
Continuous Thought Machine : Think before you speak
Reasoning remains a pivotal task for intelligence, modern day LLMs are restrictive with cumbersome architectures. CTMs aims to solve that and much more through a interesting network design.

Table of content
Introduction : Rethinking Thought in AI
Why thoughts Are Core to Reasoning?
How reasoning is mostly done?
Chain-of-thought
Chain-of-reasoning
Continuous Chain of Thought (COCONUT)
Problems with Modern-Day Architectures
What Could Be a Better/Ideal Way?
Methodology
Architecture Overview
Training Procedure
Inference with CTMs (Thinking Until Confident)
How CTMs Relate to Sequential and Attention-Based Architectures
Results and Experiments
Thoughts
Conclusion
Introduction : Rethinking Thought in AI
One of the most fundamental misconceptions we’ve inherited in modern deep learning is the assumption that thoughts are well-represented as static snapshots in text space. From autoregressive LLMs predicting the next token to image-captioning models outputting discrete sequences, we’ve implicitly tied cognition to surface-form outputs, usually word-level. But this abstraction is brittle, as the thoughts are not just frozen language segments. They evolve, shift, and refine as internal processes. What we observe as output is merely the residue of much deeper computation.

In my earlier articles on Latent Consistency Models (LCMs) and Biologically-aligned Language Transformers (BLTs), I touched upon this exact issue about how flattening time and internal state into token streams causes models to hallucinate, miss dependencies, or fail under recursive or compositional reasoning. The problem isn’t just decoding. It’s architectural: we’ve trained our models to write well, not to think well.
But if we move beyond this static framing, an obvious question emerges: What does it mean for a model to think? And can we represent thoughts as temporal, evolving processes, rather than discrete jumps between tokens? This is exactly the problem researchers as Sakana.ai (authors of really cool paper Transformers^2) are trying to tackle and we are going to see how they have perceiving the problem and their proposal to solve it.
Why thoughts Are Core to Reasoning?
Human cognition isn’t instantaneous. We don’t observe an image and immediately respond with a label. Our minds often simulate possibilities, weigh interpretations, and iteratively refine understanding before acting. This process is dynamic as it unfolds over time, often revisiting or revising earlier ideas. In other words, reasoning is temporal.
Most of today’s AI systems shortcut this process. Transformers, for example, collapse reasoning into a single forward pass. Even when we “think step-by-step” via chain-of-thought prompting, it’s still a form of prompt injection, not internal reflection. The model isn't thinking, it is just writing as if it is.
What we need is a system that can simulate continuous internal cognition, where latent representations evolve over time, and the model chooses how long to think before acting. That’s where Continuous Thought Machines (CTMs) enter the scene.
Companies like Anthropic and DeepMind have been exploring ways to embed structured reasoning inside deep networks. Anthropic introduced attribution graphs, which attempt to trace which neurons contribute to which outputs a form of backward interpretability. Others like OpenAI explore reflexion loops or scratchpad models where the model can self-debug using additional tokens. There are even external tools like Toolformer, Chain-of-Thought, and ReAct; all of which simulate reasoning by forcing the model to write intermediate steps.
While effective in benchmarks, these techniques remain superficial hacks layered over static architectures. The model isn’t truly performing recursive reasoning it’s just doing more decoding. There’s no internal evolution of belief or uncertainty, no time-aware computation path, and no native way for neurons to synchronize or “reflect.”
CTMs challenge this paradigm. Instead of simulating thought through text, they build thought into the architecture itself by using continuous, neuron-level dynamics, temporal evolution, and synchronization across internal states to form a more biologically and cognitively aligned reasoning model. This is not just another neural network architecture. It is a blueprint for machines that decide when they’ve thought enough.
How reasoning is mostly done?
Most systems simulate reasoning at the output level; through clever prompting, decoding strategies, or decoding-time loops. Let’s briefly revisit those techniques to contrast how CTMs fundamentally shift the ground.
