
Byte Latent Transformers : Patches Scale Better Than Tokens
A Deep-dive into the latest advancement in tokenization from Meta, which for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency.


Recently Meta released an intriguing architecture for combining byte level tokenization and transformers at scale, which inherently not only is a better modelling choice but also opens up a multitude of potential direction for research. Let's dive into the proposed idea, but before that, let's warm up with some why? questions.
Table of content
Philosophy of Language
Language dependence on Vocabulary
Definition of Vocabulary
The ideal setup
Byte Latent Transformers (BLT) explained
Methodology
Outcome
Thoughts/Next steps
What we learnt today?
Philosophy of Language

Language is possibly the greatest invention mankind ever made, not only it helped in communication hence survival; but also, changed our brains drastically with time (you need certain lobes of brain for complex communication and language, which also overlap with the lobes required for reasoning and intelligence1).
Simply, language is an abstraction over thought, it’s basically a lossy compression of actual information/thoughts, the way we present our ideas to others, hence, it could be mathematically modelled as a function of our thoughts, surrounding and physical attributes. All of these attributes though are highly correlated yet pristine enough to stand out, evident to that point that even philosophy finds it hard to explain thoughts and language dependency and relation.
Language dependence on Vocabulary
The language being a derived entity from thoughts is dependent on vocabulary, hence, succumbs to all possible issues, for example, a certain thought possibly couldn't be represented as a physical node/token as the vocab doesn't contain the entity.
Example, a person who spent his entire life in sub-saharan desert would find it hard to define if he sees a polar bear, he might be able to make a conclusion by composition and might call it a white bear or something, but, did you noticed something? The names/description that we gave hence becomes very susceptible to the choice of vocabulary and eventually the language. BTW, which nomenclature you prefer? White bear or polar bear? (Quick hint : the closest visual you can form of the thing or the geography where the entity relates to, see again derivative nature came into play)

Another example, when I talk about Philosophy (my favourite topic) to anyone, Indian philosophy usually pops up, the strange part is, there is nothing called as "Indian philosophy", the closest is "Darshan" which means "to see/observe" whereas philosophy means love for learning (derived from Philo : learning and Sofia: love), hence, it’s not just different but erroneous, as the respective words define the approach to topic itself.
I think it is pretty evident why language is a bad abstraction of our thoughts/concepts or ideas. But, it is a necessary evil, we sustained for over 300k years. The issue starts, when given our rapidly growing intelligence (which I think exponentiated because of better modalities like visuals and structure sciences like maths), we try to teach a new being (in our case, A Machine), because our language representation in itself is vocab dependent hence flawed, results in a flawed yet trained system (no wonder we struggle on reasoning benchmarks).

Now that we know problems with language itself and our restrictions to usage of vocab, let's see how can we represent language/define Vocabulary such that its lowest in biasness for machine to learn, yet rich in representation.
Definition of Vocabulary
The vocabulary constitutes the building block of a language, it contains all the coarse information required to form a sentence, phrase or a clause. But, to feed this info to models, we need a medium.
Just for intuition, let's talk about the closest relative to LLMs, our modern day computers. How do we interact with it?
We write code in our favourite high-level language (like python).
The interpreter translates it to machine code. (Encoding)
The machine code is a very lowest level instruction set (in binary) which is then executed by CPU. (Process)
After execution the binary/machine code is converted back to usable info set. (Decoding)
The same thing happens in our LLMs, there could be multiple programming languages hence encoding strategies (multiple tokenization strategies), which could be processed and then decoded (again depends on instruction set/tokenization), hence, if step 1 is not well defined, the further process becomes useless.
This process is agnostic to encoding step if the process and processor are deterministic. In the data driven strategies (LLMs) this is not the case, hence, a good encoding assumption makes a huge difference.
For understanding more on tokenization strategies, check this comprehensive blog out :

Based on the above post, we can conclude that tokenization is an undesired dependency that has to be in place for effective communication between machine and us. But, there is an evident trade-off between structural biasness vs semantic information (entity-entity relations) as shown in below diagram.
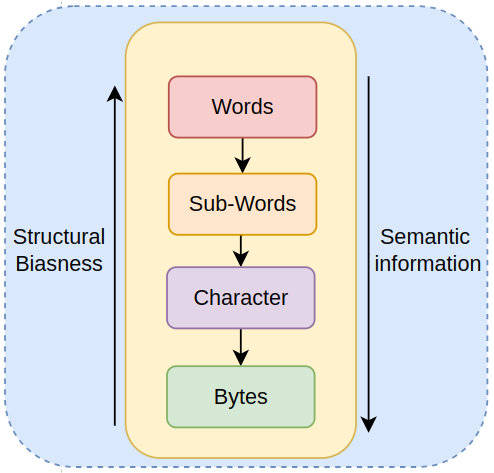
This also explains the reason of sub-word tokenization being so widely used currently. It falls in the sweet spot between structure and semantics. Another interesting observation is that with decrease in structural biasness, the amount of work done for learning semantics increases.
For understanding the working and problems with more fine-grained tokenizations beyond sub-words, make sure to hover over the below mentioned blog.

