
Large Language Diffusion Models (LDMs vs ARMs)⏭️ vs 🤖
Behold LLADA (aka Large Language Diffusion with mAsking) a diffusion model for Text with an unprecedented 8B scale, trained entirely from scratch, rivaling ARMs (Auto-regressive models) like LLaMA3 8B


Table of contents
Introduction
Why are AR models problematic?
How to solve the uni-directionality challenge?
Challenges/issues with Diffusion based modelling
Methodology
Training module
Pre-training
SFT (Supervised Fine-Tuning)
Inference module
Outcome/Results
Thoughts
Conclusion
Introduction
Large language models had been the hallmark of seemingly intelligent systems that are being currently built. Apart from beating and saturating multiple benchmarks, they actually came out to be reasonably usable across multiple tasks and use-cases. This ease of use, be it through apis (as in openAI, gemini) or open-weights (like llama, deepseek, mistral), created enough buzz and traction for everyone.
But, current day models are trained in an auto-regressive fashion, which simply means each token is generated in a sequence one after the another, very similar to how we write or read (left to right), which is different from how we perceive things/think about objects/concepts. Let's see what problems do current ARM based architecture present.

Why are AR models problematic?
Speed/latency : Being AR (Auto-regressive) in nature, they struggle with time, as any next token is a function of previous ones, hence, under any circumstances, the generation process cannot be parallelized and eventually needs k number of iterations for generating k tokens, which is slow and wasteful.
Compute : Given the previous point, it should be clear that running model once vs K times creates a huge compute bottleneck, as in cases for long attention (as the prominent architectures are still attention driven), then key-value pairs in itself lead to huge compute requirements.
Cost : Running the high capacity resource for longer period of time (which is increasing now, with COTs and think tokens), eventually presents higher maintenance and inference cost (for APIs and open-weights both), which has to be incurred by the user.
Architectural biasness : This in my understanding is the most significant issue, the current AR models suffer from lack of reversal reasoning as they perform look-back generation as they are uni-directional (similar to early version of uni-directional LSTMs). Hence, any task where reverse context is required (example writing poem backwards or answering some reasoning questions), even the larger SOTA models like GPT4-o, gemini suffer heavily. Hence, if we want a transcend to a truly reasoning capable system, bidirectional understanding is very important.
Less-like humans : As discussed in BLT article, mimicking human thought is final frontier for all the efforts going in this direction. Seemingly, we don't think auto-regressively, we don't think word by word, we mostly think at concept level (which typically is a burst of keywords) followed up by subsequent fillers. Hence, AR models are trying to mimic how we write or read, not how we think.

First-order and Second-order markov models, the basis assumption behind sequence modelling tasks

Given that we understood the problem is because of the nature of architecture choice itself (uni-directional/ auto-regressive), let's see what we can do to make it better.
How to solve the uni-directionality challenge?
Even beyond the architectural issue itself, it's more about objective, in conventional LLMs we generate token by token, why not generate whole sequence at a time and then selectively clean it? or maybe do the same with parts of sequences?
This is the core idea behind the paper large language diffusion model and at the very core lies the concept of diffusion models.

Diffusion model are yet another class of generative architecture like VAEs, GANs, etc. Though they follow seemingly similar order of operations while making predictions (during iterative noise removal) are actually different from the ARMs.
They attend to whole information space at every point of time, unlike ARMs which are only dependent on previous set of tokens. This makes it ideal for constant space generations like images/frames.
You can think of diffusion like finding path going from A and B while exploring the surrounding space (basically by removing extra choices out on N choices), whereas ARMs are probabilistic walk without actual exploration where the shape of space is not taken into consideration as the next step in only function of last state (basically by performing selection out of N choices). Hence, the difference lies in the way we explore space (rejection vs selection).

A typical diffusion process, red/orange region high energy (bad samples/noise), the blue regions are low energy regions (data samples)

Now, we understand the basic difference let's clarify the advantages of diffusion models over ARMs
Number of iterations : In ARMs the number of tokens is equal to the number of iterations whereas in LDM (latent diffusion models) it is equal to the number of steps (which is much smaller/independent of number of tokens).
Compute efficiency : Both LDMs and ARMs are typically slower by choice, but, given that they have different number of iterations, allows LDMs to have better compute efficiency (because the number of iterations is not proportional to number of tokens to be generated and hence not either proportional to compute), though there are nuances with quantity of tokens predicted for each iteration (we will cover this next) on compute.
