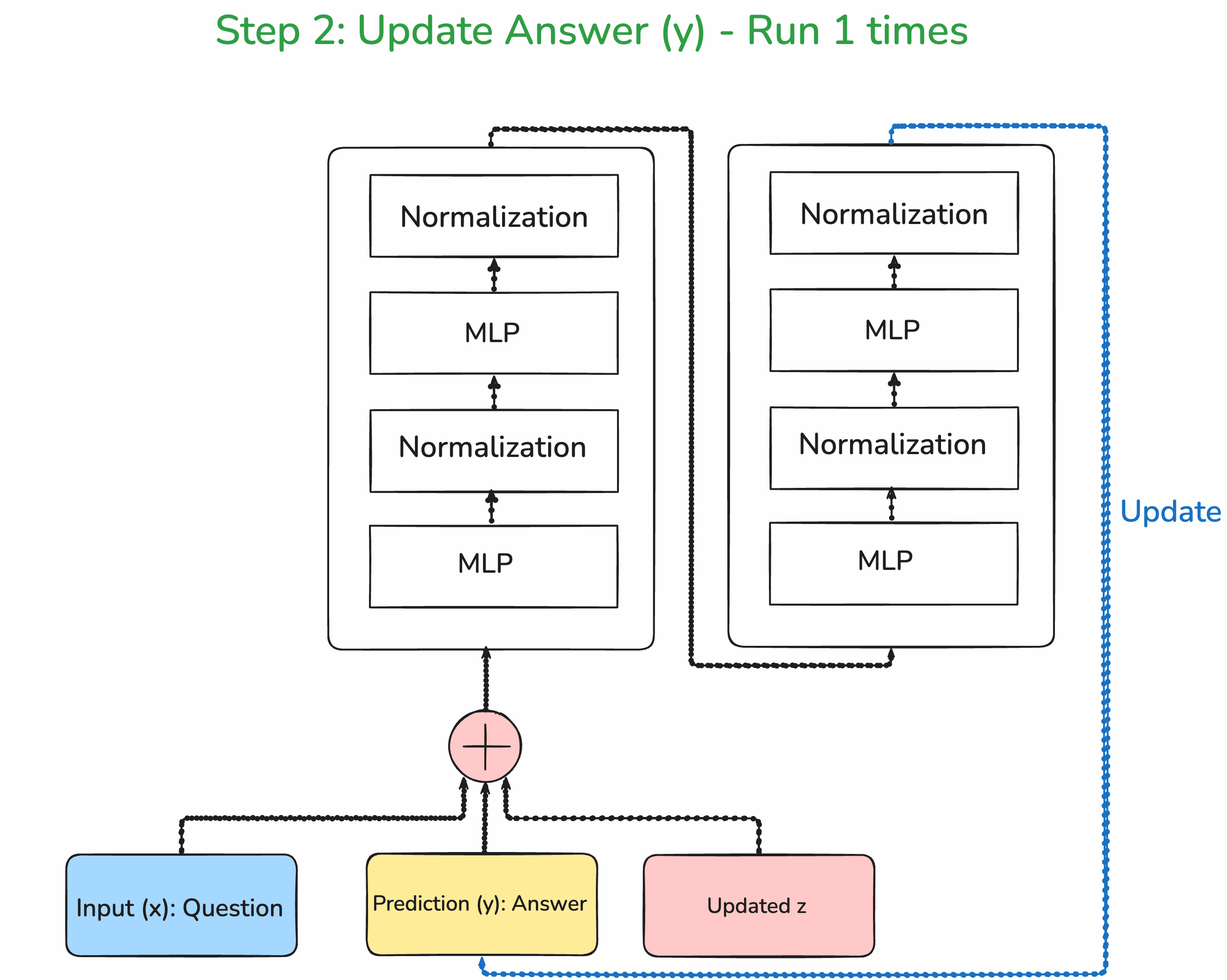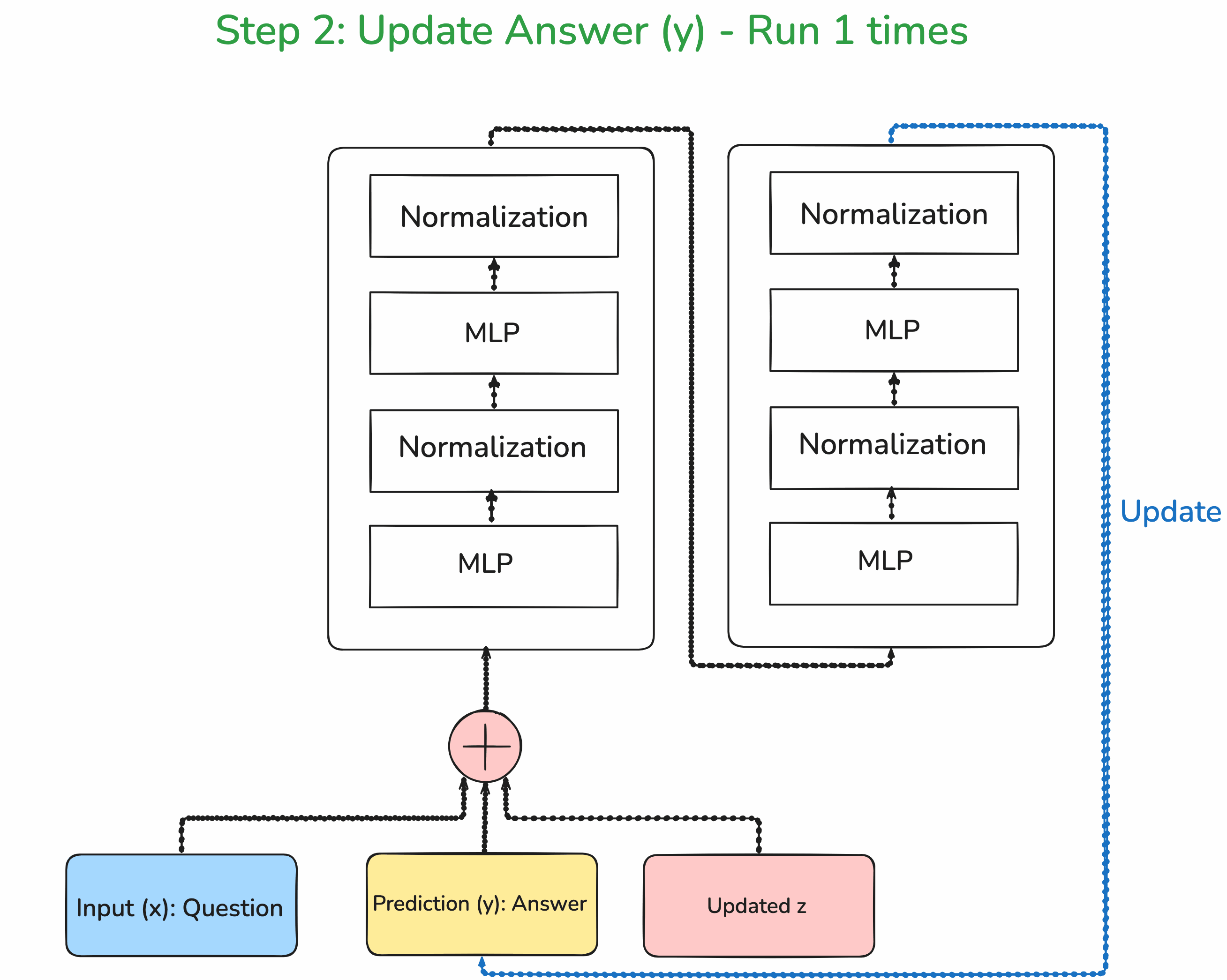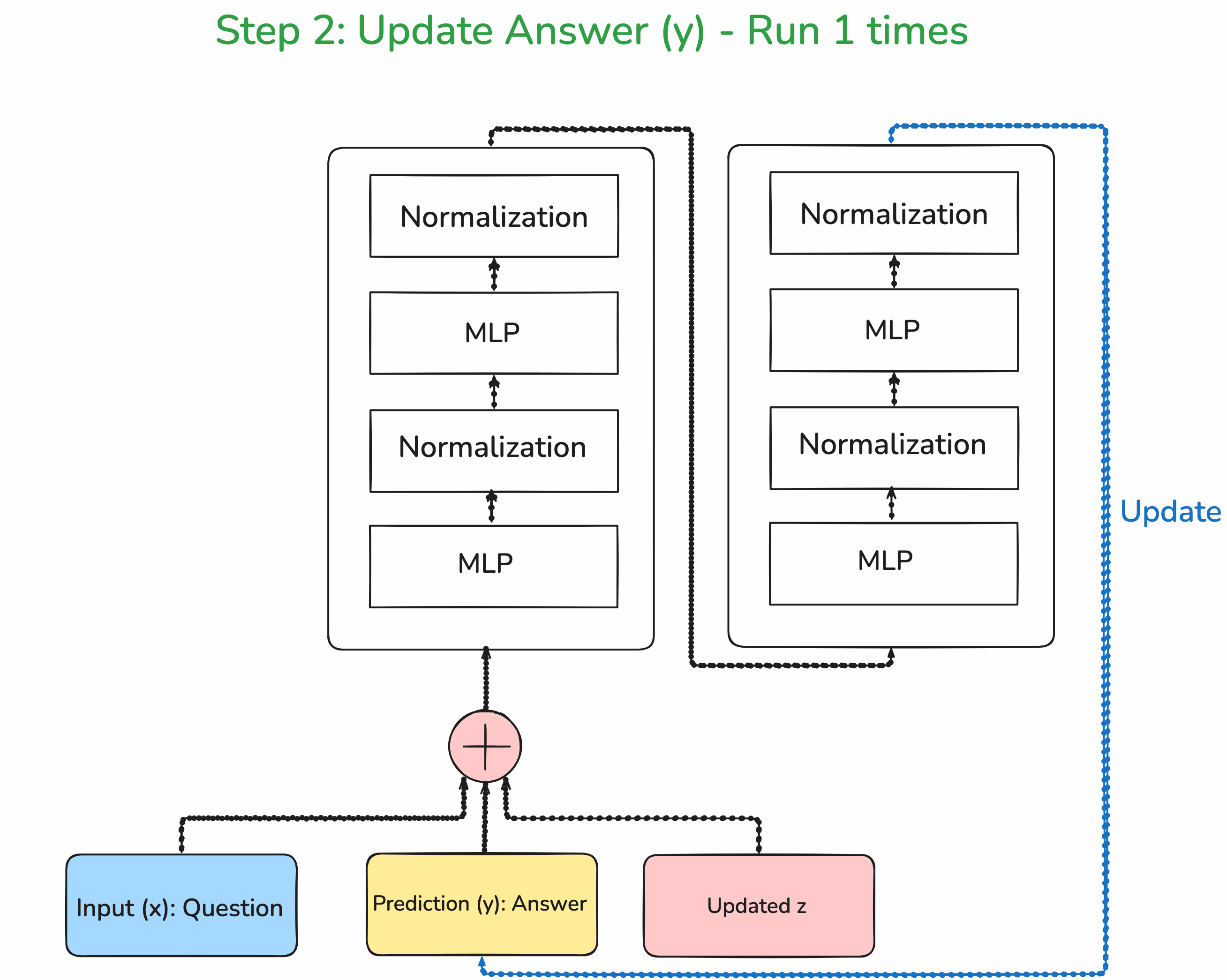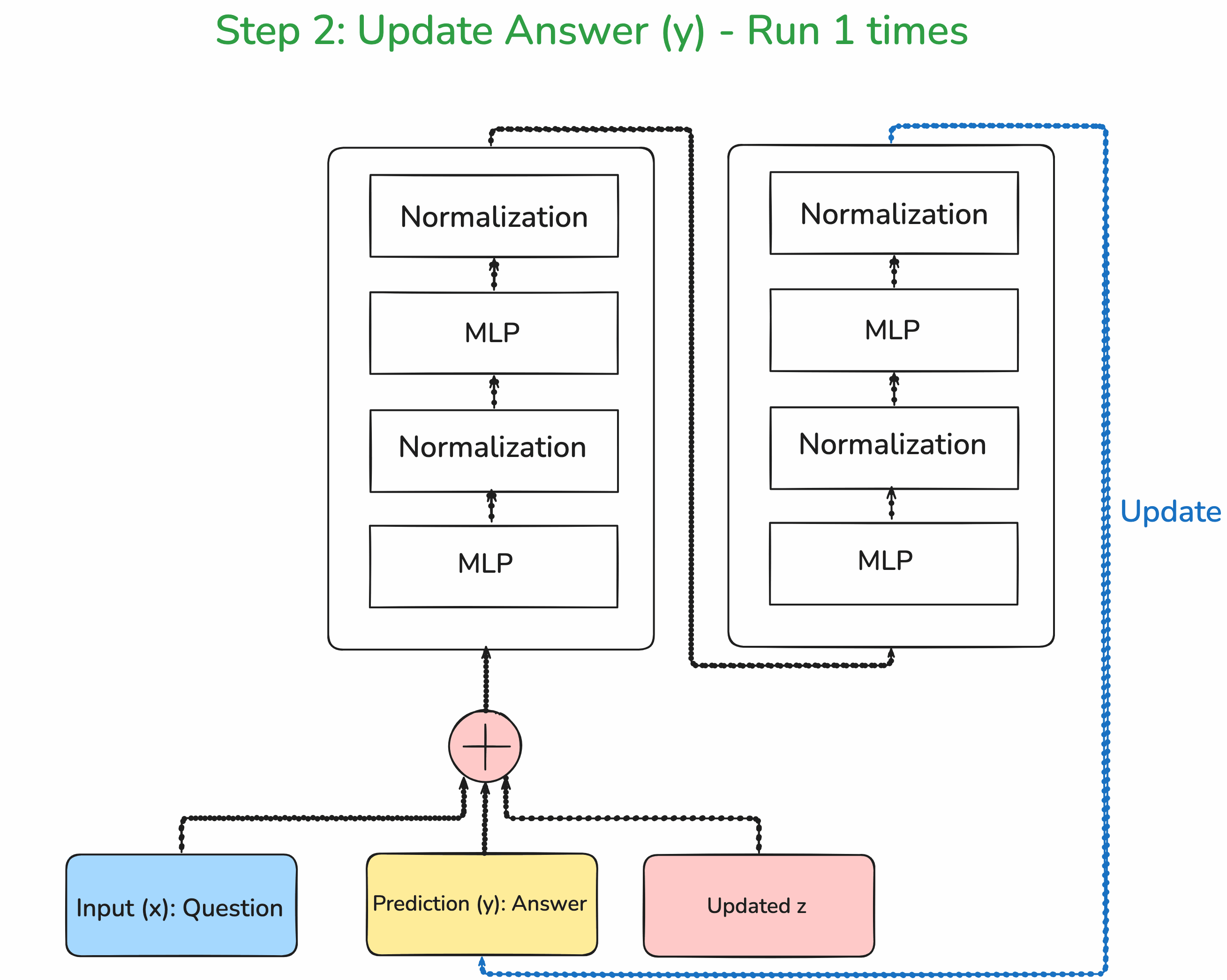
Step 3: Deep Supervision
This step is very interesting. It consists of improving the answer through multiple supervision steps such that it emulates very deep neural networks.
This is where we run backpropagation by improving our prediction to match it with the true value.