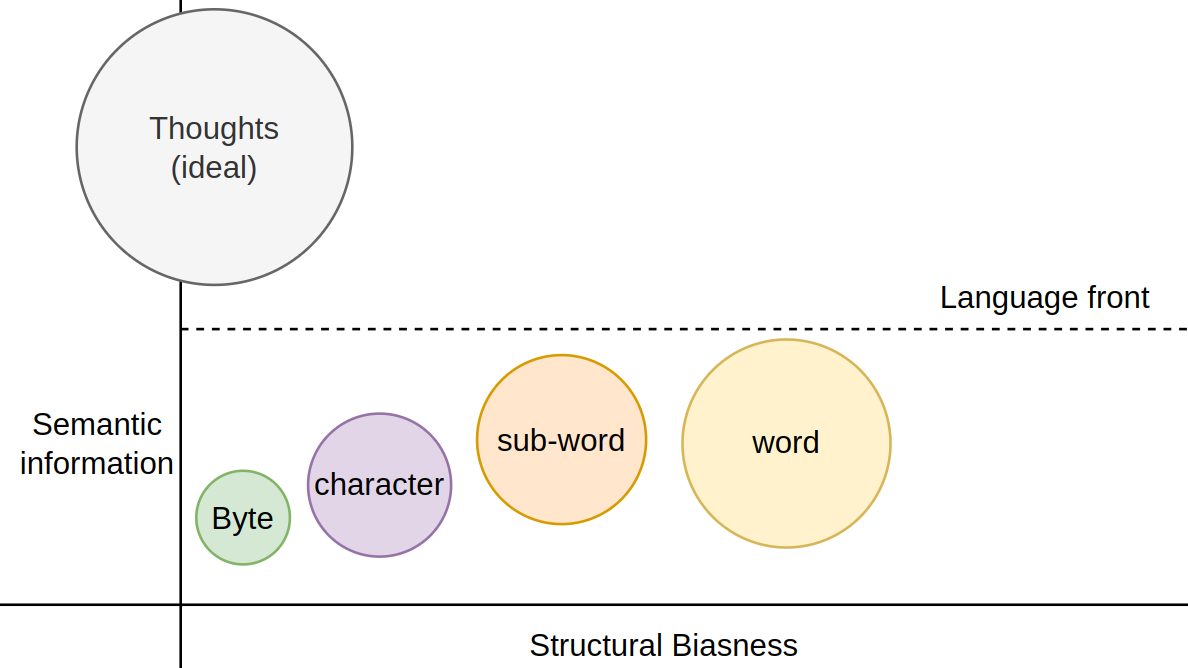
As evident from the above graphs and the blog; word level tokenization is possibly the worst, whereas entity/character level are sub-optimal and bytes is closest to true representation as there is no biasness in terms of relations/aggregation of entities (for machine), but, it's encoding/representation at scale is hard (more breaks/pieces -> more tokens -> more compute) and obviously thought is the best representation of thought. Everything boils down to good quality representations.
One final distinction between sub-word, character and byte level tokenization comes up in terms of dense compute required to learn semantic relations. Intuitively higher structural bias results in high level features and hence less work (as only final feature-set has to be learnt), for my computer vision folks out there, this is basically difference between having your learnable kernels (as in CNNs) vs static kernels (Prewitt, sobel, etc.).
We now know all about the problem and the current strategies around it now. Let's see, what ideally must be done to solve this problem completely.
The Ideal setup
We want our strategy to be low in bias, hence closest to thought (maybe something like a synapse, assuming physical nature of thoughts, that is the only thing we can model), the synapse could be physically represented as binary signals.
We need an efficient aggregation yet trainable/teachable mechanism to assimilate the low level info to a processable form/ to form relations and sub-relations.
A processor block over the aggregation mechanism to learn representation, followed by decoding block.
But, in ideal case for communication of information, only the processing block would persist, we don't need aggregator/encoder or decoder. Basically a representation to representation transfer. Imagine you can somehow transfer your thoughts directly to a model or a person (which itself would be non-material) and get response back in the same way.
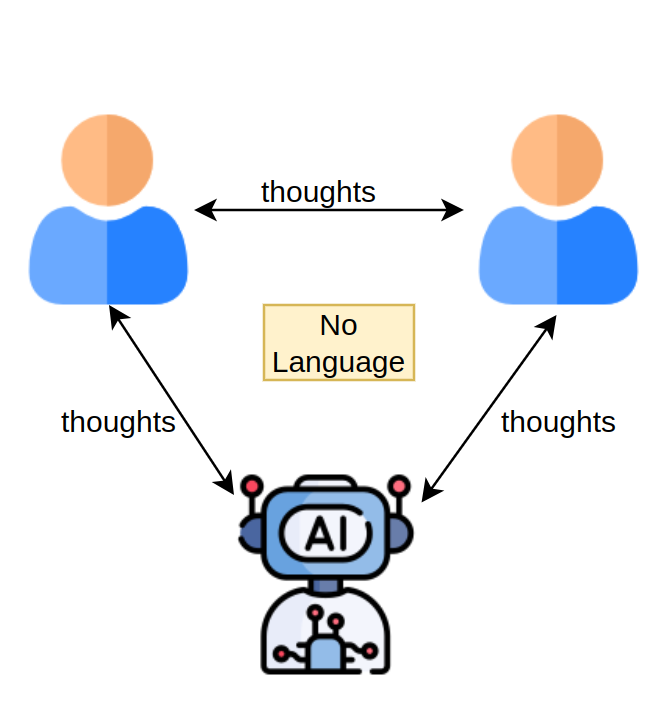
But, let's leave (4) to future humans, and stick to the next best (1, 2 & 3) which we can do. This is where BLT from meta walks into picture.