Chain of Thought (CoT)

Chain of Thought is the most widely adopted strategy: by prompting models to "think step by step," we nudge them to generate intermediate reasoning steps before giving a final answer. The goal isn’t to make the model smarter per se, but to offload reasoning onto the generation space, where the model has been trained on similar patterns. It’s a format trick and it works surprisingly well for math, logic, and multi-hop QA. But the actual thinking still happens as part of token prediction.
Chain of Reasoning (CoR)
Chain of Reasoning expands on CoT by incorporating intermediate tool use, planning, or goal decomposition. It’s more than step-by-step, its about tracking rationale, deciding which sub-questions to answer, and even invoking function calls or external models mid-generation. CoR makes models act more like planners, but still within the constraints of autoregressive token flows.
Continuous Chain of Thought (COCONUT)

COCONUT is a more recent attempt to smooth out discrete reasoning steps into a continuous process. Instead of jumping from one rationale to the next, it encourages interpolation across latent thought vectors where every partial thought influences the next in a non-discrete way. You can think of it as building a vector-valued path through reasoning space, not just a list of statements. It's closer to what CTMs aim for, but still bound to decoding flows and fine-tuning tricks rather than being architecturally embedded.
I wrote a detailed article over COCONUT and pain-points around it, you can find it here : COCNUT POST
While these techniques are incredibly useful, but, they’re all still surface-level solutions. They help LLMs appear rational, but they don’t make the model internally consistent or temporally grounded. Lets understand exact problems in the next section.
Problems with Modern-Day Architectures
Time is Treated as Just an Index : In most models, time isn’t a process; it is just an index. That is, inputs are assigned a discrete ordering: tokens in a sentence are given positions
{1,2,...,n}, and that’s passed into the model through sinusoidal or learned positional embeddings. But this is shallow modelling. It treats time as a label, not a concept. There's no native idea of flow, persistence, or temporal causality which is just fixed coordinates in an input grid.Formally, you can think of this as working over a finite index set
I⊂N, where time is just another dimension for indexing a tensor. It's not dynamic, it's static. The model doesn’t experience “step 2” as a result of “step 1”; it just processes the entire index set all at once. This abstraction, while great for parallelism, breaks down when modelling reasoning; which, by definition, is an unfolding process.Reasoning Requires Time-Aware Thought Not Flat Generation:
LLMs attempt reasoning by generating it. But this is subtly flawed. The model isn’t actually thinking, it’s just learning to simulate reasoning as a writing pattern. There is no internal latent evolution of belief or interpretation; hence, what looks like step-by-step deduction is, to the model, just another token pattern. The reasoning is part of the output, not part of the process.
To put it plainly: Modern LLMs generate reasoning, they don’t perform reasoning.
This is why current models struggle with problems that require revision, recursion, or multi-hop abstraction. They can fake a scratchpad if trained on enough chain-of-thought examples; but there is no actual temporal processing underneath. The model doesn’t “loop back” or “pause to reflect.” There’s no internal time; only positional embeddings in a feedforward stack.
No Reversible or Re-entrant Computation
Another overlooked limitation is that most architectures today are stateless forward machines. Once an attention head fires, it doesn’t get to re-evaluate its choice. Once an FFN layer transforms a token, that transformation is final. There’s no mechanism for re-entry, re-evaluation, or iterative refinement. This makes it impossible for the model to “change its mind” mid-process, unless you hack in external feedback loops (e.g., reflexion, scratchpad decoding, etc.). But those are duct-tape solutions, not architectural features.
Compare this with how humans reason: we often loop through possibilities, discard incorrect hypotheses, revisit older beliefs. None of this exists in the backbone of a Transformer.
Uniform Computation, No Adaptive Depth
Reasoning is not uniformly hard. Some questions need milliseconds of thought; others take days. But in today’s models, every token gets the same number of layers, the same computation budget, the same decoding path. There's no ability to think harder for harder problems, or terminate early for easy ones.