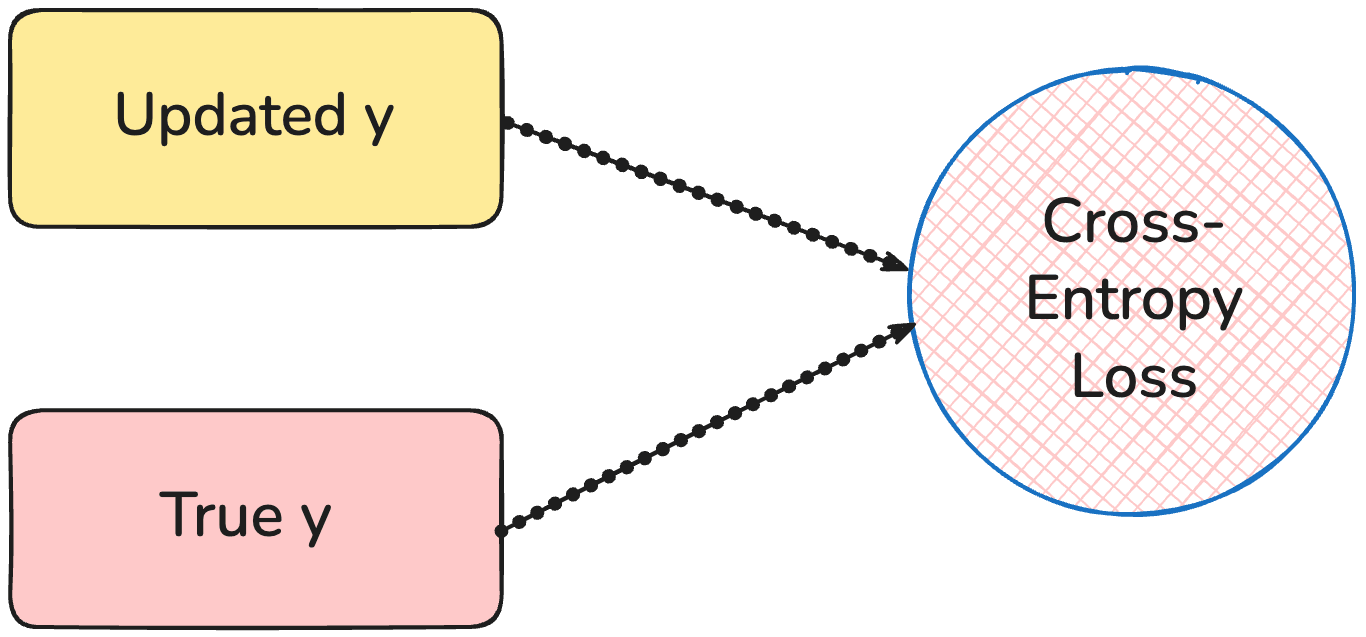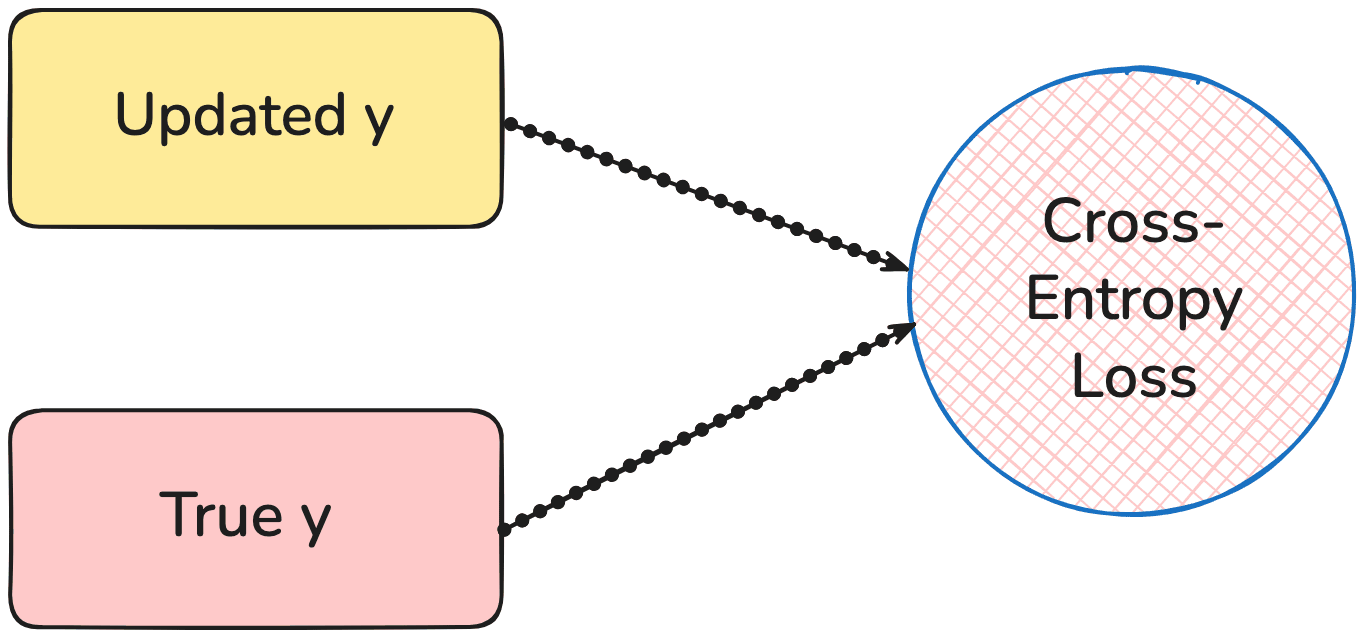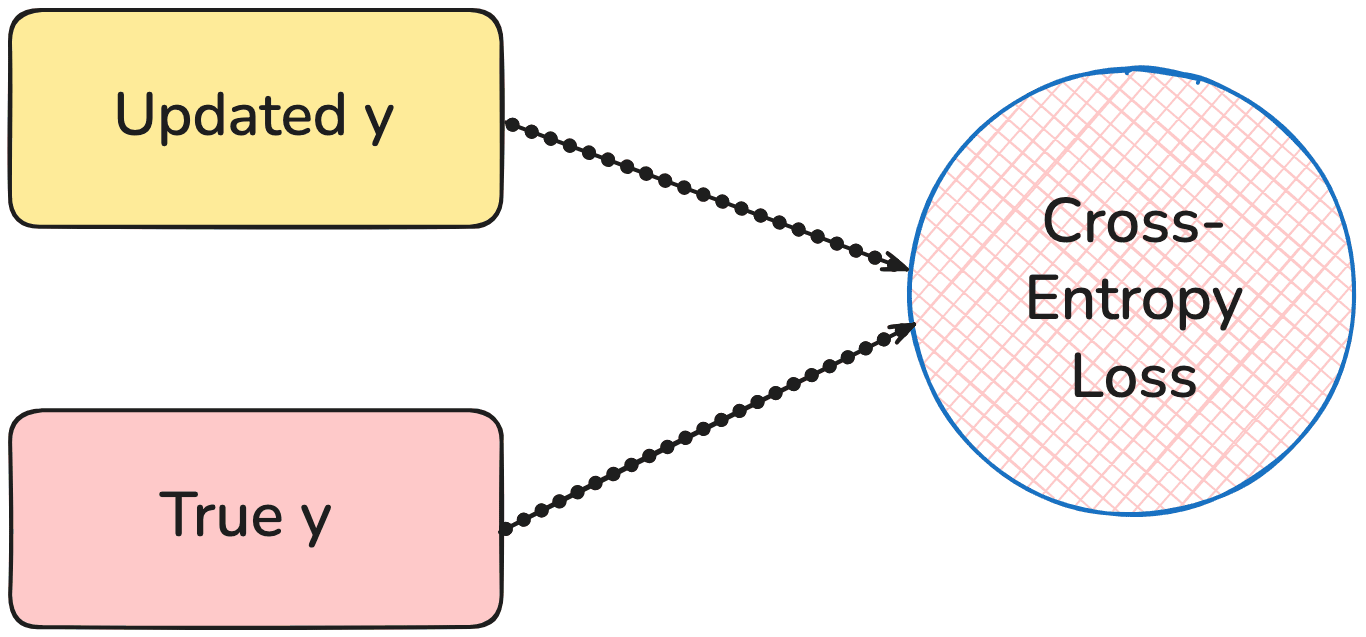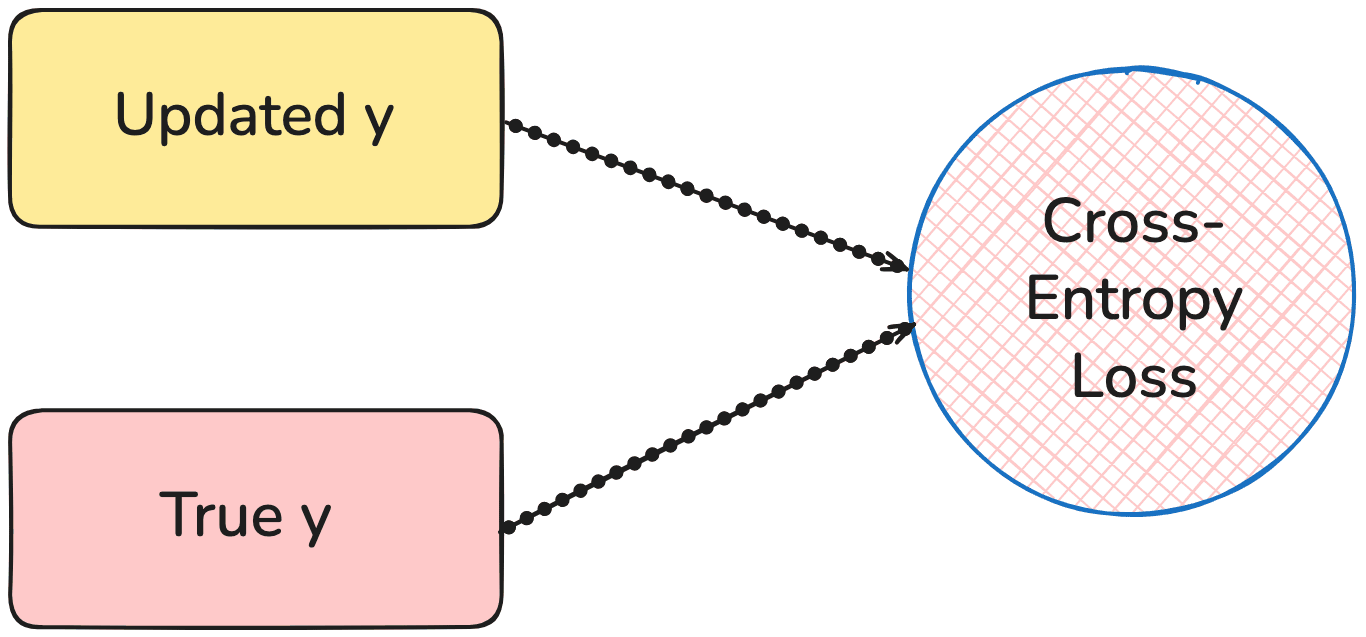
These are the only three steps which are involved in the tiny recursive model.
Running the model and seeing the results for yourself!
We can replicate the results by using the GitHub repository in which the code has been uploaded.
The repo has amassed over 3.8k stars in four days.
I am going to outline the steps which are mentioned in the GitHub repository to be able to train the tiny recursive model to solve pseudo-puzzles.
Step 1: Install all the necessary requirements
pip install --upgrade pip wheel setuptools
pip install --pre --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu126 # install torch based on your cuda version
pip install -r requirements.txt # install requirements
pip install --no-cache-dir --no-build-isolation adam-atan2
wandb login YOUR-LOGIN # login if you want the logger to sync results to your Weights & Biases (https://wandb.ai/)
This step took around 15 minutes for me to complete.