Byte Latent Transformers (BLT) explained
Given all the context above, lets formulate our objective now
Better representation : As discussed above we want a more grounded representation strategy, with lowest structural bias and seemingly lossless information sharing. Just a peek into “lossless information sharing”, any token shared to LLM is not a string, it gets converted to a number and utilized, hence that is an abstracted info for LLM, and ANY ABSTRACTION IS A BAD ABSTRACTION, in this case, bytes representation is a more agnostic and finer/simpler representation.
Better compute usage : This would be a new yet important point (but often skipped), the sentences are inherently a chain (markovian in nature), where probability of next token to be predicted is a dependent on previous one. Lets touch up this topic as well for a fair sense of understanding.

Let’s say you are flipping a coin, probability of getting heads once is 0.5, twice in a rows is 0.25 and thrice in a row is 0.125, these types of events could be modelled as a simple PMF (Probability Mass function) given by a binomial distribution (as event is discrete) as
simply, you can think of the process as sampling/selection, in our language modelling task, the probability of branch is not equal, some have more chances of occurring than others (hence, the likelihood itself might be decreasing, but after normalization probability remains pretty high for us to sample).
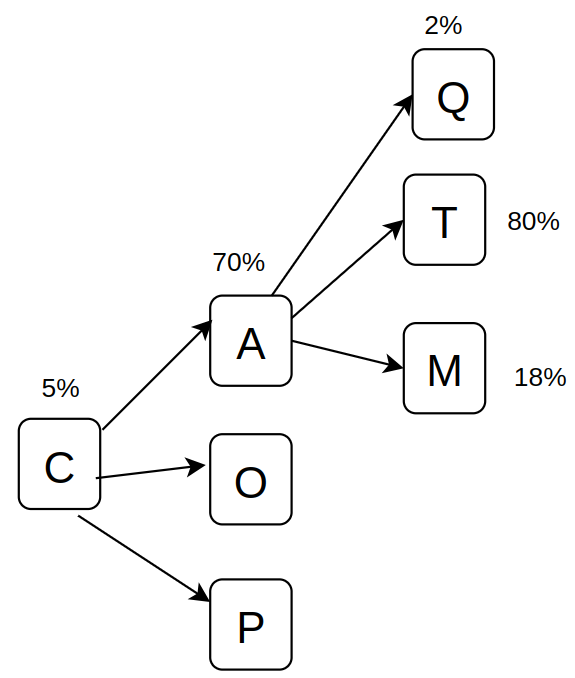
Also, if you notice probability of first token was pretty small, as the number of options that could potentially be first best predictions is pretty high (potentially the problem behind hallucinations as well). Let’s say you want to generate the phrase “Human Language”, the probability of sampling first/next token “Lang-” after “Human” is really low (too many options like “-mind”, “-being”, etc.), hence high in entropy (we will cover the relation next), but after its successful prediction the next choice is pretty simple as the number of tokens with “Lang-” as suffix are pretty low.
Relation between Probability, Information and Entropy
We won’t discuss definitions here, but, quite simply probability (P) and information (I) are inversely proportional to each other and entropy (E)is just log(information)which is a measure of how spread out things are or simply randomness (much deeper rabbit hole, but let’s just move on). Less probable events have much higher information attached to it, for example, probability of seeing an alien civilization is pretty low, but if we come in contact to one, our understanding of life itself would change, which inherently would increase our knowledge and hence increase the entropy of thoughts (possibility increased!!); also you can read about black swan events2.

Think of the below diagram and equations like this, if you have 100 options, probability of choosing any of them is 1/100, and as per the formula above, we are in high entropy state (happens in beginning of next token), whereas if we are in few choice scenarios (hence high probability) the entropy would be low (happens in mid and end of token).