In theory, models like Universal Transformers or Adaptive Computation Time (ACT) tried to address this, but they were mostly abandoned due to complexity and performance issues. In practice, we’ve gone back to flat compute graphs where every forward pass costs the same, whether the question is “What’s 2 + 2?” or “Prove Fermat’s Last Theorem.”
These architectural choices have side effects:
Token-level myopia: Each generation step only sees past tokens as there's no global planning, revision, or memory.
Overfitting to format, not logic: Models learn what a proof looks like, not how to construct one.
Brittle generalization: The lack of internal state evolution makes models fragile under distributional shifts, since their “reasoning” is tightly coupled to training-style prompts, not general principles.
What Could Be a Better/Ideal Way?
If modern neural networks fall short because they treat reasoning as a side-effect of generation, the natural question is that what should reasoning look like? What would it mean for a machine to actually think, not just simulate thinking? What would an ideal architecture prioritize if its core objective was to reason?
Time as a First-Class Citizen
The first fix is obvious, but deep: time must become a central part of computation, not just an extra index slapped onto a tensor. In humans, time isn’t just background, it shapes how thoughts form. Ideas build on each other, attention drifts, focus sharpens and fades. We loop, iterate, backtrack, hesitate. All of that happens before anything gets said.

But in today’s models, once the forward pass is complete, the “thought” is over. No rethinking. No uncertainty accumulation. No internal revision. What we need is a system that thinks in terms of ticks(discrete time steps) which small, learnable steps of inner computation where the model can take its time, explore internal space, and decide when it’s ready to act.
In an ideal case, every input wouldn’t trigger just a forward pass; it would trigger a controlled sequence of internal updates, each contributing to a richer, more refined internal state.
Reasoning as a Process in Latent Space
This leads to the second insight: reasoning should not live in the output space (i.e., the generated tokens), but in the latent space of internal computation.
Today’s chain-of-thought prompting teaches models to write their thoughts. But real reasoning in humans and in a desirable AI system happens before any external expression. We simulate internally, we might represent options, contradictions, goals, partial beliefs but we don’t say them aloud unless we have to.
An ideal architecture would represent such dynamics within neurons and activations. Instead of converting thought into tokens for interpretation, it would let thoughts exist in the network’s internal time-evolving state. This internal state could “settle” into a decision once the model reaches high enough confidence or keep refining itself if uncertainty remains.
In this sense, reasoning becomes a latent trajectory, not an observable artifact.
Dynamic Compute (spend more time when required)
Reasoning is rarely linear as some problems are trivial and need no depth; others demand recursion, memory, and abstraction. An ideal model should have a built-in ability to spend more compute on harder inputs, not because we prompt it with "Let's think step by step", but because the model knows it’s uncertain and decides to think longer.
This implies internal recurrence, feedback, and termination mechanisms. The model needs to monitor its own internal state and say:“I’m not ready yet, give me another tick or “I’ve converged; here’s my answer.”
This kind of dynamic compute where inference depth is a function of problem complexity aligns far better with how intelligent behaviour actually unfolds.
Synchronization as Structure
One subtle but powerful idea is synchronization, not just between time steps, but across space of neurons. In an ideal system, neurons shouldn’t just fire in isolation. They should coordinate, compare their internal temporal histories, and align around consistent representations.
This is deeply biological. Our brains don’t solve problems by having one neuron do everything. Instead, networks of neurons synchronize their firing patterns, creating coherent assemblies that represent abstract concepts. An architecture that reasons should also allow for emergent structure, not just static computation.
Summary: What an Ideal Reasoning System Looks Like
To summarize, the architecture of reasoning should:
Treat time not as metadata, but as part of computation
Let thoughts evolve internally through recurrent latent updates
Perform adaptive computation hence think longer if needed
Allow neurons to coordinate, not just activate
Separate reasoning from generation, letting thought live before expression
This isn’t a minor tweak to Transformers it’s a shift in what we consider the core of intelligence and this is exactly the direction Continuous Thought Machines are trying to go.