Step 2: Dataset Preparation
python dataset/build_sudoku_dataset.py --output-dir data/sudoku-extreme-1k-aug-1000 --subsample-size 1000 --num-aug 1000 # 1000 examples, 1000 augments
We are using the Sudoku Extreme dataset for training our model.
Step 3: Training Our Model
run_name=”pretrain_mlp_t_sudoku”
python pretrain.py \
arch=trm \
data_paths=”[data/sudoku-extreme-1k-aug-1000]” \
evaluators=”[]” \
epochs=50000 eval_interval=5000 \
lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 puzzle_emb_weight_decay=1.0 \
arch.mlp_t=True arch.pos_encodings=none \
arch.L_layers=2 \
arch.H_cycles=3 arch.L_cycles=6 \
+run_name=${run_name} ema=TrueFor training the model, I used1 L40S GPU, as outlined in the GitHub repo. I acquired access to this GPU using RunPod.
The training took 26 hours to complete. On RunPod, this GPU costs $0.86/hr. So overall, I took ~ 22 dollars for me to train the model.
The following are the results I got (visualized using wandb dashboard):
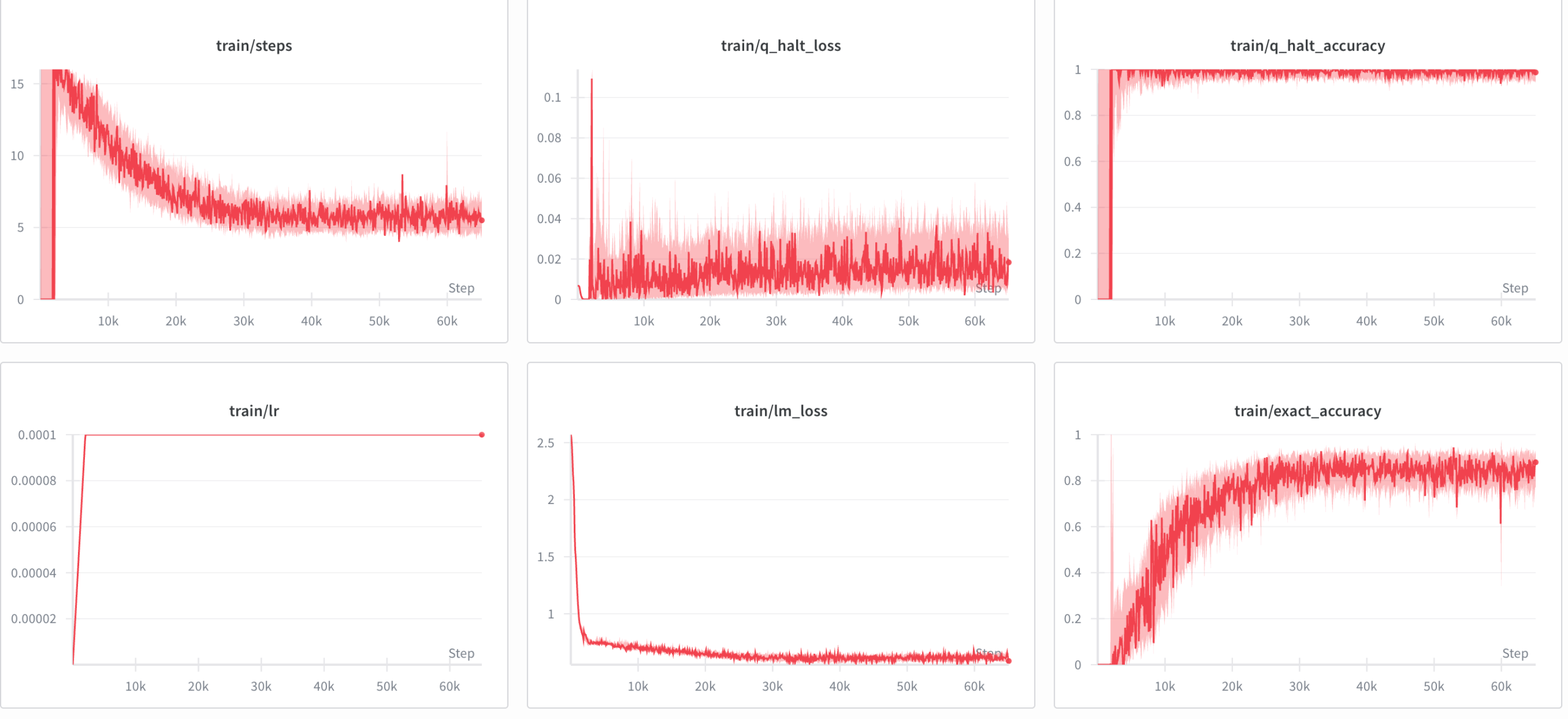
The training accuracy plateaued around 88%.