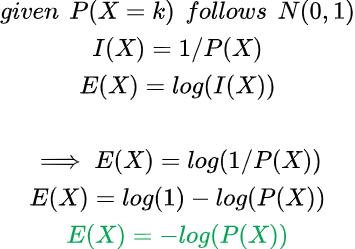
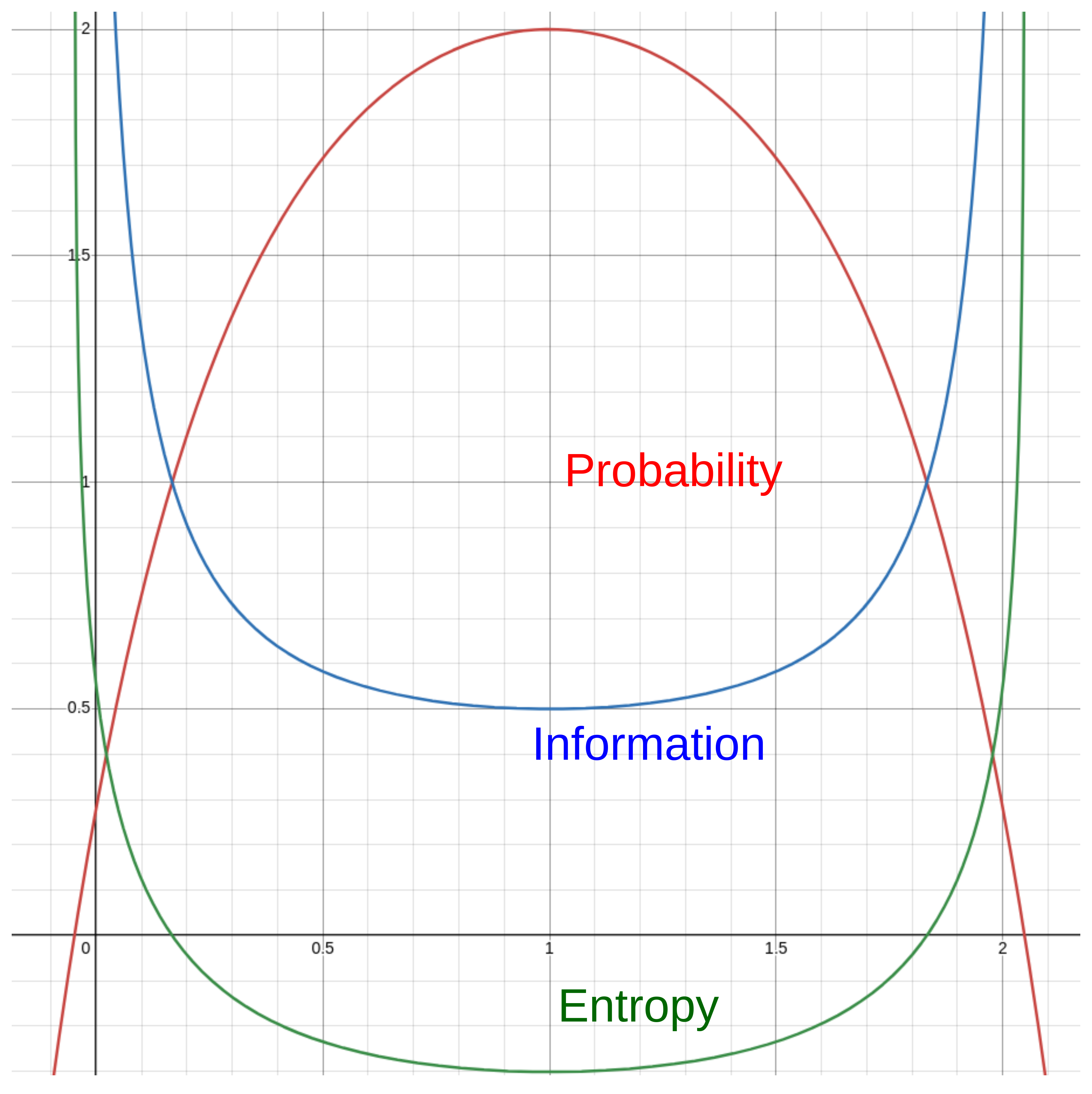
Given this knowledge, we can infer the below mentioned graph, which explicitly presents that beginning of tokens, ie. Next predictions have almost evened out probability (too many options), hence high entropy, whereas after that, the probability becomes much less spread out (as options decrease) hence low entropic state. High entropy is not a good thing as it leaves space for hallucinations.
Now we know that some parts of prediction are much important than others, hence, shouldn’t we put more focus on those parts, maybe spend some more time sampling, normalizing or applying custom algos (for search, like beam search3) on top; for better retrieval. This extra effort costs compute, and we don’t want to waste it, hence we selectively apply extra effort on high-entropy regions and that is done through better compute allocation.
Now our objectives are well-defined, lets move to Methodology section.
