
DeepSeek OCR : Contexts Optical Compression
DeepSeekOCR is an attempt to bridge the gap between semantics & context through tokenization-free architecture by applying the techniques from ViT based modules onto document understanding and OCR.

Table of contents
1. Introduction
In the modern intelligence stack, Information Retrieval (IR) and document parsing have evolved from being mere administrative utilities to becoming the absolute bottleneck of the reasoning paradigm. We live in a world governed by dense PDFs, complex financial schematics, and nested mathematical structures; the ability of a system to “ingest” this data is no longer just a feature; it is the primary constraint on its intelligence. At its most abstract level, Optical Character Recognition (OCR) is simply an Image-to-Text (I2T) task, a bridge meant to translate raw pixel-level signals into semantic strings.

However, for a decade, that bridge has been brittle. Traditional approaches have treated OCR as a literalist exercise which is to have a “find-and-replace” function for the visual world. DeepSeek-OCR shatters this convention. It is not just another incremental I2T model optimized for higher accuracy; it represents a fundamental shift in the representational aspect and modeling choice of the data itself.
By moving away from the “literal string” and toward the concept of Contextual Optical Compression, DeepSeek-OCR treats the visual document as a dense, high-entropy signal that can be modeled and compressed directly into latent intelligence. It moves us beyond the era of “reading” pixels and into the era of modeling visual context, proving that the way we represent document data is just as important as the model that processes it.
The Representational Shift: Moving Beyond the String
Imagine for a moment that we stop treating text as the primary query to an LLM. Instead of feeding a model a sequence of discrete, one-dimensional text tokens, we use a visual-first head. Instead of a string of 1,000 words, we feed the model a single image containing those words.
In this paradigm, we discard the traditional tokenizer entirely and instead apply a Visual Markovian Blanket which is a spatial inductive bias that assumes a pixel’s meaning is derived from its neighborhood (a dependency already elegantly managed by modern attention mechanisms; (remember Swin transformers/ViTs).
The economic and computational implications are staggering:
The Token Tax is Abolished: You no longer pay for each individual word. A single image containing 100 or N words can be structurally broken into just 16 or K visual patches (where K < < N).
Efficiency by Order of Magnitude: Where a standard tokenizer would demand 130 “word-tokens” to represent a paragraph, the visual-first approach represents the same semantic density in a fraction of the “patch-tokens.”
This is the shift DeepSeek-OCR targets. It is far more than a tool for Optical character recognition; it is a fundamental challenge to our representational assumptions. It proves that by treating the visual modality as the primary compression primitive, we can bypass the “Tokenization Bottleneck” and move toward a more dense, efficient form of machine intelligence.
2. How OCR is Typically Done
To understand why a shift is necessary and solvable, we must first look at the traditional anatomy of document intelligence. At its most fundamental level, OCR is an Image-to-Text (I2T) translation problem. It is the process of taking an unstructured, high-dimensional grid of pixels and mapping it onto a structured, one-dimensional sequence of characters. However, in the legacy paradigm, this translation is rarely a direct flight; it is a series of layovers.

2.1 The Fragmented Pipeline
The industry-standard framework has historically relied on a “Divide and Conquer” strategy, typically consisting of three decoupled stages:
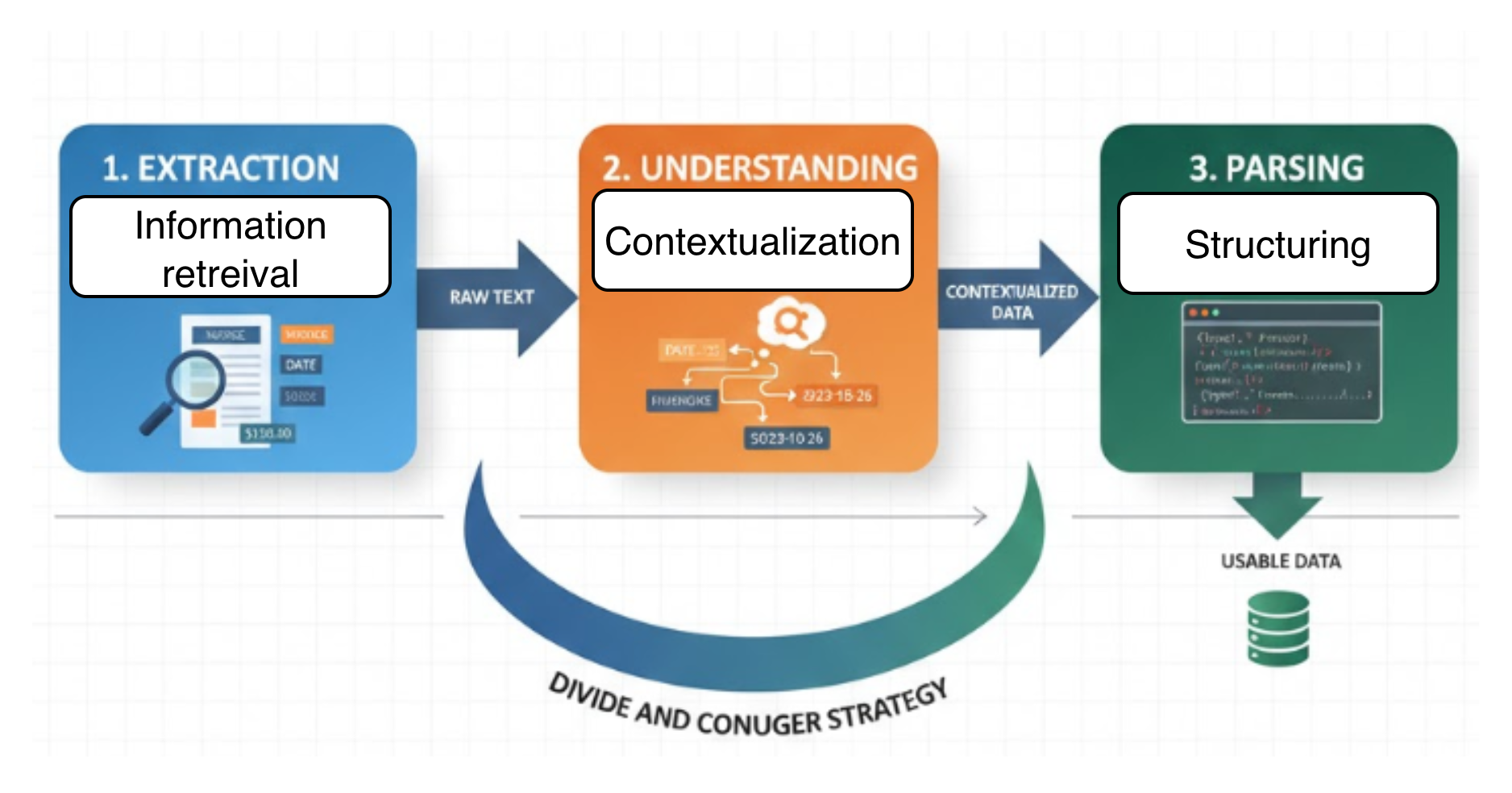
Extraction: The “dumb” phase. Using object detection (to find text boxes) and primitive recognition, the system simply fetches raw text strings from the image.
Understanding: The “contextual” phase. Once the text is a string, a secondary model (often an NLP-based one) tries to infer the relationship between those strings.
Parsing: The “structural” phase. The system attempts to reconstruct the data into a usable format, like a JSON table or a Markdown list.
In this world, we rely on a fractured ecosystem of libraries and methods. We see tools like Tesseract for raw engine work, EasyOCR or PaddleOCR for deep-learning-based detection, and specialized layouts like LayoutLM for attempting to stitch the meaning back together.
2.2 The Diminishing Quality of Representation
The fatal flaw of this decoupled approach is the Representational Bottleneck. Because Extraction is treated merely as a task of “fetching text,” the structural and spatial metadata of the document are often discarded the moment the pixels are converted to strings.
As information moves down these modules, we see a diminishing quality of data. If the extraction phase misidentifies a column boundary in a financial table, the “Understanding” module receives a jumbled string of numbers with no spatial context. No amount of downstream intelligence can fix a corrupted upstream representation. The extraction phase becomes a “leaky bucket,” where the semantic richness of the original visual layout is drained away long before it reaches the final parsing stage.