The simulation provided another set of charts, which I assume to be the testing charts. These charts looked as follows:
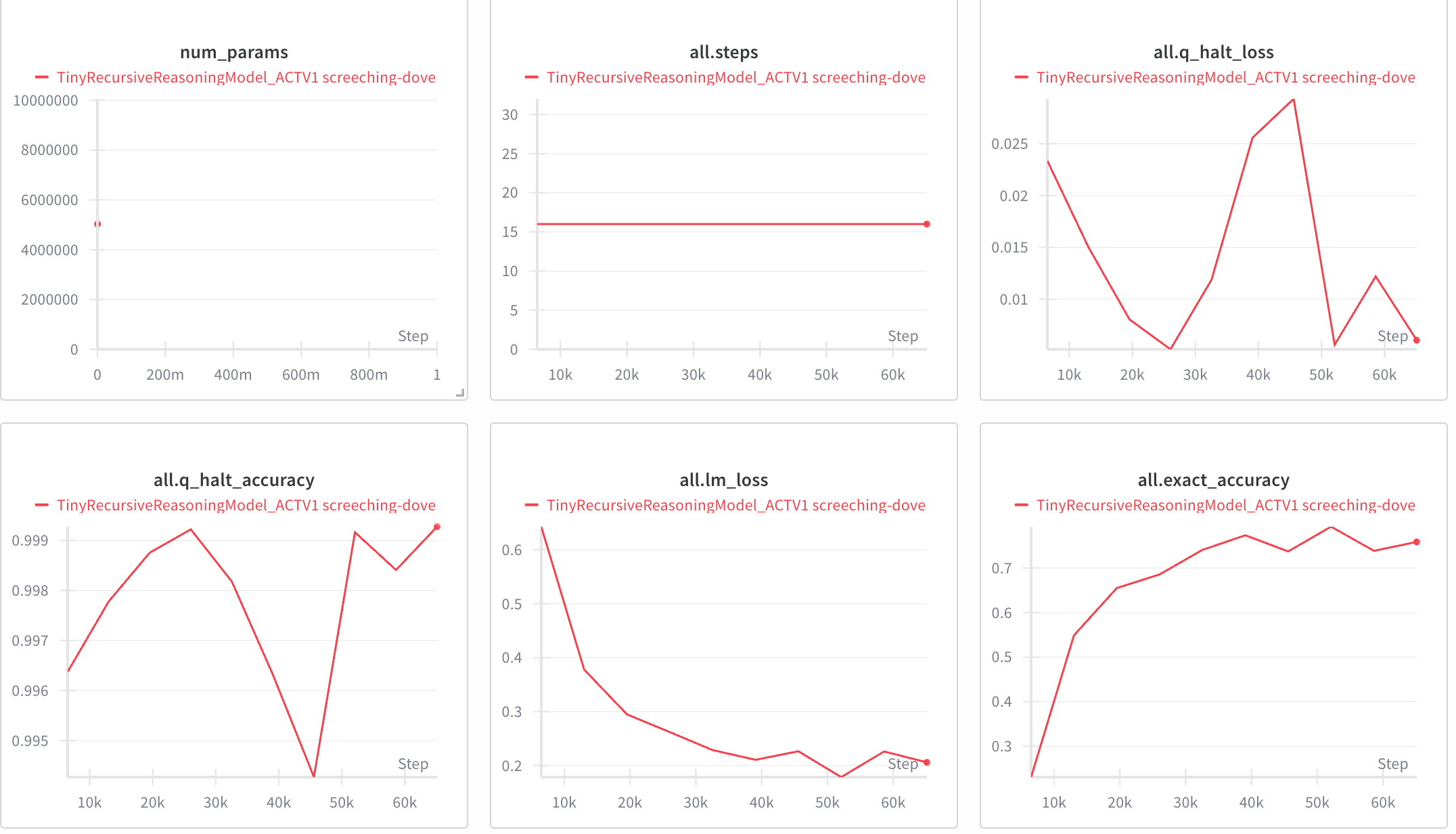
The maximum all-exact accuracy I obtained was 79.82%.
Results Reported in Paper
The paper reports the following results for the Sudoku Extreme dataset.
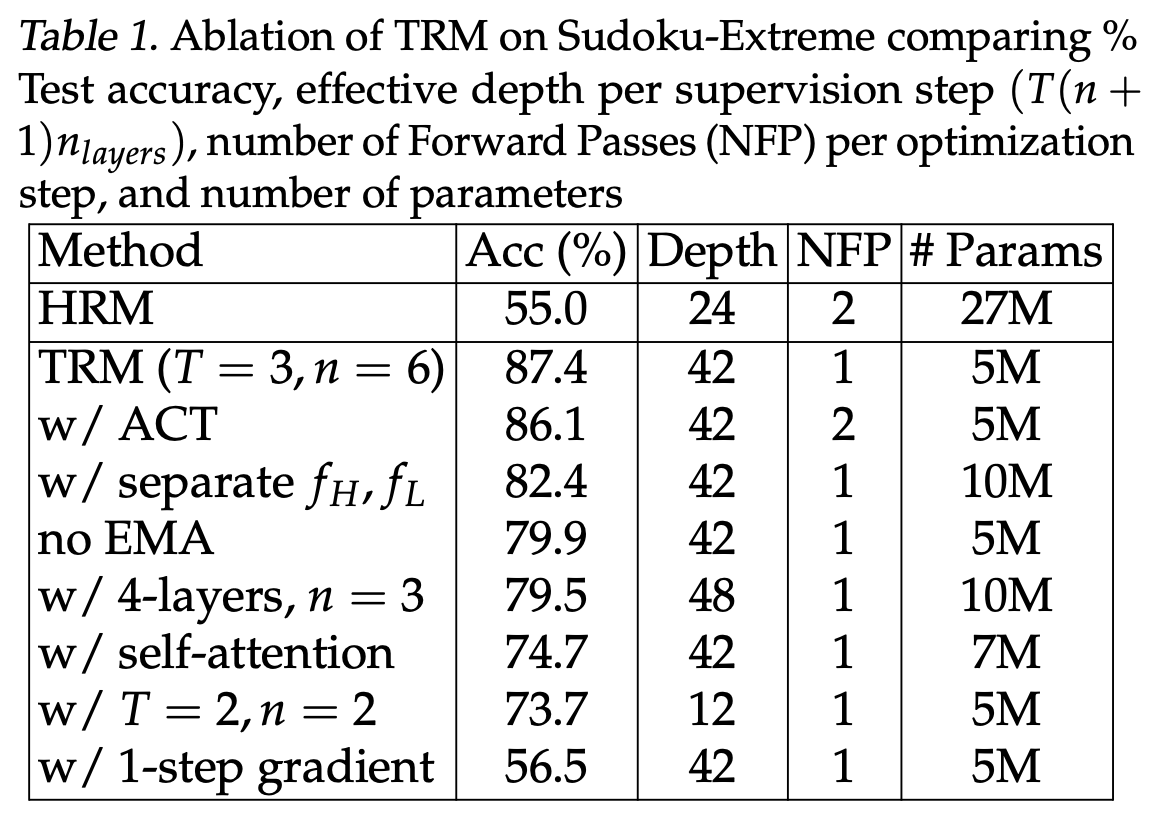
To understand the values of n and t which we are using, we should look at our code where it is clearly mentioned that the number of L cycles is equal to 6 which means n is equal to 6 and the number of H cycles is equal to 3 which means T equal to 3. and the number of layers are 2. So we should match our result with the first row of the table.