Methodology
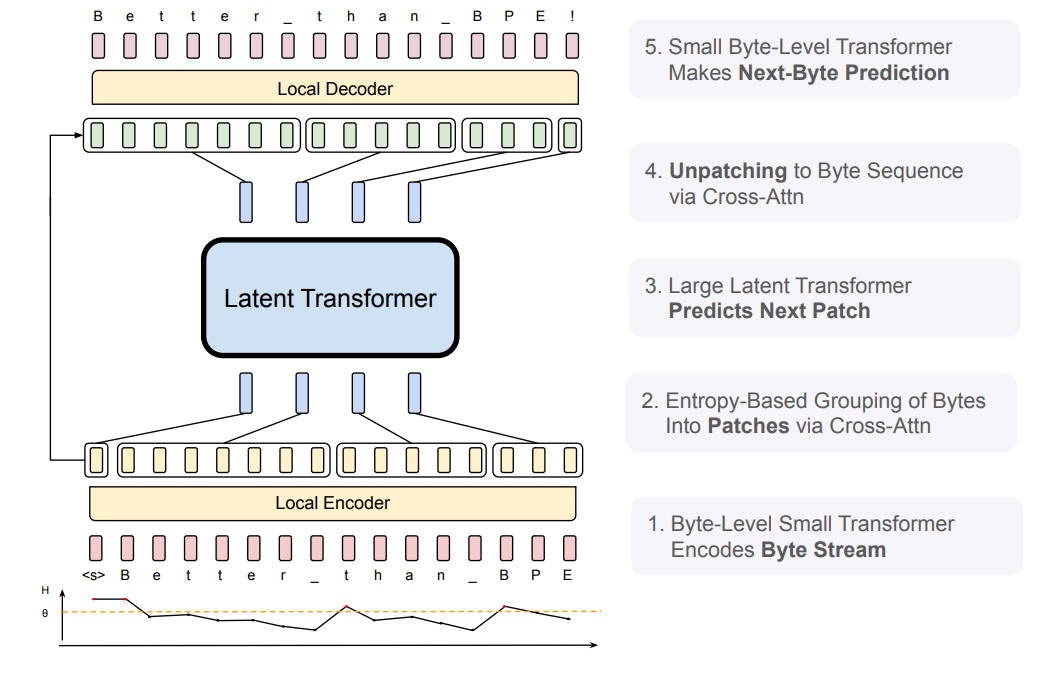
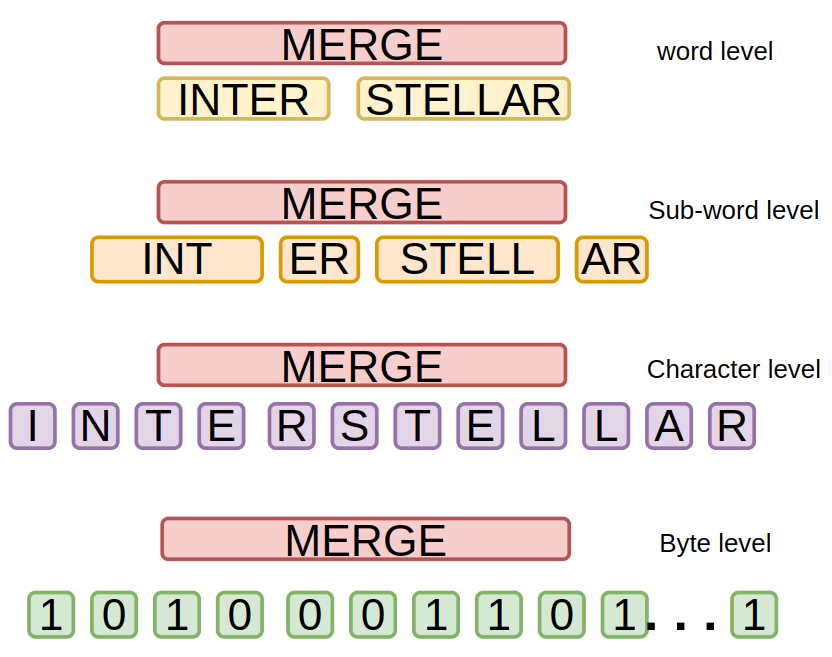
Handling Raw inputs : Raw inputs are first converted to their simplest form; as a byte (basically number) instead of traditional tokenization based allocation, where they were aggregated as sub-word and then assigned a unique ID. For example, the text "Hello" would be represented as the byte sequence [72, 101, 108, 108, 111] (as in ASCII encoding). This step is identical to character level tokenization but, bear with me, this step is precursor to something special.
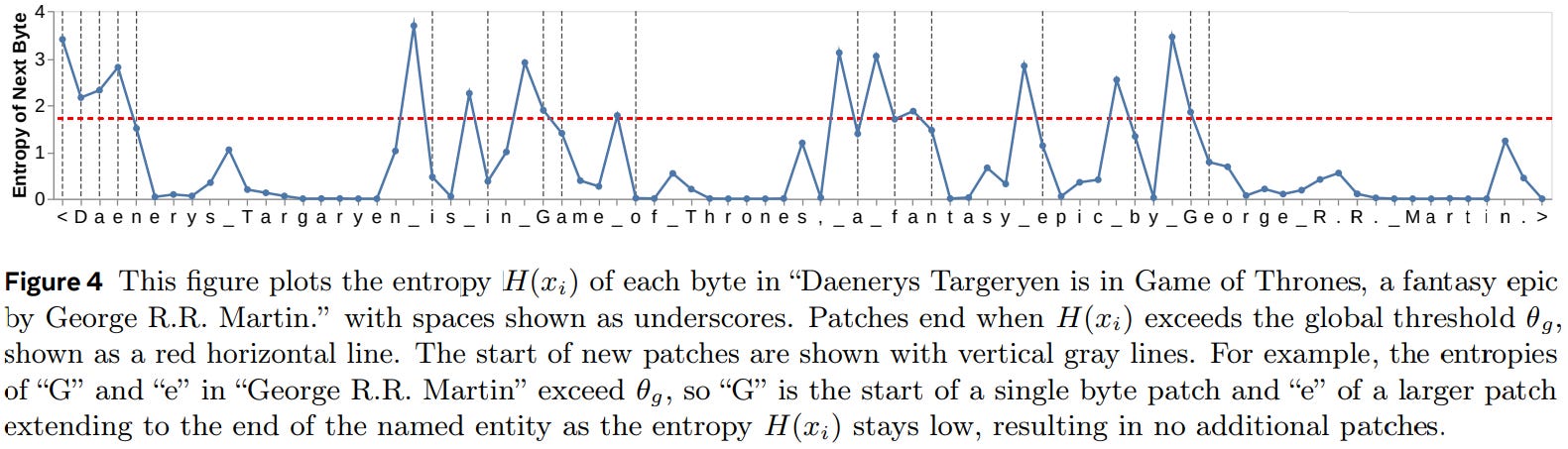
Dynamic patching : These bytes are then patched/joined together using the entropy criteria we discussed. Simply put, any sequence of bytes with low entropy are patched together, as soon as a high entropy byte is met, the previous sequence ends, and the high entropy byte becomes the new sequence. Using this process they makes multiple patches of low and high entropy bytes (basically array of variable length arrays). But, how do they compute entropy for each byte? They simply train a byte-level auto-regressive model (let's call this entropy model) and compute probability of next byte given previous byte, this probability gives us entropy (as we already discussed above). But, how do they decide when to call a byte high entropic?
