
Why unicode or character tokenization fails?
The reason why we need sub-words tokenizers is discussed in this post.

1. Let’s start from the very basics
Let’s start with a sentence in English:
“Today, I want to start my day with a cup of coffee”

Tokenization is the process of taking this string and convert into a numerical format.
The way this is done is by taking this string and converting this string into tokens first.
Tokens are fundamental building blocks of an LLM.
Each token will then be assigned a token ID and then the pre-training starts.
So let’s think about how to tokenize this text.
2. Unicode standard
One of the simplest ways to do this is to use “The Unicode Standard”.
Unicode is text encoding standard maintained by the Unicode Consortium designed to support the use of text in all of the world's writing systems that can be digitized.

Unicode supports 168 languages (as of now)
It defines 154998 characters (as of now)
Unicode maps each character (out of the 154998 characters it supports) to an integer.
One simple way to encode to tokenize the sentence above is this:
We break down the sentence into individual characters. These characters will be our tokens
Each token will be assigned an integer based on the Unicode mapping.
Let us try this in practice:
[ord(x)for x in "Today, I want to start my day with a cup of coffee"]Here is the result:
[84, 111, 100, 97, 121, 44, 32…]We can go a step further and map out each character to it’s token ID:
text = "Today, I want to start my day with a cup of coffee"
result = [(char, ord(char)) for char in text]
for char, token_id in result:
print(f"Character: {char}, Token ID: {token_id}")Here is the result:
Character: T, Token ID: 84
Character: o, Token ID: 111
Character: d, Token ID: 100
Character: a, Token ID: 97
Character: y, Token ID: 121
…3. Why not just use these unicode integers? Why have tokenization at all?
(a) Ballooning effect and context size:
Large language models operate over “tokens.” If every character were a token, the total number of tokens required to represent text would be huge, increasing computational cost.
For example, consider a sentence:
“Today, I want to start my day with a cup of coffee”
Using pure Unicode-based tokenization, every single character—including spaces, punctuation, and repeated letters—becomes a unique token.
This is 50 tokens for the above sentence.

Using pure Unicode-based tokenization, every single character—including spaces, punctuation, and repeated letters—becomes a unique token.
Even short documents would balloon into thousands of tokens, causing the model to waste processing steps on trivial details and reducing how much the model can fit into its input context at once.
I call this the ballooning effect!

What is the problem if every document balloons to thousands of tokens?
To understand this, you first need to understand context window for LLMs.
What is context window for LLMs?
The “context window” of a large language model is the amount of text it can pay attention to at once. Think of it as the model’s working memory: if the context window is 4,000 tokens, that means the model can look at and reason about up to about 4,000 tokens of text before it has to "forget" something. The model can’t see any words beyond that limit in a single request.

Let’s take a simple example:
We will consider the same sentence we started with “Today, I want to start my day with a cup of coffee”
Using Unicode tokenization, this sentence balloons into 50 tokens, as we saw before.
For the sake of simplicity, let’s assume that the model context window is 32 tokens.
With character-level tokenization, after the model reads the first 32 characters, it hits its context limit. This means it can only “see” up to the 32nd character of the sentence at once.
By the time we reach “w” in “with” (the 33rd character), the model cannot include the rest of the sentence in its context at the same time. Essentially, the model’s view of the sentence is truncated.
The model’s input would be cut off somewhere in the middle of the sentence, for example:
Visible to the model (first 32 chars): "Today, I want to start m"
Not visible (truncated): "y day with a cup of coffee"Because the model never sees the full sentence at once, it can’t accurately interpret the full meaning. It loses context about the phrase “my day with a cup of coffee,” which might be crucial for generating a coherent or contextually relevant response.

If we extend this idea to longer texts, the problem becomes more pronounced. Any document that is longer than the model’s character-level context window gets chopped up into small, context-limited chunks.
The model constantly loses track of previously seen information, making it less capable of understanding long passages, referring back to prior points, or maintaining a coherent narrative.
Hence, one of the major reasons why unicode tokenization does not work is because of the ballooning effect. The more ballooning, the more context size issues we will run into.
(b) Representing meaningful units:
Human language is composed of words, parts of words (like prefixes, suffixes), and commonly repeated phrases.
Many words share common roots or fragments. For instance, in English, words like “starting,” “started,” and “start” share a stem.
When we do unicode encoding, every single unit carries no meaning.
Unicode encoding destroys the main essence of text: that words carry meaning.