My testing accuracy was 79.8%, which is lesser than what is reported in the paper, which is 87.4%. This accuracy exactly matches the one which is reported in the paper when exponential moving average is not used. However, we do specify in the code that “ema = true”, which makes me wonder the root cause of the discrepancy in the testing accuracy.
TRM Beats DeepSeek-R1, Gemini-2.5 Pro and o3-mini-high on AGI Benchmark
ARC-AGI-1 and ARC-AGI-2 are geometric puzzles involving monetary prizes. Each puzzle is designed to be easy for a human, yet hard for current AI models. Each puzzle task consists of 2-3 input–output demonstration pairs and 1-2 test inputs to be solved. The final score is computed as the accuracy over all test inputs.
An example question from ARC AGI-1 benchmark looks as follows:

Each puzzle consists of input-output pairs displayed side by side. The left grid shows the input pattern, and the right grid shows the transformed output.
The puzzles feature colorful geometric shapes, including squares, rectangles, and patterns in various colors (blue, red, yellow, green, pink). Some patterns appear to be connected or arranged in specific layouts.
The right side of the main image contains a test case with a question mark, indicating this is the challenge to solve. The user needs to determine what transformation rule is being applied based on the example pairs, then apply it to this new input.
These puzzles represent what François Chollet designed to test general intelligence in AI systems.
They specifically evaluate an AI’s ability to recognize patterns and apply abstract concepts to new situations with minimal examples - skills that humans find relatively easy but AI systems struggle with.
The table below specifies how the Tiny Recursive Model (TRM) performed compared to some of the leading LLMs:
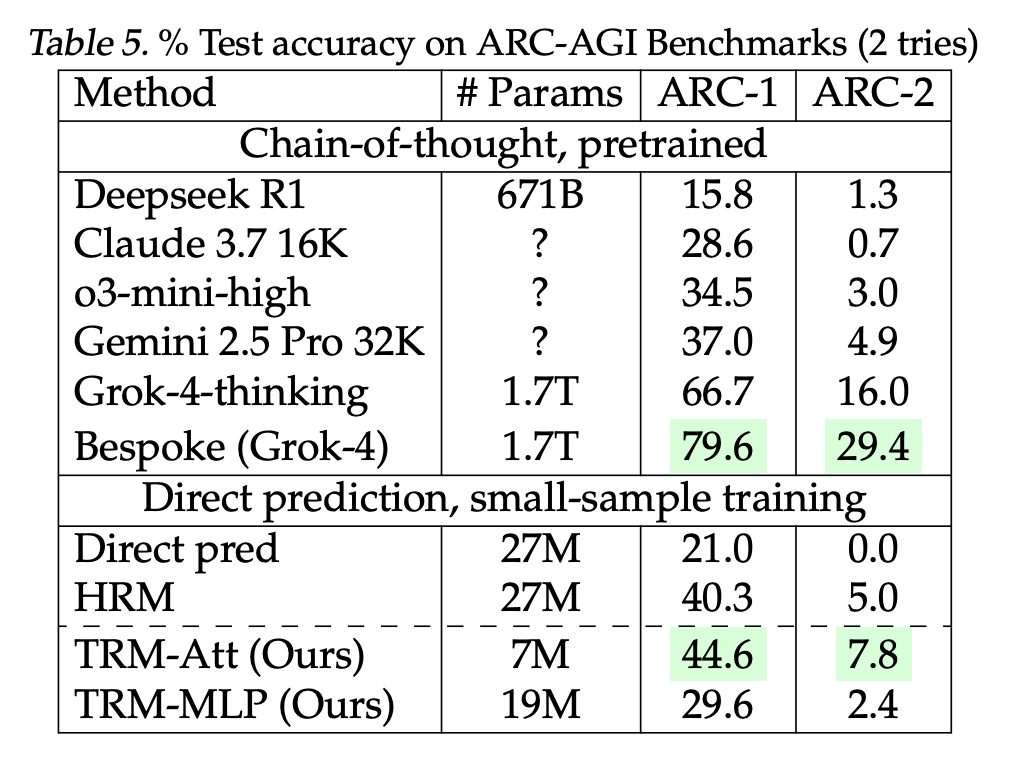
From the above table, we can see that the model with self-attention performs better than several state-of-the-art LLMs like Claude, o3, Gemini and DeepSeek, and achieves an accuracy of 44.6%.
Cool!
Hi, have you figured out why there's a discrepancy in the testing accuracy?