For this they devised two methodsUse a global cutoff threshold, anything beyond a certain value is high entropy
Using a sort of change against previous byte, if the change is larger than a threshold it's high entropy byte.

After patching it looks something like this (vividly represented in the figure below),

Patch 1: [72, 101] --> "He"
Patch 2: [108, 108] --> "ll"
Patch 3: [111] --> "o"
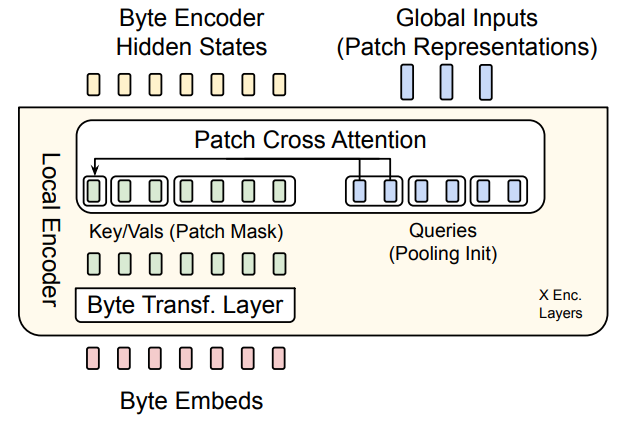
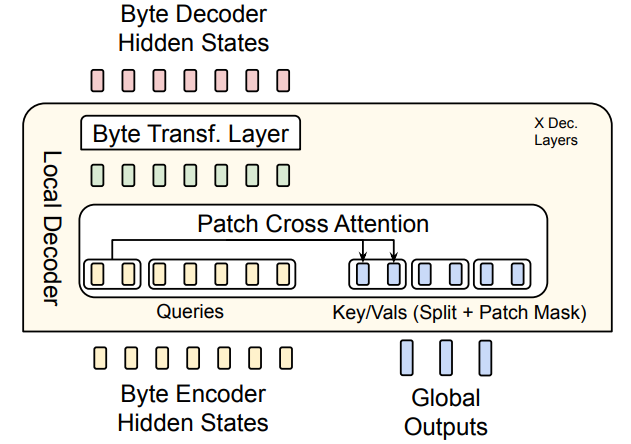
Light-weight encoder : Once we have the dynamic patches, we can start generating embeddings/representation, this is done through a lightweight encoder which consists of cross attention layer to pool byte level information to patch level information. Simply put, it is a attention block where patched byte representation serve as query and byte level representation serve as key/value.
Each byte for each patch is converted to a dense embedding, which are then operated by sequence of cross-attention block. This helps in patch level feature aggregation by transcending from low-level features to high-level features.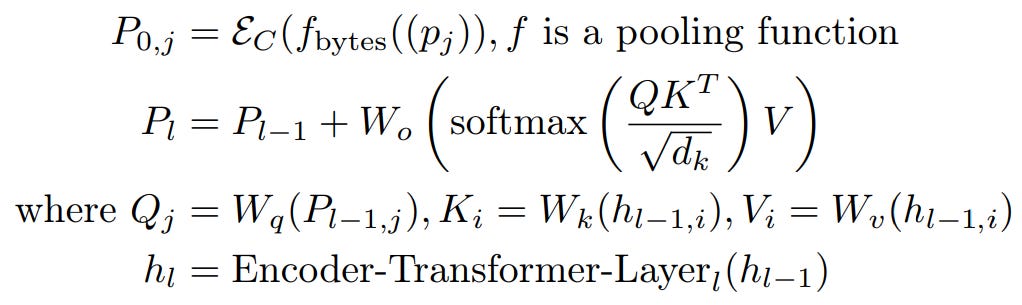
let fbytes(pj ) denote the sequence of bytes corresponding to patch, pj These embeddings are then augmented with hashed embeddings derived by making multiple n-grams (paper specified it to be in range 3 to 8) this is like looking 3 steps behind, then 4 steps behind and so on, eventually preserving knowledge of each look-backs, these embeddings are then added to byte level representation.