By the time we get to structural understanding, we aren’t working with the original document anymore; we are working with a low-fidelity, “noisy” ghost of it.
3. Compression as Geometric Discovery leading to Intelligence
To understand why DeepSeek-OCR treats document parsing as an exercise in Optical Compression, we must move beyond the idea of “shrinking files” and enter the realm where intelligence meets Group Theory. In the framework of modern AI, intelligence isn’t just about storing data; it is the process of discovering and utilizing the symmetries of space.
3.1 Intelligence as the Exploitation of Symmetry
A document is not a random collection of pixels. It is a highly structured manifold governed by geometric and semantic “rules” lines of text follow translation symmetries, tables exhibit grid-based permutations, and headers maintain scale-invariant hierarchies.
From the perspective of Group Theory, these patterns are elements of a symmetry group G acting on the document space X.

An “intelligent” model is one that learns the invariants of these transformations. It realizes that a “Paragraph” remains a “Paragraph” whether it is shifted, scaled, or slightly rotated. By “solving” for these symmetries, the model effectively compresses the problem domain: instead of learning every possible pixel arrangement, it learns the fundamental group of document structures.
3.2 The ELBO and the Geometric Squeeze
This discovery of symmetry is mathematically enforced by a constraint optimization setup; which in my opinion could be easily represented during training by something like Evidence Lower Bound (ELBO) in VAE.
 with PyTorch - Alexander Van de Kleut")
We force the high-dimensional document signal x through a latent bottleneck z, where the model must find a representation that is both compact and reconstructible (be mindful; this isn’t the exact setup; this is just for mental model for connecting ideas of compression and retrieval):
The KL Divergence term acts as a geometric pressure. It forces the model to map diverse document inputs into an overlapping latent distribution. This overlap is where intelligence is born: for two different images of a table to occupy the same region in latent space, the model must have successfully discarded the superficial “noise” of pixels and extracted the underlying symmetry of the table structure.
3.3 The Optimal Overlap: A Semantic Manifold
If the model fails to compress (low KL pressure), it merely “memorizes” the pixels, resulting in a sparse, disjointed latent space with no understanding. But by forcing the distributions to overlap just enough, the model is compelled to explore the topology of the data.
It begins to understand that the “transformation” from a raw image to a structured Markdown table is a path along a semantic manifold. In DeepSeek-OCR, this means the vision tokens aren’t just smaller versions of the image; they are dense, geometric “keys” that unlock the underlying logic of the page. Intelligence, therefore, is the ability to navigate this compressed space where symmetry has turned chaotic pixels into a coherent, navigable map of information.
4. Quantifying Compression through Matrix Decomposition
To measure the “work” of DeepSeek-OCR, we need to move from the abstract “bottleneck” of the previous section into the hard mathematics of Information Theory. If Section 2 identified the fractured pipeline of traditional OCR, Section 4 provides the mathematical tools to evaluate how a unified architecture handles the signal-to-noise ratio.
4.1 Decomposing Document Intelligence: SVD vs. Auto-encoders
The most intuitive way to visualize document compression is through Singular Value Decomposition (SVD). Any document image, represented as a matrix A, can be decomposed into:
In our specific context of document intelligence, these matrices are not just numbers as they represent the functional stages of the OCR process we discussed in Section 2:
U (The Encoder/Extraction): These are the left singular vectors. They represent the basis of the “Visual Language.” This is the map/function that extracts high-frequency features (edges, glyphs) and compresses them into a latent coordinate system.
Sigma (The Understanding): The diagonal matrix of singular values. This represents the semantic weight or the “relevance” of each feature. A high singular value corresponds to a structural truth (like a paragraph boundary); a low value is negligible noise. It acts as the “Understanding” bridge, deciding which parts of the visual signal are essential for the reconstruction of the document’s logic.
V^T (The Decoder/Parsing): These are the right singular vectors. They define the “Output Space” which in our case is the structured text or Markdown. They take the compressed energy of U and Sigma and reconstruct it into a readable, parsed format.
, Demystified | Towards Data Science")
While SVD is linear, an Auto-encoder (like the one in DeepSeek-OCR) is the non-linear generalization of this process. It learns to perform this “Decomposition” using neural weights, seeking to represent 1,000 words of text not through 1,300 text tokens, but through a handful of Dense Vision Tokens.

This is also one of the reason why Generative models flourish because they are dual-purpose machines: they are Compressors (mapping data to latents) and Samplers (generating data from latents). In the case of images, we derive Latents (as in VAEs) which occupy a much lower dimensionality than the pixel space and is able to learn and use the shared feature space.
4.2 Entropy and the Retrieval Tax
The efficiency of this compression is measured by the gap between the True Information Density (P) and the Model’s Distribution (Q).
Entropy H(P): The absolute minimum number of bits needed to represent the document.
Cross-Entropy H(P, Q): The number of bits our model actually uses.
\(H(P, Q) = -\sum_{x} P(x) \log Q(x)\)The goal of a good model is to minimize the Kullback-Leibler (KL) Divergence (H(P,Q) - H(P)), which we can think of as the Retrieval Tax. If the model is poorly designed, it pays a high tax using thousands of tokens to represent simple text. DeepSeek-OCR lowers this tax by ensuring its vision tokens are “Entropy-Dense.”
5. The Inductive biasness with representation
If intelligence is the discovery of symmetry, and compression is the metric of that discovery, we must eventually ask: What stops us from reaching the absolute Shannon Limit? The answer lies in Inductive Bias; it is the set of introduced assumptions that a model takes to predict the unknown. While these biases allow models to learn from limited data, they also act as a mathematical “floor” that restricts how far we can compress a representation.
5.1 The Weight of Representation
Representation is the “alphabet” of the model’s universe. If your representation is inefficient, the model is forced to expend its cognitive energy just to manage the data, rather than reasoning about it. In document parsing, a poor representation doesn’t just take up more memory; it actively obscures the structural symmetries we discussed in Section 3.
5.2 The Markovian Blanket and the Image Constraint
In the visual domain, our primary inductive bias is the Markovian Blanket (or spatial locality). We assume that a pixel’s meaning is primarily defined by its immediate neighbors.

In Convolutional Neural Networks (CNNs) or standard ViTs, this bias is “hardcoded.” The model assumes that “context” is something that scales spatially. While this is great for detecting a character, it is a bottleneck for Optical Compression.

If the model is forced to treat every (16x16) patch as a semi-independent unit, it cannot easily “collapse” a whole page of repetitive text into a single latent vector. The Markovian assumption forces the representation to remain “wide” even when the information is semantically “thin.”
5.3 The Tokenization Bottleneck
The most restrictive bias, however, is Text Tokenization. We have been conditioned to believe that the “Token” (Byte-Pair Encoding or WordPiece) is the fundamental unit of meaning.