Methodology
CTMs are not another incremental tweak to existing networks. They’re a departure from the flat, one-shot nature of forward-pass architectures like Transformers. At their core, CTMs are built on one powerful idea: Reasoning should unfold over internal time, using synchronized and evolving latent dynamics even for static inputs.
To do this, CTMs combine four key components:
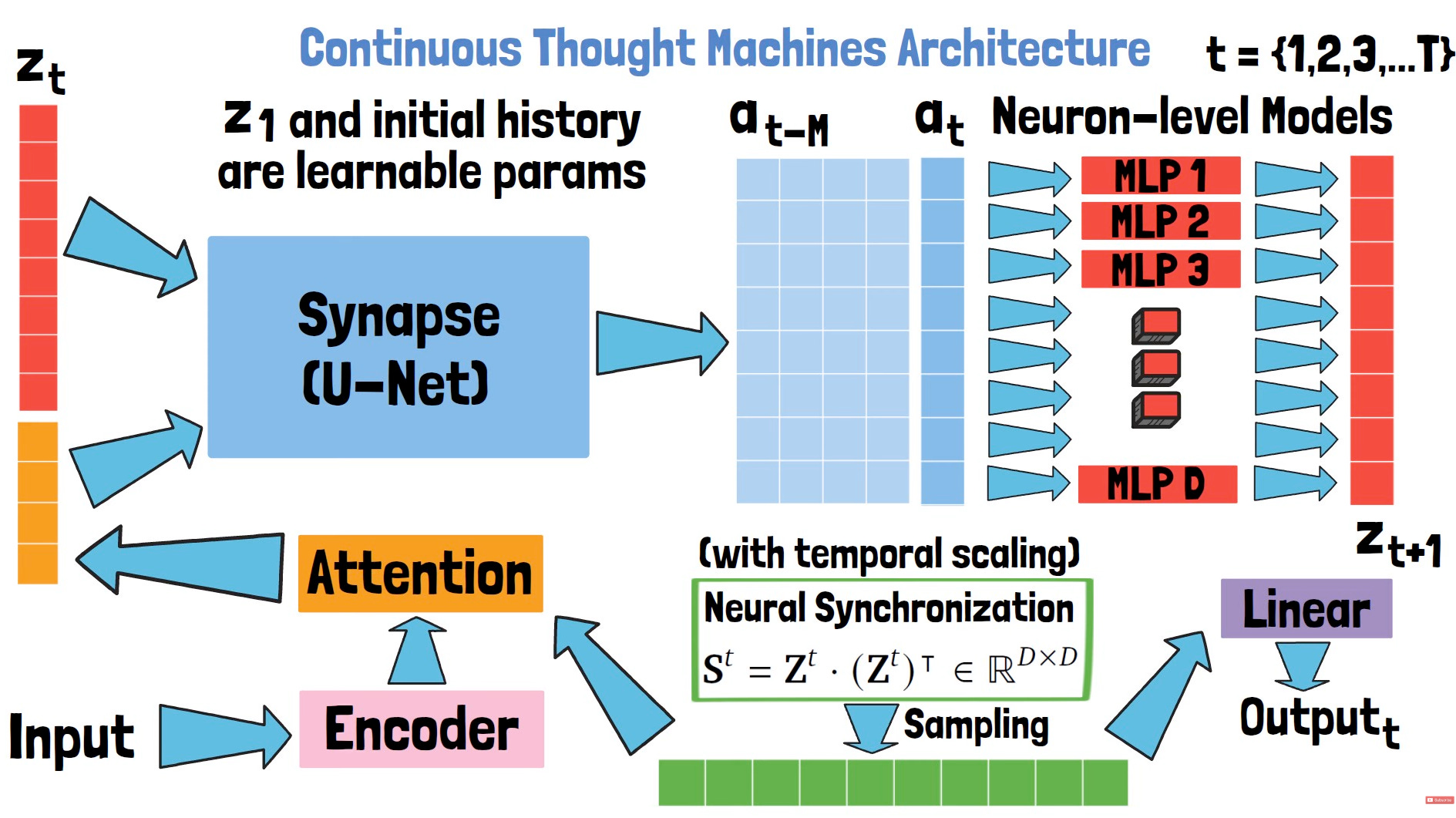
Neuron-Level Models (NLMs): Tiny private models inside each neuron.