Now that we have clear idea over difference and advantage of LDMs over ARMs, the next question arises is then why diffusion family of models were not used for language modelling until now? Lets discuss this in next section.
Challenges/issues with Diffusion based modelling
Discrete space : The diffusion models are typically used for modalities where space is continuous/could be continuously represented like images/videos, because there the formulation of noise sampling and addition could be modeled properly. Whereas in text the space is discrete by nature, which means there doesn't exist a continuous relation which could be modeled as a smooth interpolation, hence, definition of noise in itself becomes very challenging.
Variable space shape/size : Diffusion models make assumption over the shape of space itself which is supposed to be fixed (as in images in terms of resolution, or in videos in terms of frame resolution and timestamps), which seemingly is not a good enough idea for text as it intends to have variable length depending on prompt/query (could be anything from 1 token to 1000s of tokens).
This fixed length state problem prevalent with older discriminative and even generative systems was very well tackled by ARMs like sequence2sequence models, hence, if we want to use diffusion based systems we have to again fixate the maximum sequence length (until some sort of variable length sequence in diffusion happens).
Now that we know issues with using diffusion for text, the next eventual question that arises is can we somehow tackle this? The methodology for solving the same problem is discussed in the paper and hence discussed below.
Methodology
One of the most important component of any diffusion model is the sampler, which as we discussed above is typically continuous due to continuity in states (as in images), for handling discrete states, authors proposed usage of a masking technique (which in itself is discrete noise, either off or on / active or inactive) very similar to mask language modelling (MLM) which serves as the SSL optimization (helping model to build understanding of data and it's corresponding correlation mostly based on occurrence and similarity without an externally applied optimization) behind BERT and other encoder family of language models. As evident the masking in itself serve as noise addition, as a completely masked out sequence is like pure noise (X_t) whereas complete sequence in pure signal (X_0). That understood, let's understand the training and inference modules.