This is a fallacy of representation. Tokenization is a discrete, human-engineered inductive bias that assumes the “string” is the optimal way to store context. But tokens are actually quite high-level; there is significant semantic redundancy within and between tokens.
The Reality: You can actually compress information below the token level.
The Vision Advantage: Images do not have a fixed “vocabulary” in the way text does. By bypassing text tokenization and mapping pixels directly to a latent “Contextual Vision Token,” DeepSeek-OCR can achieve a higher density of information than a string ever could.
Let’s compare the theoretical lower bounds of compressing a simple repeated phrase: “The quick brown fox jumps over the lazy dog.” (Approx. 44 characters). Text Tokenization Representation
Using a standard tokenizer (like Llama-3), this sentence is roughly 10 tokens.
If each token is a 4096-dimensional vector (FP16), the “cost” of representing this sentence is fixed by the token count. You cannot represent 10 tokens with 5 tokens without losing the discrete identity of the words.
Lower Bound: 10 Vectors.
This means under any circumstance; the information cannot be further compressed with chance of 100% retrieval/re-extraction. Obviously we can apply weighted averaging/pooling; but all of that will be lossy compression by nature.
6. The Ideal Case
If we accept that tokenization is an artificial ceiling, we must look toward a “cleaner” way of teaching models to ingest the world. This brings us to the Visual Learning Paradigm; which is the idea that the most efficient way to understand complex systems isn’t through the granular reconstruction of strings, but through the holistic absorption of visual information.
6.1 Learning Without the “String”
Human cognition doesn’t operate by tokenizing reality. When you look at a dense deck of cards, a complex architectural blueprint, or a random string of numbers, your brain doesn’t necessarily convert them into a 1D sequence of characters to “store” them. Instead, you utilize spatial memory and visual grouping.
In the world of LLMs, we are seeing a shift toward this “token-free” or “visual-first” future. My previous explorations into BLT (Byte Latent Transformers) and LCMs (Large concept Models) touched on this.

The realization that the discrete nature of text tokens is actually a barrier to semantic fluidity, by removing the text-tokenization layer we allow the model to learn directly from the continuity of the signal.

6.2 Visual Tokens as a Semantic Proxy
In the “Ideal Case” of DeepSeek-OCR, the Visual Token (this we will discuss in next section) acts as a superior proxy for the Text Token. We can model this relationship through the lens of Cross-Entropy between two distributions:
P (The High-Dimensional Visual Distribution): The raw, continuous reality of the document.
Q (The Discrete Text Distribution): The fragmented, tokenized approximation of that document.

Traditional OCR tries to force P into Q, losing the “connective tissue” of the layout in the process. DeepSeek-OCR, however, stays in the visual domain for as long as possible. It maps P to a set of Contextual Latents that are “Token-Agnostic.” This allows the model to preserve the Symmetries/redundancy and abstractions (translation, scale, grid) we discussed earlier, ensuring that the “Information Density” remains higher than what any BPE-based tokenizer could ever achieve.
By treating the visual modality as the primary representational primitive, we aren’t just doing “better OCR.” We are moving toward a Visual-Contextual Intelligence where the model learns the “concept” of the document before it ever worries about the “spelling” of the words. It is a transition from literal transcription to a deep, compressed understanding of the world’s visual data.
7. Methodology: The Architecture of Optical Context Compression
7.1 Visual Tokens as a Semantic Proxy
In this architecture, the Visual Token is the primary currency. We can model this relationship through the Cross-Entropy (H) between the true visual-structural distribution of the document (P) and the model’s textual representation (Q):
In traditional OCR, Q is a rigid, discrete text-token distribution. This creates a “lookup table” bottleneck as text tokens are 1:1 mappings from a fixed vocabulary. DeepSeek-OCR, however, treats visual tokens as continuous vectors generated directly from pixels.
Unlike discrete text tokens, these visual latents exist in a continuous embedding space, allowing them to capture “inter-token” nuances like typography, spatial relationships, and layout density that are lost in a string representation. By minimizing the cross-entropy at the source, the model ensures that each visual token acts as a dense, high-capacity proxy for approximately 7-10 text tokens, effectively bypassing the limitations of human-engineered tokenizers.
7.2 The Logic of Contextual Optical Compression
Why is “Optical Compression” the only logical step forward? In the current LLM landscape, we are hitting a Token Wall. If a document requires 10,000 text tokens to represent, that is 10,000 discrete steps of attention.
DeepSeek-OCR flips the script: instead of treating images as “extra” data that adds to the token count, it treats the Image as a Compression Primitive. The paper identifies that a document image is naturally redundant (white space, repetitive headers, standard font structures). By identifying these Symmetries, the model performs a “lossy but semantically perfect” compression. It is the visual equivalent of a ZIP file for context: it strips away the pixel-level noise while preserving the “structural essence” required for reconstruction. This allows for a massive reduction in the context window footprint, enabling 97% accuracy while using an order of magnitude less compute.
7.3 Data Engine: Training on a 30M-Page Multimodal Corpus
To ground the theoretical “Contextual Optical Compression” in reality, DeepSeek-OCR was forged in a massive, high-diversity data engine. The training corpus is designed to balance literal transcription with a deep understanding of structural and specialized visual languages.
The data mix is roughly structured as follows:
OCR 1.0 (30M Page PDF Backbone): The primary training data consists of 30 million diverse PDF pages collected from the internet. This set is truly global, spanning over 100 languages.