Synapse Modules: Aggregators of history and attention-weighted inputs.
Temporal Histories: Each neuron maintains a recurrent trace of its own activations.
Synchronization Matrix: A dynamic, trainable way to compute correlation between neurons’ internal states effectively forming a thought graph.
Now we know component names; Let’s die into actual details.
Architecture Overview
Imagine a fully connected feedforward layer, but instead of firing once, each neuron:
Stores its own short history of past activations,
Runs a tiny recurrent model (NLM) to decide its next activation,
Updates at each internal tick (think of it as sub-time within a forward pass),
Communicates with other neurons through a synchronization matrix.
This forms a system where neurons are not just passive filters, but mini temporal processors that evolve their beliefs over time.
Neuron-Level Model (NLM)
Each neuron ni is equipped with its own small neural net (shared across groups or layers, for tractability). This NLM takes as input:
The neuron's own activation history (e.g., from previous ticks),
Optionally, input from a synapse module (aggregated attention from other neurons),
and produces the next activation ai(t+1). The NLM can be as simple as a small MLP or RNN as it just needs to encode time-aware behavior inside a single unit.
This is analogous to liquid neural networks or micro-RNNs inside each neuron hence giving neurons memory and update dynamics.
Synapse Module

To allow neurons to interact, each neuron is also connected to a synapse module that:
Collects attention-weighted summaries of other neurons’ activations,
Feeds this into the NLM, giving each neuron a sense of what others are doing.
You can think of this as a temporal attention layer at the micro level; letting each neuron weigh others before updating itself. It could be anything ranging from simple MLP block to a UNet like architecture (used in paper).
Temporal History Buffer
Every neuron keeps a rolling buffer of past activations (say, from the last T ticks). This history becomes the input to the synchronization module it is what defines the neuron's "identity" in time.
Synchronization: Thought as Correlation
After a few internal ticks, CTMs compute a synchronization matrix which is a pairwise similarity matrix over neuron histories. It captures how similarly neurons have evolved their activations over time.
This synchronization matrix becomes the core latent space, the model's internal representation of thought. Instead of using raw activations, CTMs build decisions from how neurons have moved through time together.
Think of it as: "Which neurons are thinking alike?"
Or even more intuitively: “Which patterns of evolution are in agreement?”
This is a radical shift as most networks reason through activation magnitude, CTMs reason through activation trajectories.
Training Procedure
Step 1: Input Encoding and Initial Neuron States
CTM training begins just like any other supervised learning setup:
You have a dataset of input-label pairs (x,y). However, the initial input x is passed through an encoder (often shared with the task, like a CNN for images or an embedding layer for text), which transforms it into a vector z0 (initial latent).
From here, each neuron receives a component of this latent as its initial activation. But unlike traditional networks where neurons fire once per input, CTM neurons will evolve over ticks, so this initial activation is just the starting point of a trajectory.
The step 1 doesn’t end here, to make the extracted features semantically rich we apply attention over extracted feature and synchronization matrix till time T (this we will discuss later, for now just assume there exists a matrix of dimension [DxD]) and this produces final representation vector which is the concatenated with representation z0.