Training module
The training module is divided into two phases, i.e. pre-training and SFT (fine-tuning/instruction alignment), both of which are conventional paradigms during training.
Pre-Training
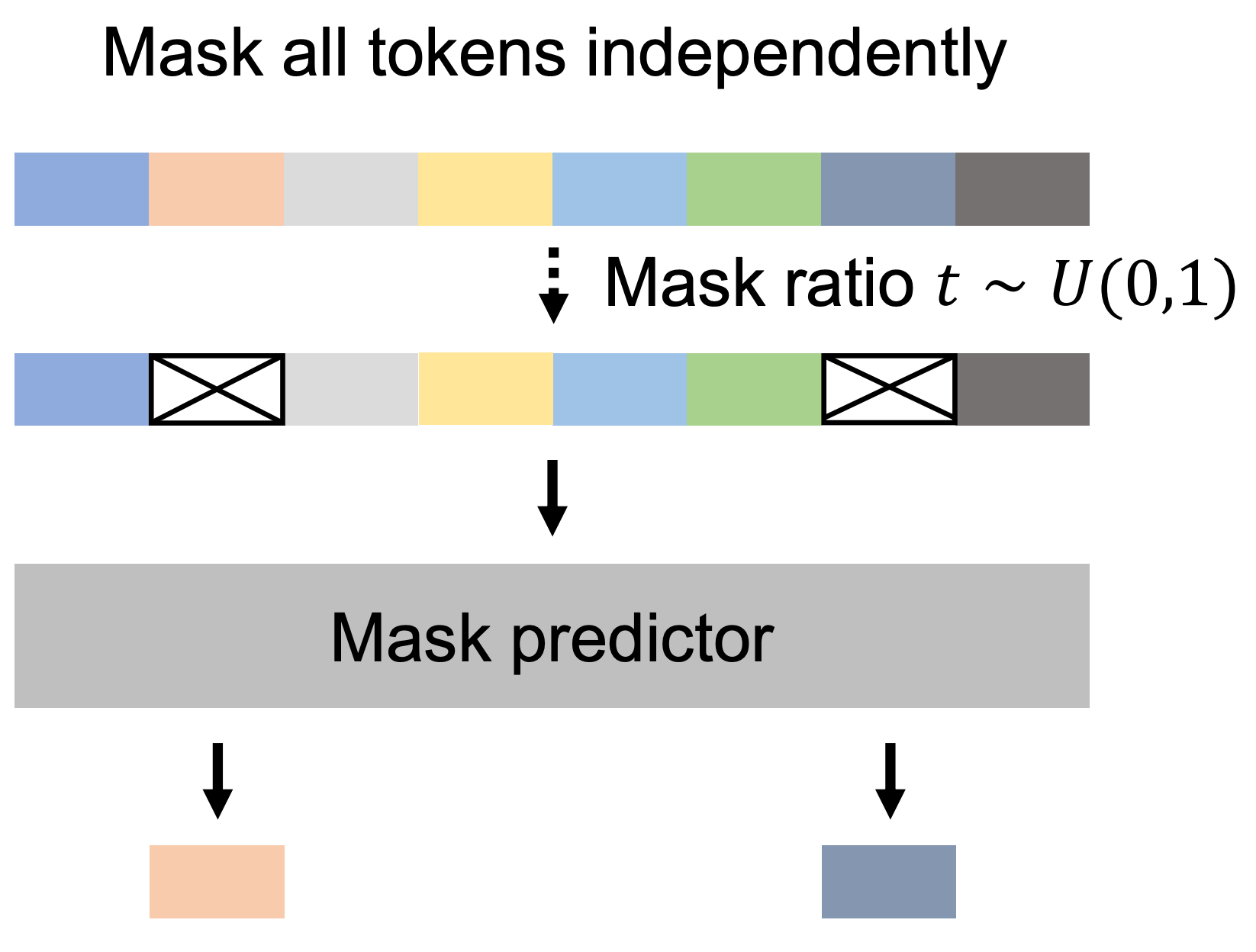
This step is simple MLM (hence no annotated/labelled data) as I pointed out above, the starting sequence is composed of masked and visible tokens, which is then passed to the mask predictor (model) for unmaksing/denoising.
The number of tokens to mask is chosen through mask ratio, which is done in a way to give lower probability of masking to important tokens/keywords and higher masking probability to less important words (fillers, stopwords, etc.)
The prediction/denoising process is repeated multiple times until all the masking are denoised to form clean text/signal (similar to denoising in diffusion models). The base objective function is cross-entropy for predicted/denoised vs target alignment (which inherently is sort of MSE itself, hence again similar to plain diffusion).
The model eventually learns to think at concept level, which is roughly defined by keywords and then the surrounding information is filled. It's like making the sketch/outline and then filling in colors or extra details.
As evident from the steps above there is no causal dependency over the text. Also LLaDA is incompatible with KV caching, resulting in a different number of key and value heads. Consequently, the attention layer has more parameters, and we reduce the FFN dimension to maintain a comparable model size. Additionally, the vocabulary size differs slightly due to different tokenizer.
This phase utilized around 2.3T tokens and the pre-training process utilizes a fixed sequence length of 4096 tokens.
Example, let's say you have 5 words, after first iteration 1st, 3rd and 5th words got predicted (which could be some keywords), in the next iteration the remaining 2nd and 4th were predicted (which are possibly stopwords/fillers).