Models learn language patterns more effectively when they can operate on units that carry more linguistic meaning than single characters.
(c) Vocabulary size:
If we use unicode encoding, the vocabulary size is the number of characters in the Unicode dictionary: 154998.
This is huge!
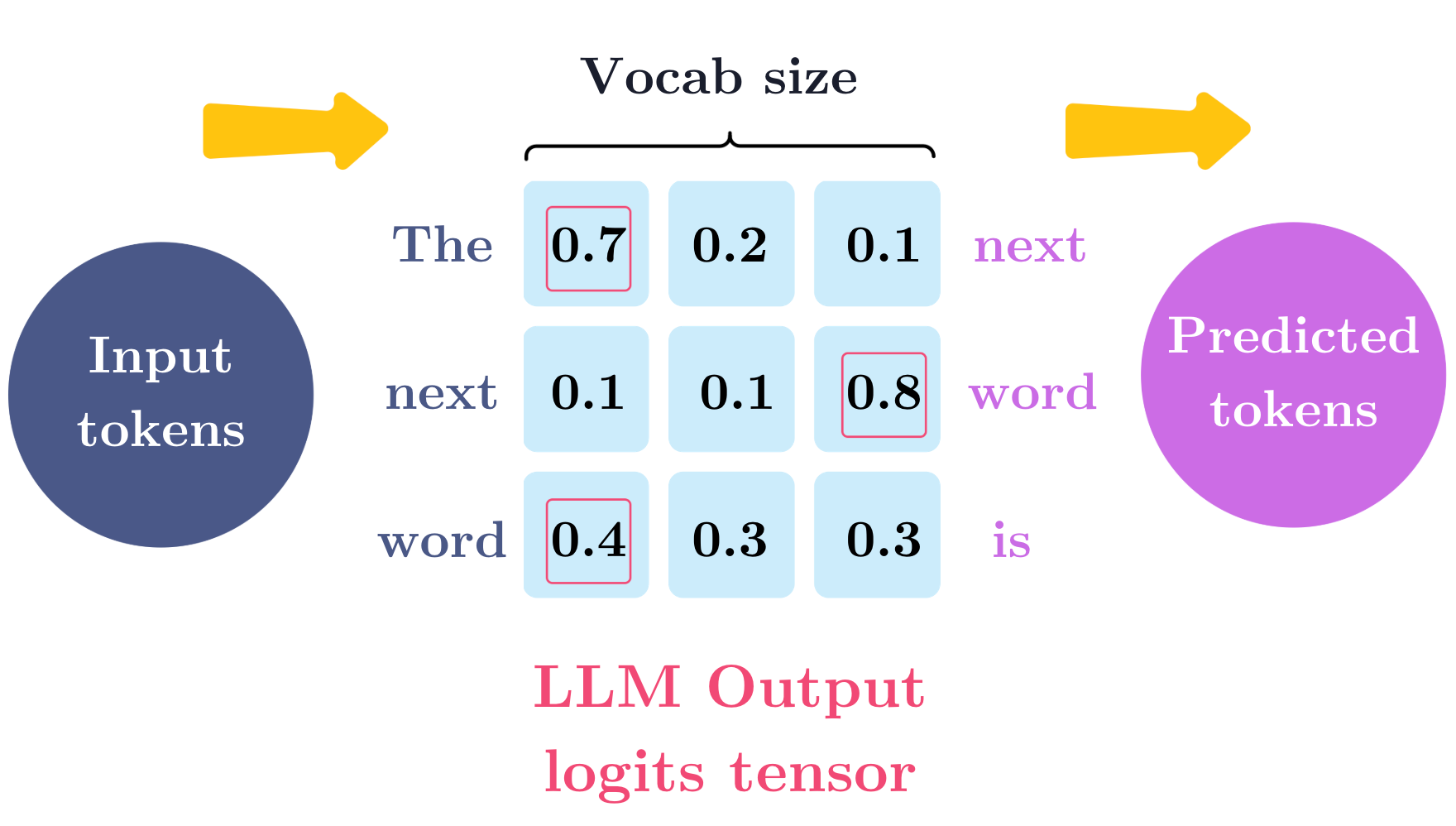
When we pre-train large language models, the vocabulary size will have an effect on the final layer of the transformer architecture: the LLM output logits tensor.
The larger the vocabulary, the larger is the LLM output logits tensor.
I don’t want to explain the logits tensor here. However, for now, all you need to know is that we don’t want huge logits tensors.
4. Okay, I get why unicode integers won’t work. What next?
So essentially we come to a place where we want to achieve 2 things:
We don’t want the ballooning effect. So we don’t want to represent every single character as a separate token.
We want to retain the meanings of words. We want to retain the knowledge of root words etc.
One solution to both of these problems is to merge characters and treat sub-words or entire words themselves as tokens.
If we treat entire words as tokens, we need to have a vocabulary of all known words in all languages. In English language itself, the total number of words is more than 500000. That’s not very good, because of the vocabulary size issue we discussed above.
The only solution which remains then is to use sub-words as tokens.
Don’t use characters as separate tokens (that leads to the unicode issues)
Don’t use words as separate tokens (that leads to the issue of vocabulary size)
We find a solution halfway: that solution is to use sub-words as tokens.
5. How to decide which sub-words to use as tokens?
The most obvious thing to do is to use commonly occuring subwords as tokens.
How do we find commonly occuring sub-words?
That’s where the Byte Pair Encoder (BPE) algorithm comes into picture.
The BPE algorithms keeps on adding sub-words to the vocabulary until we reach a vocabulary size we desire.
This algorithm is at the heart of ChatGPT and why it works!
This post has already become too long, and I will explain how BPE algorithm works in the next post.
Stay tuned!