Step 2: Internal Ticks and Neuron-Level Evolution
CTMs now begin their tick loop, where computation unfolds over internal time steps t=1,2,...,T. At each tick:
Neuron-Level Models (NLMs) update each neuron's activation using:
The neuron’s activation history up to tick t−1,
Input from its local synapse module (attention-weighted signals from other neurons)
Temporal Buffers store the last k activations per neuron (e.g., a rolling window). This lets the model track its internal evolution and later, compute correlations between neuron histories.
All neurons update in parallel. But critically, each neuron has its own trajectory, governed by its NLM, local context, and attention.
This process happens over fixed ticks T in training (like unrolled RNNs); though in inference, this can be dynamic.
Step 3: Synchronization Matrix Computation
After T ticks, each neuron has a history vector hi=[ai(1),ai(2),...,ai(T)]. The model now computes a synchronization matrix S∈R (N×N) by measuring pairwise correlations between histories:
Where sim can be something like Cosine similarity, Pearson correlation or even trainable similarity kernels.
This matrix acts as a summary of the model’s internal thought structure encoding how groups of neurons have evolved together (i.e., agreed) over time. Until here its mostly processing, once this is completed and we have required set of representations, we move to output head/decoder.
Step 4: Output Head and Loss
From the synchronization matrix, we now produce task-specific outputs:
For classification, a readout module attends over S to produce logits.
For sequence tasks, we may combine S with additional decoder modules.
Let y^ be the predicted output; this is compared to the ground truth yyy using standard task losses:
Cross-entropy for classification,
MSE or regression loss for continuous tasks,
Auxiliary objectives like prediction confidence or halting penalty.
Loss is back-propagated through time over all T ticks, including the NLMs and synapse modules, similar to training an unrolled RNN or neural ODE.
Inference with CTMs (Thinking Until Confident)
One of CTM’s most intriguing features is adaptive inference.
Instead of committing to a fixed depth, the model keeps ticking (Thinking) until its output stabilizes or meets a confidence threshold (e.g., entropy of the output drops below a margin). This allows:
Quick exits on easy examples,
Extended computation on hard ones.
CTMs use two main stopping strategies:
Certainty-based halting: Monitor prediction entropy or confidence score.
Dynamic re-synchronization: Track when neuron correlations stabilize.
There’s even a hybrid mode inspired by semi-autoregressive decoding where neurons update in small groups, alternating attention and diffusion steps (similar in flavor to how LCMs blend AR and denoising logic).
In summary, CTMs aren’t just forward passes with recurrence, they’re ongoing computational processes, where neurons evolve over time, interact, and stabilize before producing output. Every part of the architecture from NLMs to temporal buffers to the synchronization matrix is designed to embed thought before language. Its like you wait for T ticks/across time in a LSTM-like/recurrent process, only once the ticks are halted then we actually start with generation.
This is not only more biologically grounded but also more flexible, robust, and transparent; especially for tasks that demand step-by-step reasoning, recursion, or multi-hop logic.
How CTMs Relate to Sequential and Attention-Based Architectures
CTMs sit at the intersection of sequential models (like RNNs) and attention-based architectures (like Transformers), but operate at a fundamentally different level not across input tokens, but over internal reasoning ticks.
Like RNNs, CTMs evolve internal states over time. Each neuron maintains a history of its past activations and updates its state through a private, lightweight neuron-level model (NLM). This brings recurrence inside the neuron, giving it memory and dynamics (sort of distributed recurrence across the network).
Like attention, CTMs compare information globally. But instead of attending over token positions, CTMs compute a synchronization matrix based on how similarly neurons evolve over time. This matrix captures structural agreement between neuron trajectories and acts as the latent "thought space."
Unlike RNNs (which are slow and sequential) and Transformers (which are parallel but stateless), CTMs offer adaptive, recurrent computation within layers; letting the model "think" longer for harder inputs by taking more internal ticks, and halt early when confident.