Supervised Fine-tuning
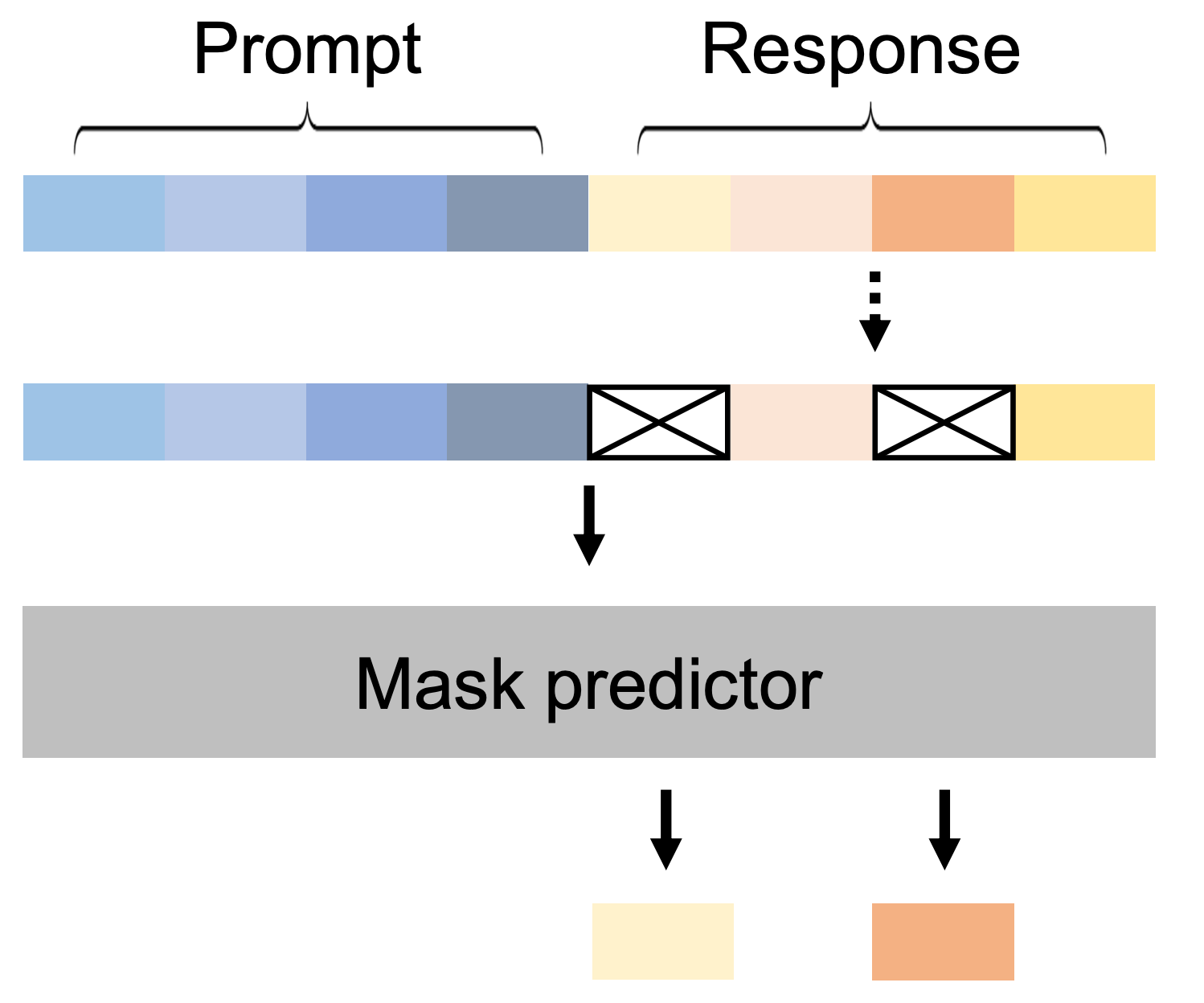
This phase is mostly for instruction alignment/tuning wrt tasks/prompts.
Here, the process for denoising remains same apart from what we mask. In previous step we masked each token independent of whether they were part of prompt or output. In SFT step only the expected output tokens (R) are masked and prompt (P) is left as it is.
They treat
<EOS>as a normal token during training and remove it during sampling, enabling LLaDA to control the response length automatically. This<EOS>token is also appended at end of short sequences to make the data uniform (as fixed length is compulsory for this architecture).Given that they only mask the response side (R), they used variable masking ratio.
The LLaDA 8B model undergoes SFT on a dataset comprising 4.5 million pairs. Also the dataset spans multiple domains, including code, mathematics, instruction-following, and structured data understanding.