Tiered Annotation: To teach the model both basic recognition and advanced layout understanding, DeepSeek used a “Coarse-to-Fine” strategy. 25 million pages received Coarse Annotations (basic text extraction via fitz), while 4 million high-priority pages (2M Chinese, 2M English) were processed with Fine Annotations. These fine labels use advanced layout models (like PP-DocLayout) and OCR engines (like MinerU) to construct a detection-and-recognition interleaved dataset, essentially teaching the model the “grammar” of the page.
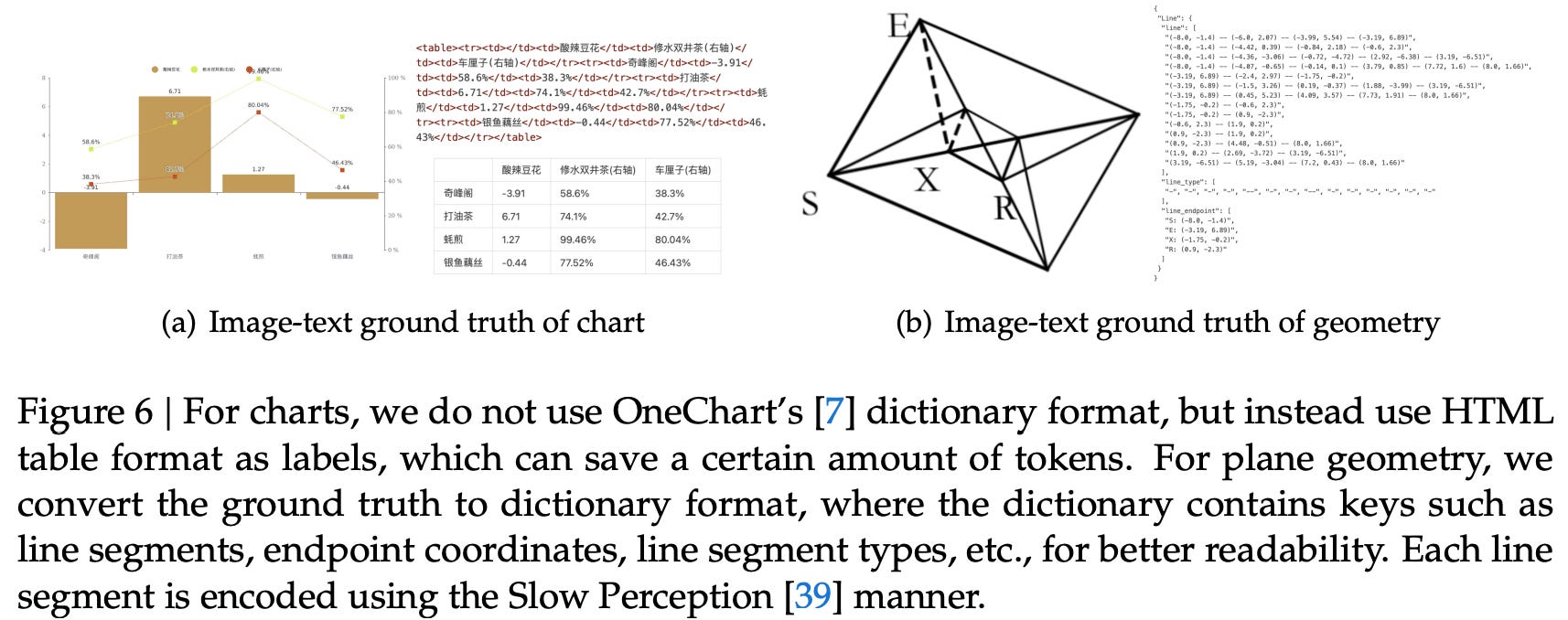
OCR 2.0: The Specialized Visual Language: DeepSeek identified that standard OCR fails at non-linear text. To solve this, they included a massive synthetic dataset known as “OCR 2.0”:
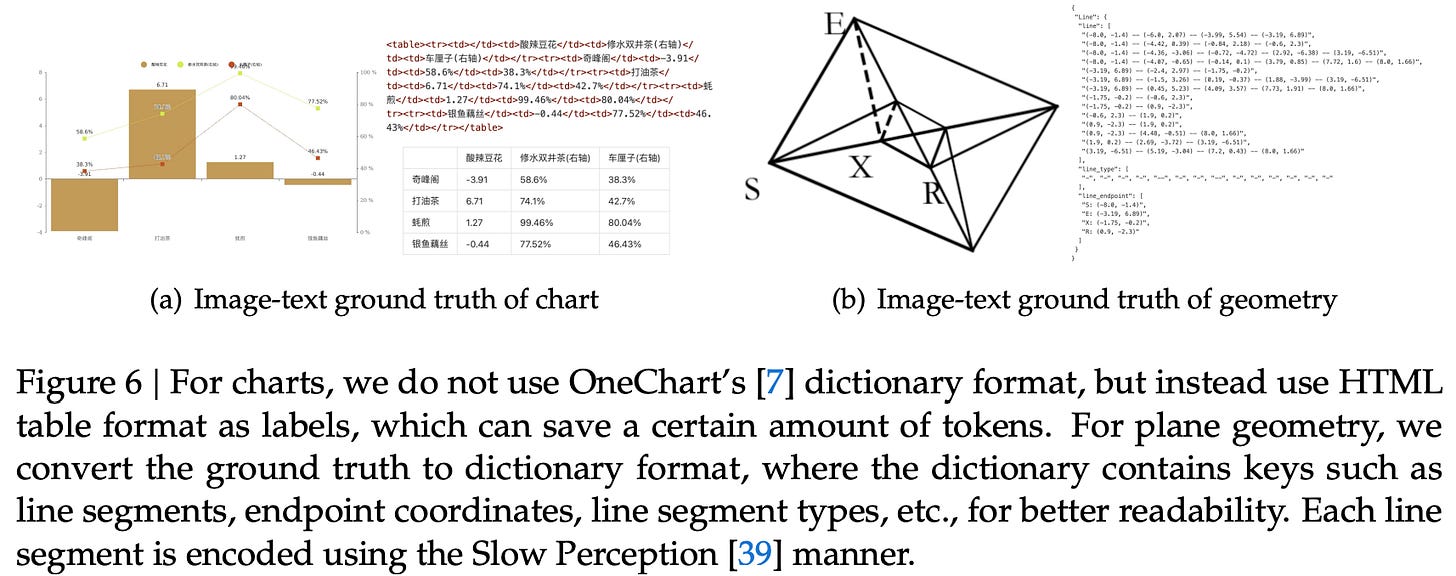
10 Million Synthetic Charts: Rendered via pyecharts and matplotlib to teach the model to parse axes, legends, and data points.
5 Million Chemical Formulas: Ensuring the model understands molecular bonds and sub/superscript notations.
1 Million Geometric Figures: For parsing diagrams and blueprints.
General Vision & Text Supplements: To prevent the model from becoming a “narrow” OCR specialist, the training includes 20% general vision data (10M images from LAION and Wukong with detection/grounding labels) and 10% text-only corpus. This ensures the 3B-MoE decoder retains strong linguistic reasoning and general scene-understanding capabilities.

7.4 Dynamic Resolution & Gundam Mode
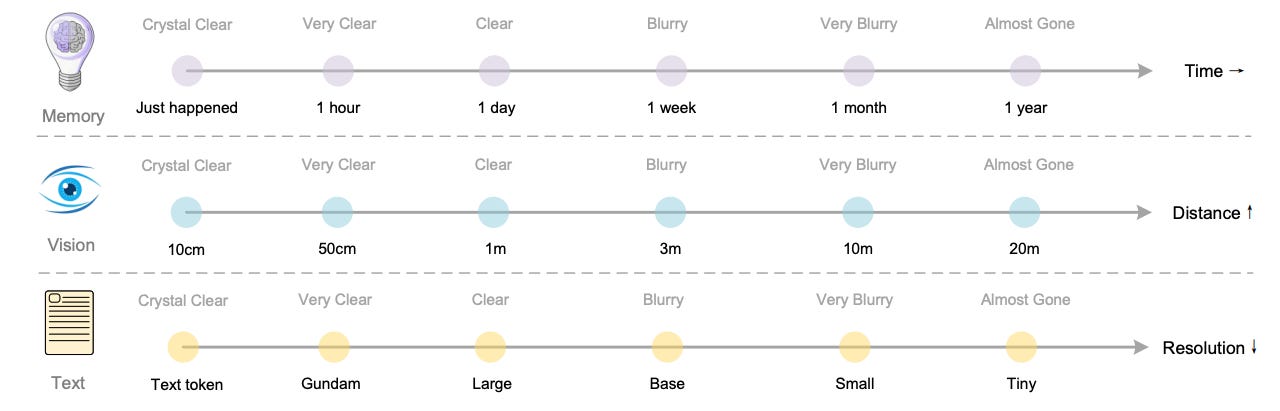
The model’s handling of resolution is a direct implementation of the “Entropy-Matching” theory we discussed. Instead of a fixed grid, it uses a multi-scale sampling strategy:

Native Scaling (Tiny to Large): The model supports native inputs from 512² up to 1280². During inference, you choose a “flavor” based on document density. A simple receipt might only need 64 vision tokens (Tiny), while a dense academic paper utilizes 400 tokens (Large) to resolve tiny mathematical symbols.
The Gundam Protocol (Tiling): For ultra-high-density documents that break the 1280px barrier, DeepSeek-OCR activates “Gundam Mode.” This utilizes a Dynamic Tiling strategy (similar to InternVL) where the image is split into multiple (640 x 640) local tiles combined with a single (1024 x 1024) global thumbnail. This “Gundam” assembly allows the model to zoom into local details without losing the global structural context, supporting effective context compression for even the most complex newspaper layouts.
7.5 Model Architecture
The actual “engine” of DeepSeek-OCR is a unified, end-to-end Vision-Language Model (VLM) that collapses the traditional multi-stage pipeline into a single, high-efficiency path. This is achieved through two highly specialized towers and a critical mathematical bottleneck.
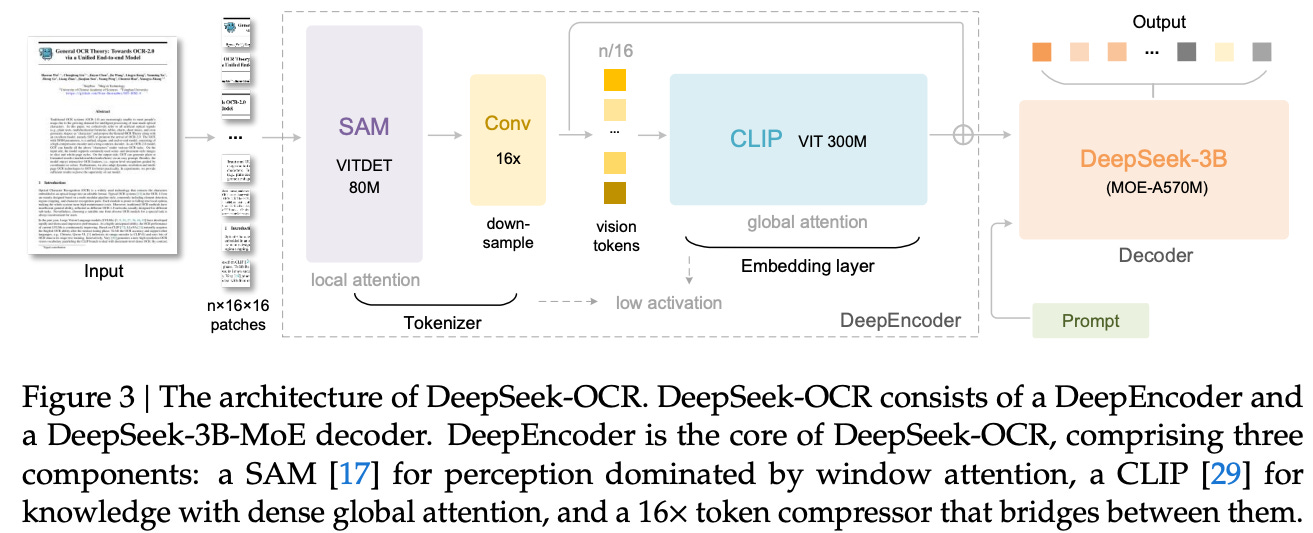
I. The DeepEncoder: Dual-Stream Perception (380M parameters)
The DeepEncoder is a hybrid vision backbone designed to solve the “Resolution Paradox” the need for high-resolution character recognition without the memory explosion typically associated with it. It uses two distinct transformers in series:

The Local Perceiver (SAM-base, 80M): Based on Meta’s Segment Anything Model, this block utilizes Window Attention. Instead of calculating global dependencies (which scale quadratically with resolution), it scans local (16 X 16) windows. This is the “detail scanner” that identifies the serifs on a font, the dot on an ‘i’, or the boundary of a chemical bond.
The Global Knowledge Base (CLIP-large, 300M): After the local scan, a CLIP-based transformer applies Dense Global Attention. This isn’t looking for letters; it’s looking for context. It understands the layout, the flow of a multi-column article, and the relationship between a figure and its caption.
II. The 16x Convolutional Bridge: The “Zip” Engine
Between these two encoders lies the most critical component: a 2-layer convolutional downsampling module.
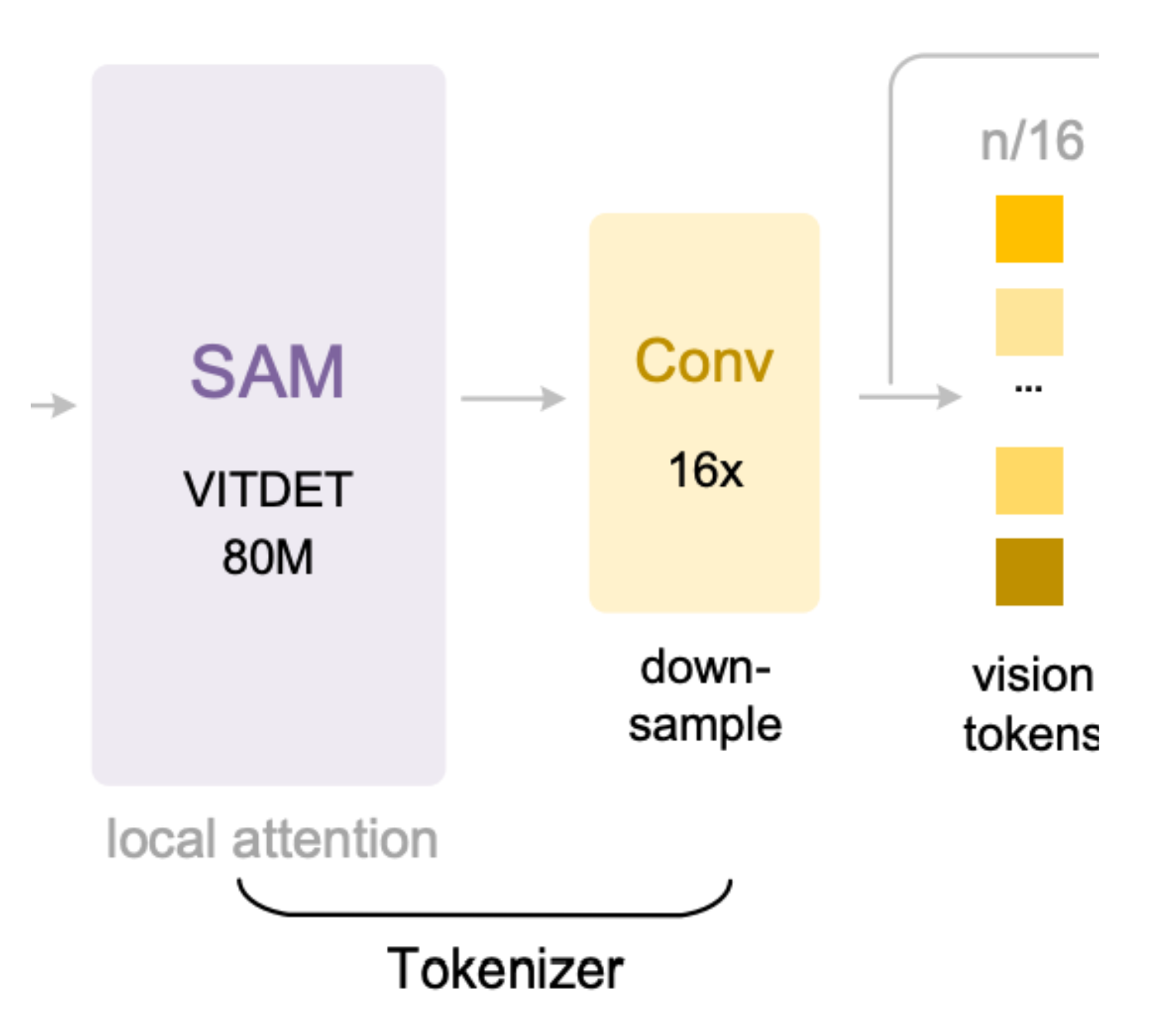
The Squeeze: If an image is split into 4,096 patches (64 X 64), this module uses a stride-2 convolution to reduce the spatial resolution by 4x, and then another 4x.
The Result: Total compression of 16x. It collapses the thousands of local detail tokens into just 256 dense Vision Tokens. This bridge is what allows DeepSeek-OCR to pass high-resolution information into the decoder without exceeding the context window. It essentially “summarizes” local visual patterns into a higher-level representational language.
III. The DeepSeek-3B-MoE Decoder: Expert Reconstruction
The final stage is a 3-billion-parameter Mixture-of-Experts (MoE) decoder. This is the “brain” that decompresses the vision tokens back into structured text.
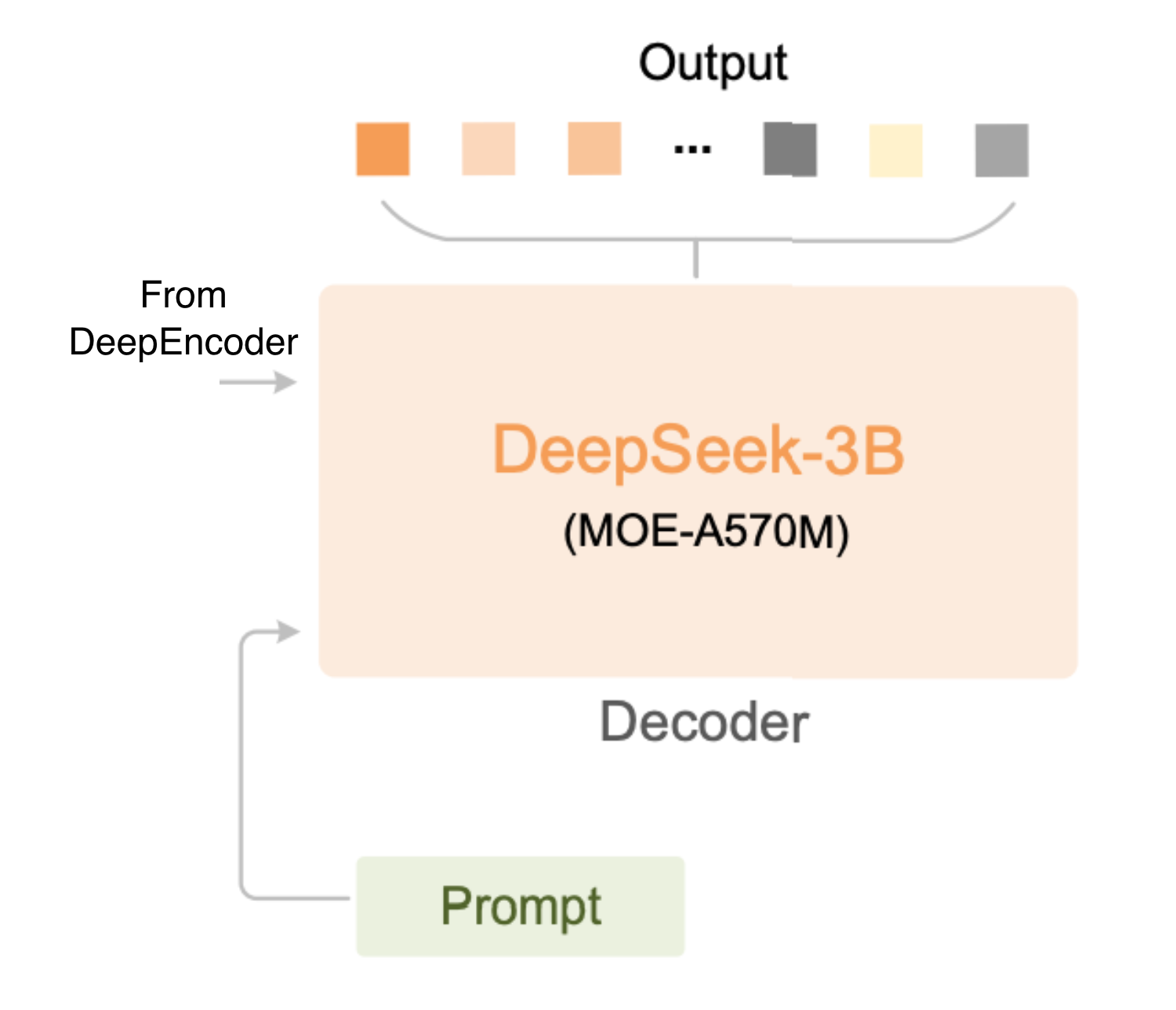
Sparse Activation: While the model has 3B parameters for broad “knowledge,” it only activates approximately 570M parameters per token.
Specialized Routing: The system utilizes 64 routed experts and 2 shared experts. An intelligent router directs vision tokens to specialized subnetworks:
Math Tokens → Experts trained on LaTeX/Equations.
Tabular Tokens → Experts trained on JSON/Markdown table structures.
Multilingual Tokens → Experts specializing in Chinese, Hindi, or Arabic scripts.
Where Z are the compressed latent vision tokens and X_hat is the reconstructed text representation. This confirms the core thesis: the latent Z is a more compact and efficient representation of the data than the final text X, proving that Visual Context is the superior primitive for large-scale document intelligence.
This architecture ensures that the “Understanding” phase isn’t just a general guessing game as it is a specialized reconstruction where the most relevant “experts” fire to translate the compressed visual signal into its final, parsed form.
7.6 The Two step Training Pipeline
To achieve this level of contextual compression, DeepSeek followed a disciplined, two-stage training strategy. The goal was to ensure the “Vision Tokenizer” (DeepEncoder) could master visual mapping before the “Language Brain” (MoE Decoder) attempted to reconstruct the semantics.
Stage 1: Independent DeepEncoder Training
In this “Cold Start” phase, the goal is to teach the DeepEncoder how to summarize an image without losing the character-level details.
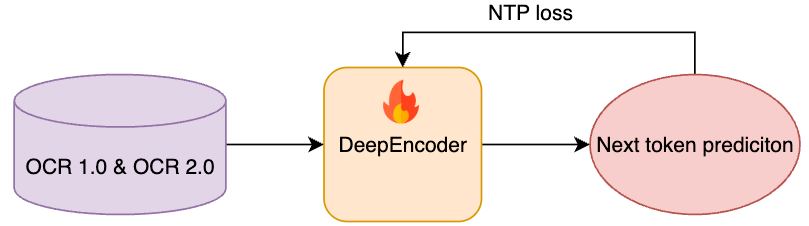
The encoder is trained using a Next-Token Prediction framework, where a small, “compact” language model acts as a temporary decoder.
Then The model is forced to map document images (x) to a latent space (z) such that the text can be perfectly predicted. This ensures that the 16x Convolutional Bridge learns to preserve “high-entropy” features like chemical bonds or tiny table borders while discarding the redundant white space.
This stage utilizes the full OCR 1.0 and 2.0 datasets plus 100 million general images from LAION to provide a strong visual baseline. It is trained for 2 epochs at a sequence length of 4096.
Stage 2: Full System Alignment (Training the DeepSeek-OCR)
Once the DeepEncoder is “frozen” (or nearly frozen), the focus shifts to the DeepSeek-3B-MoE decoder.
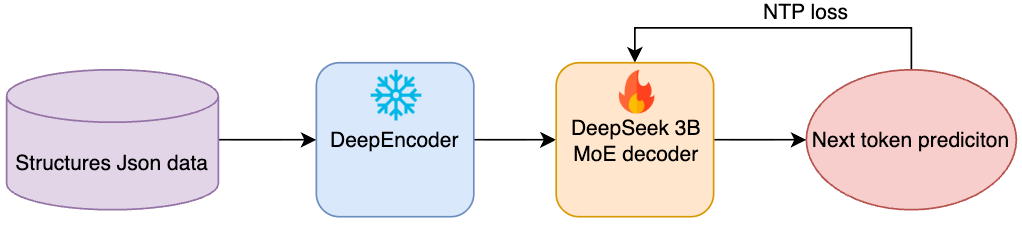
In this stage, the visual tokens from the pre-trained DeepEncoder are fed into the MoE decoder. The model is fine-tuned to align the visual context with structured language outputs (Markdown, LaTeX, HTML).
The training objective remains next-token prediction, but the complexity of the “target” increases. The model is now learning “Reading Order” and “Structural Inference.” It learns that a visual block on the left and right are columns, and should be interleaved according to human reading logic.
The MoE router is trained here to efficiently direct “Math-dense” visual tokens to the scientific experts and “Layout-dense” tokens to the structural experts.
Stage 3 (Bonus) : The Gundam-Master Continued Training
A final, specialized phase is used to create the Gundam-Master mode. This is obtained by taking the pre-trained DeepSeek-OCR and continuing its training on a curated sample of 6 million high-resolution documents. This stage focuses exclusively on the “Dynamic Tiling” logic by teaching the model how to perfectly stitch the global 1024px view with the n local 640px tiles.
7.7 Inference
Inference in DeepSeek-OCR is not a static process; it is a dynamic resource-allocation problem. Because the model treats resolution as a proxy for information entropy, it allows the user to select an inference “flavor” that matches the density of the document. This ensures that the model never wastes its “Token Budget” on simple images while providing a “Deep Zoom” capability for complex ones.
I. Available options
Depending on the target task, the model can be deployed in four native resolutions, each resulting in a specific number of vision tokens. This allows for a granular trade-off between Latency and Precision:

II. The Gundam Protocol: Ultra-High-Resolution Tiling
For documents that exceed the 1280 x 1280 threshold such as massive engineering blueprints, intricate financial tables, or newspaper broadsheets; DeepSeek-OCR activates its final form: Gundam Mode.
Gundam mode utilizes a Dynamic Tiling Strategy to prevent the “Signal Dilution” that occurs when a massive image is squashed into a small latent space. The process works as follows:
Local Tiling: The high-res image is split into n local tiles, each at a 640 x 640 resolution. Each tile captures fine-grained glyph details.
Global Pooling: Simultaneously, the entire image is downsampled into a single 1024 x 1024 Global Thumbnail.
Semantic Stitching: The vision tokens from all n local tiles are concatenated with the global tokens. This allows the MoE decoder to maintain Local Precision (reading the tiny numbers in a table cell) while utilizing Global Context (knowing which column and row that cell belongs to).
III. Throughput: The 200k Pages/Day Benchmark
The ultimate result of this inference architecture is a massive leap in hardware utilization. By collapsing the extraction-understanding-parsing pipeline into a single forward pass, the model achieves a throughput that was previously impossible for high-accuracy systems:
Performance: On a single NVIDIA A100 (40GB), DeepSeek-OCR can process over 200,000 pages per day.
The “Context Benefit”: Because the 16x Convolutional Bridge reduces the token count so aggressively, the decoder’s self-attention mechanism (which scales O(N^2)) stays in its “sweet spot.” This allows for long-form document parsing that remains computationally “cheap” even as the document complexity grows.
8. Results and Outcomes
The theoretical promise of “Contextual Optical Compression” is ultimately measured by its performance on the most demanding document parsing benchmarks. In the 2025/2026 landscape, OmniDocBench has emerged as the gold standard, testing models on everything from multi-column newspapers to dense financial reports.
8.1 Breaking the “Token-Accuracy” Paradox
Historically, high accuracy in OCR required high token counts. If you wanted to resolve a dense LaTeX formula, you had to feed the model thousands of tokens. DeepSeek-OCR breaks this linear relationship.
SOTA Performance: On OmniDocBench v1.5, DeepSeek-OCR 2 achieved a remarkable score of 91.09%. While specialized pipelines like Baidu’s PaddleOCR-VL (92.86%) still hold a slight edge in raw accuracy, they do so with significantly higher computational overhead.
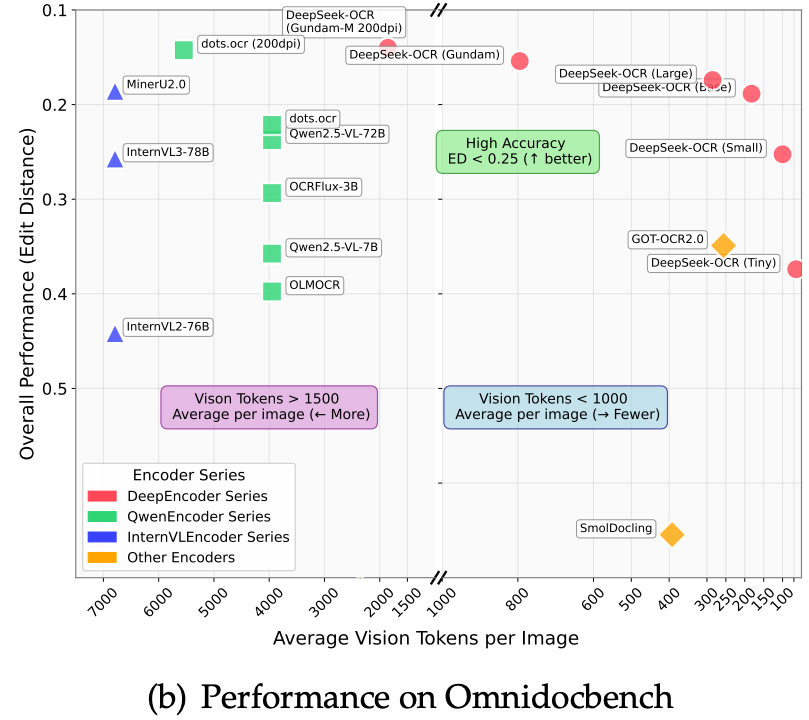
The Edit Distance Edge: When compared to “Massive” VLMs like Gemini-3 Pro, DeepSeek-OCR 2 demonstrated a lower Normalized Edit Distance (0.100 vs. 0.115). This means that despite its aggressive compression, the model makes fewer fundamental errors in the final text reconstruction.

The “Compression Cliff”: The paper defines a clear performance boundary.
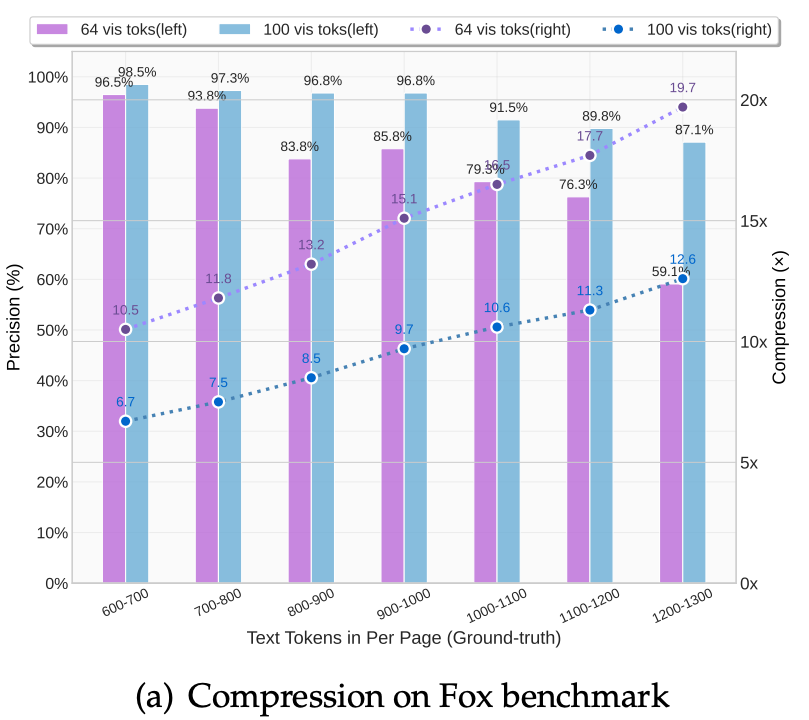
<10x Compression: Achieves near-lossless 97% precision.
10x–12x Compression: Maintains ~90% accuracy, suitable for most production tasks.
20x Compression: Accuracy drops to ~60%, proving that while 2D images are efficient, there is a physical “Shannon Limit” to how much text can be packed into a single latent vector.