This makes CTMs a hybrid:
They inherit the temporal sensitivity of RNNs,
The global coordination of attention,
And introduce a new axis: reasoning as neuron-level latent evolution over internal time.
Results and Experiments
Despite its unconventional design, the Continuous Thought Machine (CTM) holds its ground and in some cases, outperforms SOTAs on a broad spectrum of benchmarks: classification, reasoning, reinforcement learning, and synthetic tasks designed to test abstraction.
Reasoning and Cognitive Tasks
CTMs shine on tasks where most modern models still struggle : discrete reasoning, logic, and recursive inference. For example:
Parity Classification (binary addition over sequences):
CTMs outperform standard MLPs and even Transformers at 100% accuracy, with far fewer parameters.2D Maze Navigation:
With just pixel-level input, the CTM learns to trace correct paths to a goal.
What’s remarkable is that its internal ticks literally “walk” through the path over time, mirroring how a human might visualize the path before moving.

Natural Language and QA Tasks
CTMs were evaluated on question-answering tasks like Q&A-MNIST which is a synthetic benchmark combining digit recognition with symbolic reasoning and BABI-style QA. The model uses its tick-based latent evolution to gradually “resolve” the latent query. Key observations:
Tick depth correlates with difficulty: For simple queries, CTM halts after ~4 ticks; for complex ones, it goes up to 12–15. This is a sign of adaptive compute actually manifesting in inference time.
Unlike traditional models, no scratchpad or intermediate supervision is needed as all the reasoning is implicit within neuron trajectories.
Vision Tasks (Image Classification)
When evaluated on ImageNet, the CTM-ResNet-152 model achieved 72.2% top-1 accuracy, which is competitive with standard ResNets, despite introducing a heavier latent reasoning loop. On small datasets like CIFAR-10, it even surpassed baseline CNNs at low data regimes.

But the story isn't just about accuracy. CTMs offer:
Interpretability via synchronization patterns between neurons
Better handling of ambiguous inputs, where attention needs to drift over different visual patches across ticks
For example, in cluttered digit images, CTMs were observed to “attend” to the region of interest only after 3–4 internal ticks which is an emergent attention-like mechanism without explicit heads.
Reinforcement Learning

CTMs also showed promise in small-scale RL tasks (like gridworld and symbolic puzzles), where:
Each internal tick allows the agent to re-evaluate latent state before acting
Performance improves with tick count suggesting the agent uses the extra time for latent planning, not just reward chasing

This positions CTMs as a bridge between feedforward inference and planning, with built-in temporal abstraction.
Visualization and Interpretability
One of CTM’s standout qualities is how interpretable its reasoning process is; not through post-hoc attribution, but as a direct by-product of its architecture.

Neuron activation trajectories show consistent patterns as some neurons specialize in halting detection, others in evidence gathering.
The synchronization matrix evolves over ticks with increasingly sharp clusters as the model “decides” on a class.
You can literally see when the model starts agreeing with itself as the internal confidence builds (lower entropy), and eventually, halting is triggered.
This is far more transparent than attention heatmaps or saliency maps.
Thoughts
The way we conceptualize architecture, shapes not just implementation details, but entire research frontiers. Consider how, once we started thinking of images as continuous 2D signals rather than mere arrays of pixels, it unlocked decades of signal processing theory; from Fourier transforms to convolutional filtering; that seamlessly mapped onto early computer vision systems.
Or how modeling time as just another spatial axis in Transformers (via positional encoding and causal masking) enabled parallelizable sequence modeling, breaking the bottlenecks of RNNs. These weren’t just engineering tricks, they were conceptual reframings that changed what was computable. Similarly, LLMs flourished when we framed language as a distribution over next-token probabilities, rather than syntactic trees or logical forms.
So, when we ask, “What if thoughts are not symbolic but dynamic? Not token-based but time-evolving?” we don’t just get a new model, we get an entirely new interface to cognition and CTMs embody this shift. They invite us to stop thinking in terms of outputs, and start designing architectures that think in terms of thoughts.