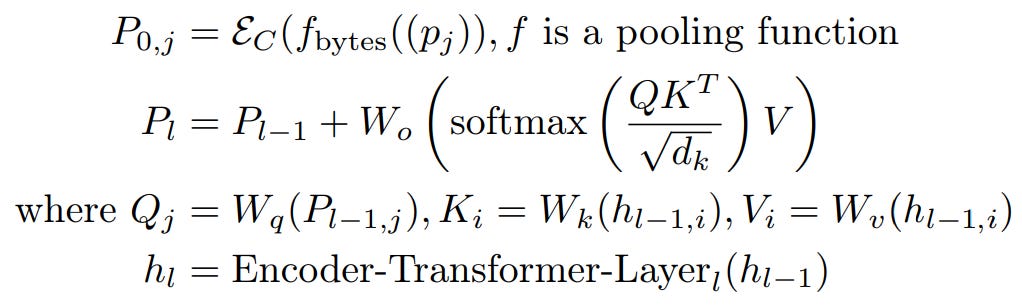
Latent global transformer model : This is the central part of architecture. It's an auto-regressive transformer to map the patch level representations from the encoder to the output space. Also, this is the part where compute allocation happens, but, it's quite subtle hence beautiful.
In older architecture when we used to break tokens, every tokens was given equal importance as they were broken mostly by context and frequency, but, here patches are broken by entropy, hence, let's say after break, you have 2 patches with you, importance of each would be equal, yet the size and intrinsic information of the patch makes all the difference, as the model has to put equal amount of weightage to a larger patch and a much smaller patch.
Imagine you have 2 patches, model is spending 10 units of power for each patch, hence power allocated is 5 units each. Let's say first patch had 10 bytes, power per byte is now 0.5 whereas for the 2nd patch (let's say it contains 2 bytes) the power per byte is 2.5, which is 5x difference.
From an attentional perspective it could be thought like this, let's say you have 5 colored balls (red, green, sky blue, navy blue, turquoise), you want to learn as much as info possible, blue colored ones are easier to patch and hence learn together, but red and yellow are quite distinct, hence, you would want to put more attention to them, and the cross correlation matrix for your model should be (3x3) (for each unique colored ball/distinct information).
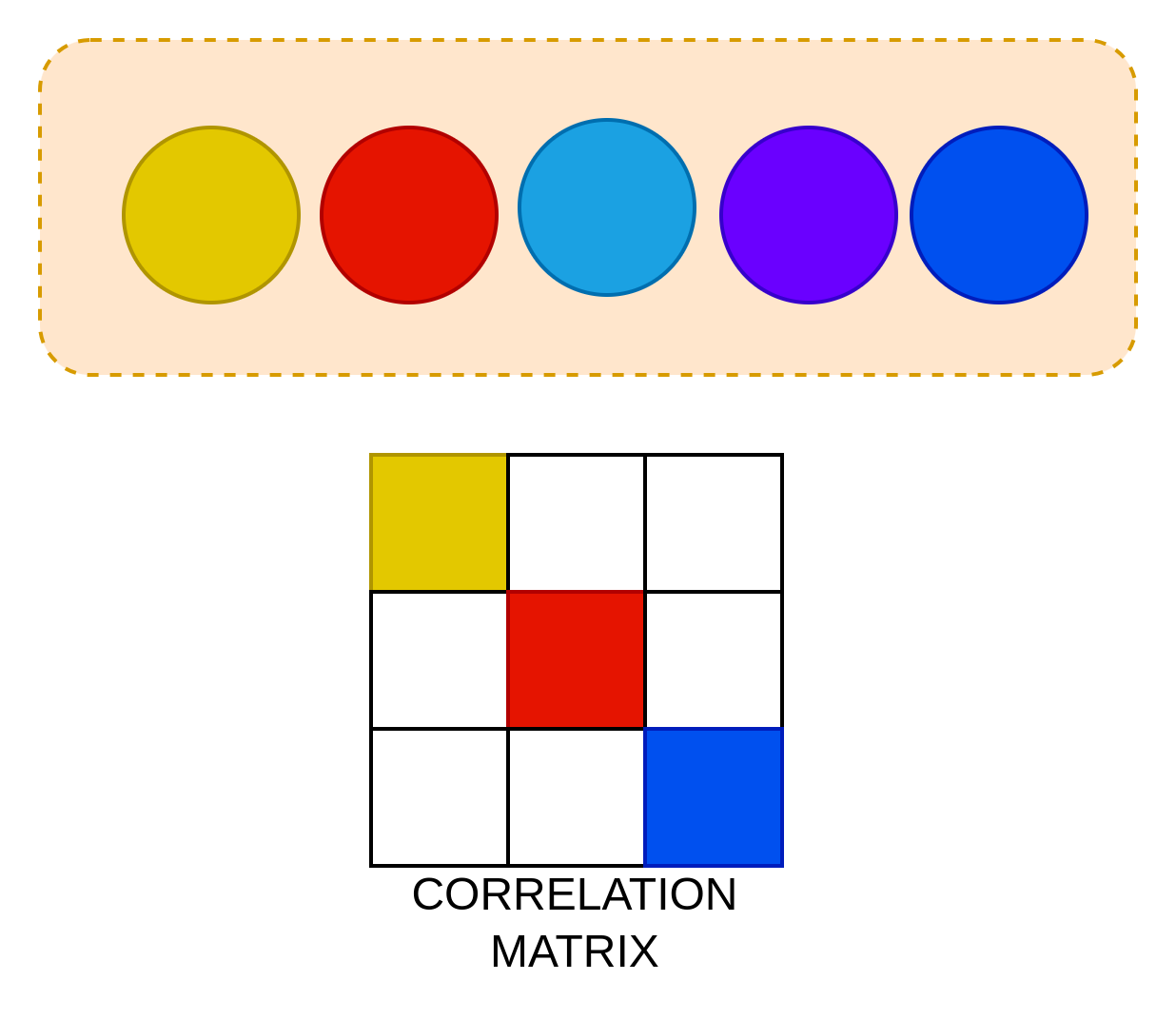
Hence, compute allocation is not a external property, but an inherent trait that is a result of information aggregation due to dynamic patching.