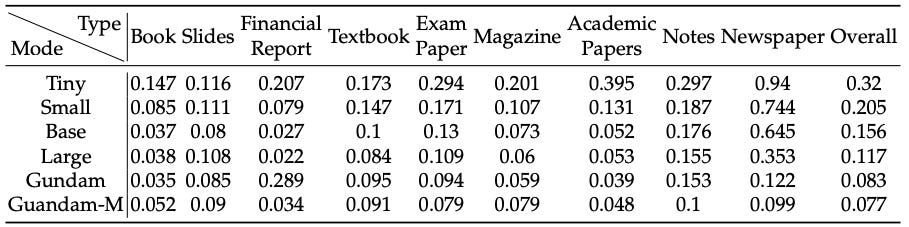
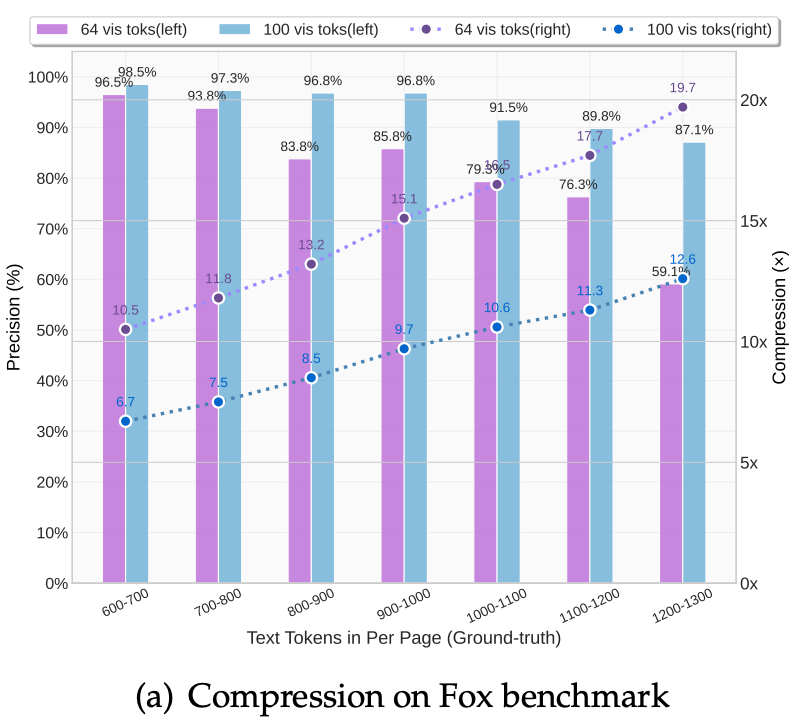
8.2 Benchmark Comparison
The most striking result is the comparison of Vision Tokens per Page. DeepSeek-OCR operates in a different league of efficiency compared to other SOTA models:

DeepSeek’s Gundam Mode manages to outperform MinerU 2.0 while using 8.5x fewer tokens. This is the practical validation of the “Intelligence via Symmetry” theory: by modeling the document’s structure, the model doesn’t need to “see” every pixel to know what the text says.
8.3 Production Impact
Beyond benchmarks, the model’s throughput in a production environment is its most “transformational” outcome.
The Single-GPU Benchmark: On a single NVIDIA A100-40GB, DeepSeek-OCR can process over 200,000 pages per day.
The Cost Revolution: For large-scale data rescue projects (digitizing million-page backlogs), this reduces the raw compute cost.
Data Synthesis: DeepSeek itself used this model to generate 33 million pages of high-quality training data for its larger LLM projects, proving that the model is its own best customer.
8.4 General VQA retention
DeepSeek-OCR maintains parity with standard VLMs in general visual tasks (description, detection, grounding) and preserves core linguistic reasoning via the inclusion of text-only corpora. However, as the pipeline lacks a dedicated Instruct/Chat SFT phase, the model functions as a base completion engine rather than a conversational agent; specific capabilities require precise completion-style prompting for activation.

Thoughts
The architecture itself (a ViT-based/inspired encoder) followed by a language decoder is quite standard. We’ve seen similar “Global + Local” perception stacks in image captioning and general scene-understanding models for years. DeepSeek-OCR isn’t reinventing the neural block; it’s repurposing a mature design.
The shift is purely in the application. Previously, this level of visual compression was reserved for “fuzzy” semantic summaries (e.g., describing a photo). For structured text, the industry default was high-resolution, patch-by-patch extraction to avoid losing character-level detail.
DeepSeek-OCR proves that Structured data is compressible as Document layouts and text follow patterns (symmetries) can be modeled as a continuous latent signal rather than just transcribed.
Instead of a single bottleneck, a multi-scale/pyramid approach like extracting large, medium, and small patch tokens simultaneously would allow the model to capture global layout and micro-text details in parallel. Currently, the "Gundam" tiling is a manual workaround for a limitation that a native multi-resolution pyramid could solve at the feature-map level.
Future iterations should leverage Group Relative Policy Optimization (GRPO) or similar RL-based frameworks. By using a reward function that penalizes structural inconsistency (e.g., Markdown table alignment) or hallucinated glyphs, the model could move from "guessing the next token" to "verifying the document logic."
 - GeeksforGeeks")
Conclusion
At its core, DeepSeek-OCR reframes document intelligence as a problem of contextual optical compression rather than literal transcription. By abandoning the “Token Tax” of traditional string-based pipelines and treating the document as a high-dimensional visual manifold, we gain the ability to process dense structural data with an efficiency that was previously considered the “Shannon Limit” of the field.
In this article, we began by tracing the lineage of OCR, moving from the fractured, multi-stage pipelines of the past to the unified Vision-Language Model (VLM) paradigm. We identified the “Representational Gap” as the critical inefficiency where models would waste massive context windows on redundant pixels. We explored the methodology of Visual Tokens as Semantic Proxies, using the lens of cross-entropy to see how a document’s feature space can be mapped directly from pixels to latents. We dissected the architecture, highlighting the DeepEncoder’s dual-stream perception and the 16x Convolutional Bridge that “zips” 4,096 patches into just 256 dense tokens. We then looked at the Gundam Protocol, a dynamic tiling strategy that enables the model to resolve ultra-high-res layouts without signal dilution. Finally, we critiqued the current bottlenecks, discussing the potential for Hierarchical Pyramid Networks and the transition toward RL-based (GRPO) training to enforce topological consistency.
The key takeaway is that DeepSeek-OCR is not just a faster OCR engine; it is a fundamental shift in representation assumptions. It proves that when we treat the visual modality as the primary compression primitive, we don’t just get faster parsing; we get a model that understands the structural logic of the page.
Reference
DeepSeek OCR : https://arxiv.org/pdf/2510.18234
That's all for today.
If you liked the article make sure to like and share this article with your network. Follow me on LinkedIn and Substack for more such posts and recommendations, till then happy Learning. Bye👋