While CTMs mark a fascinating shift toward time-evolving, interpretable reasoning, they’re not a silver bullet. Like any new paradigm, they introduce new kinds of friction (both conceptual and practical). Below are a few key areas where improvements or careful engineering might be needed:
Per-tick Computation Is Expensive : CTMs introduce internal ticks which is a stepwise reasoning loop that unfolds even for static inputs. While this is cognitively elegant, it multiplies inference time by the number of ticks. On large-scale tasks, this can bottleneck throughput unless there's smart control over early exits. One possible workaround is to dynamically prune neurons or compress synchronization structures over time.
Lack of Hierarchical Structure : Right now, all neurons tick at the same level hence, there’s no clear notion of macro vs micro thought processes. This could be limiting for long-form reasoning or planning. A natural extension might be to introduce nested ticking hierarchies, similar to how some Transformer variants use layer-level recurrence or memory stacks, this might allow deeper modules evolve slower simulating multi-timescale cognition.
The synchronization matrix is powerful, but it’s ultimately a correlation over histories, not a semantic understanding. In current setups, two neurons might synchronize just because their curves happen to match, not because they’re abstracting the same idea. One future direction could be structure-aware kernels for trajectory similarity (maybe inspired by graph matching, or causal influence tracing).
CTMs rely on learned halting mechanisms to determine when a thought has "converged." But halting dynamics can be noisy, especially in early training. Some tasks may underthink, others overthink. While entropy-based heuristics help, the model could benefit from auxiliary stopping losses, confidence calibration, or curriculum-based tick tuning.
CTMs perform well across a wide range of tasks without major architectural tweaks, but most results so far are small to mid-scale. The real question is: how does the CTM hold up at GPT-class or ResNet-scale domains? Can it handle language modeling over billions of tokens? If yes, it could be a real contender for future multi-modal reasoning systems. If not, then scaling the recurrence will need better scheduling, batching, and weight reuse techniques.
Conclusion
If there’s one thing Continuous Thought Machines teach us, it’s this: intelligence is not the ability to generate answers, but the ability to refine them over time. CTMs shift the architectural priority from fluent output to evolving cognition. They propose a model that does not just act, but thinks. Not by producing token streams that look like reasoning, but by making reasoning itself an explicit, internal process.
This wasn’t just another architecture. It was a rethinking of what reasoning could mean when time becomes an actual axis of thought. Let’s quickly walk through what we covered.
We started with the limitations of modern-day architectures and how LLMs treat time as just another index and simulate reasoning by formatting outputs to appear stepwise, even though internally nothing actually thinks in steps. We then explored what a better system might look like, one where reasoning lives in the latent space, evolves over internal ticks, and can adapt its compute depending on the complexity of the task. From there, we dived into the CTM architecture; a neuron-level models that evolve over ticks, a memory of past activations, and a synchronization matrix that acts as a structure of agreement. We saw how these parts come together during training and inference, and how the model decides when it has “thought enough” before acting.
We then situated CTMs in context showing how they bridge the gap between recurrent and attention-based models, and how they offer an alternative to popular token-level reasoning methods like Chain of Thought or COCONUT. Then we talked about results which were promising across a range of domains from symbolic tasks and maze navigation to vision and few-shot reasoning. Finally, we reflected on what still needs work like computation overhead, synchronization semantics, learning to halt and what future improvements could make CTMs even more expressive and efficient.
With that, we close the loop and come to the end of this article. CTMs give us a fresh way to model not just answers, but the unfolding process of thought itself. This article aims to give a fresher on concept in and around the idea itself, but, I would still suggest you to go through the paper once; to understand the experiment design and extremely detailed ablation study.
Paper : https://arxiv.org/pdf/2505.05522
That's all for today.
Follow me on LinkedIn and Substack for more such posts and recommendations, till then happy Learning. Bye👋