Lightweight Decoder block : Once we have representation in output space from previous block, we can start decoding it. Simply, it's exact encoder architecture but reversed, here the cross attention is reversed, the byte representations are queries and patch level representations are key/value.
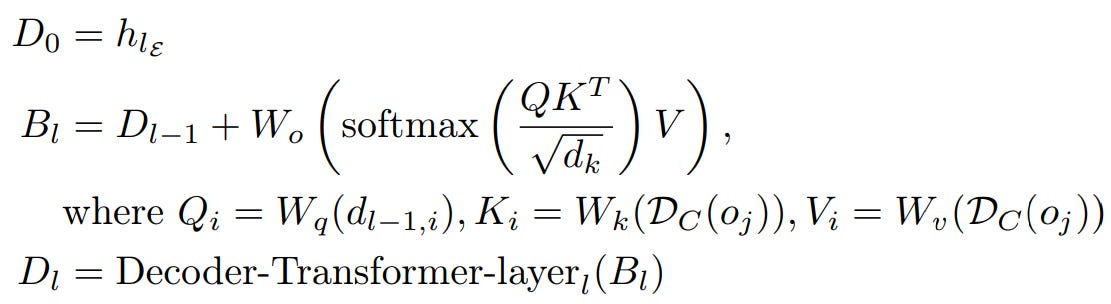
The initial byte-representations for the cross-attention are initialized as the byte embeddings from the last encoder layer i.e. hlE . The subsequent byte-representations for layer l, dl,i are computed as per above equation. The result of this block is unpatched sequence / byte level representation which is then projected out for next-byte prediction.
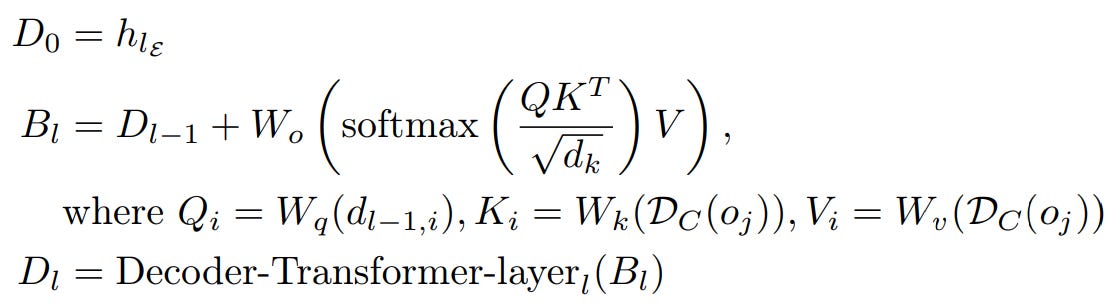
Extra information
Though the architecture is trained in a standard setup, but some points to note:
The pre-training dataset is composed of Llama2 dataset and a newly introduced dataset BLT-1T (1 trillion tokens from public sources).
Llama3 tokenizer is used as baseline.
The entropy model in step 2 of methodology is a 100M parameter transformer architecture.
For large scale run of entropy model it is reset for every new lines and constrained by a sort of moving average.
Outcome
A seemingly efficient and scalable architecture, as the tokens are not directly dependent on number of words / length of sentence.
No dependency on tokenization results in a more fine grained representation evident in the results.
Interestingly the patching strategy makes the model more robust, as the scope of hallucination is greatly reduced.
Thoughts/Next steps
Can the Entropy model be part of the training process itself? Constrained for optimization over chunk size (similar to optimal transport in SwaV4)?
Instead of threshold based entropy decision can we have a hyper-network which allocates every sub-patch a binary score (in vs out).
Anyways the paper presented a really thought-provoking yet subtle idea which could be huge given the doors it open for the further research.
What we learnt today?
Philosophy of language and its important yet limiting dependence on vocabulary.
What does vocabulary even mean? and its connection with tokenization.
Issues with current tokenizers and possible ideal setup to overcome them.
Walkthrough over the entire idea presented in BLT paper and how could we interpret the steps as well as the architecture in detail.
What else could be done for further improvement / Next steps.
For further nuances and details, please go through the paper here : https://arxiv.org/pdf/2412.09871
That's all for today.
We will be back with more useful articles, till then happy Learning. Bye👋
https://www.mdpi.com/2079-3200/10/3/42
https://en.wikipedia.org/wiki/Black_swan_theory
https://en.wikipedia.org/wiki/Beam_search
https://arxiv.org/abs/2006.09882