Inference module
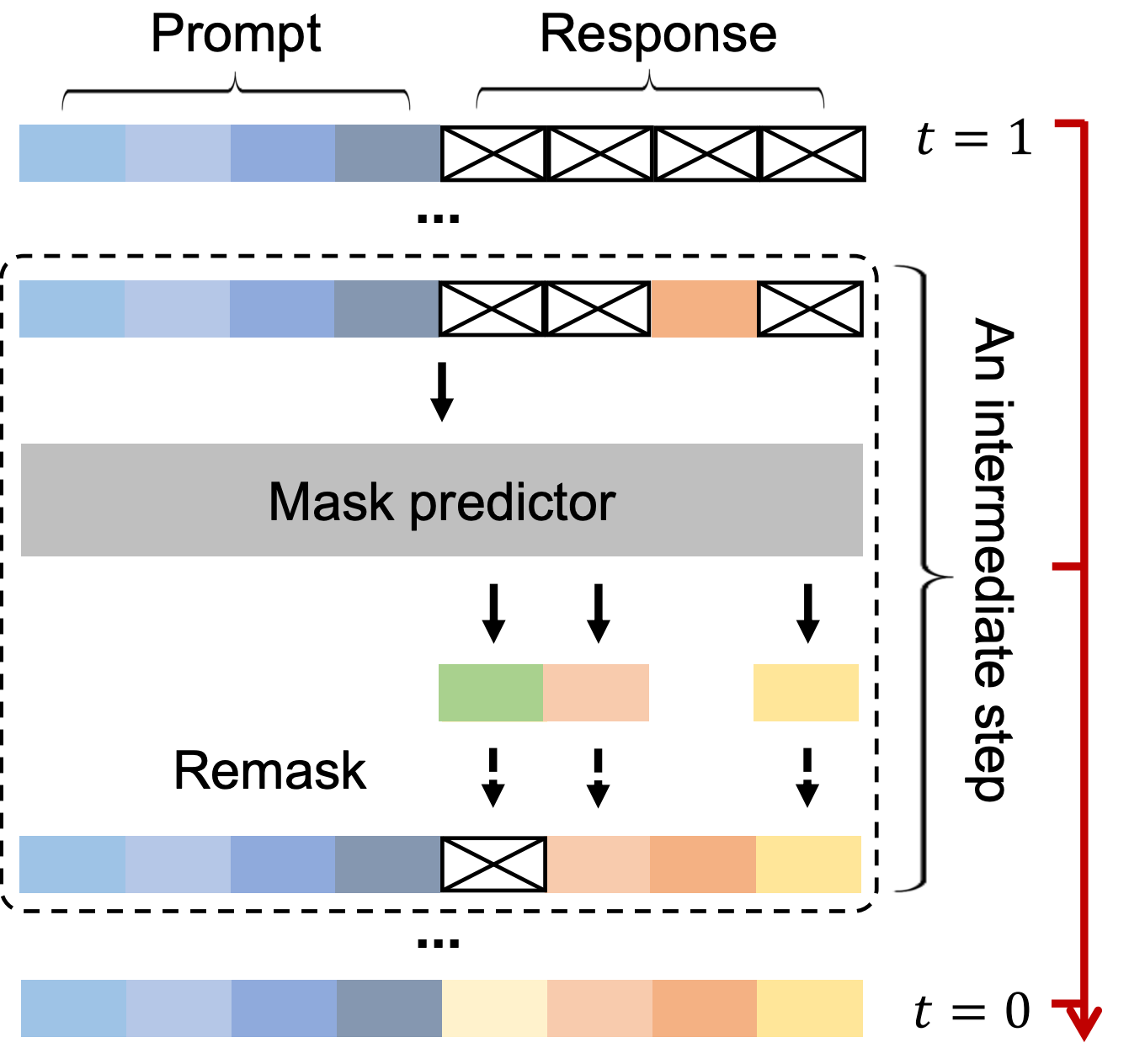
Unlike current trend of RL based optimization of LLMs, authors followed a simpler path of the 2 step training (pre-training and SFT) which we discussed above. Now, let's look at the working of the model during inference step.
The instructions/prompt and N number of mask tokens are concatenated together (presumably N=4096), which is then passed to model for reverse diffusion/denoising.
The model predicts all the mask tokens, which is then remasked and re-run through the model. Why? Remember more the diffusion steps, more is denoising, hence higher quality outputs.
The number of steps is an hyper-parameter here, which controls quality vs time/compute.
To choose which tokens to remask the authors proposed two methods
Confidence based remasking
As the name suggests the set of tokens with lowest confidence are chosen and are replaced with <mask> tokens again which is then sent for denoising. The process is repeated until either we have all tokens with high confidence or most of the tokens become <EOS> (or max number of iterations is reached)Semi-autoregressive remasking
This is quite interesting approach, as here the authors basically merged the ARMs and LDMs together. I found the method to have a strong correlation with LCMs. Simply put, the entire sequence is divided into chunks which are predicted left to right (as in ARMs), the prediction for each chunk is done through diffusion model (as done above) independently, hence, chunk size becomes a really important hyperparameter which controls local vs global information share as well as compute.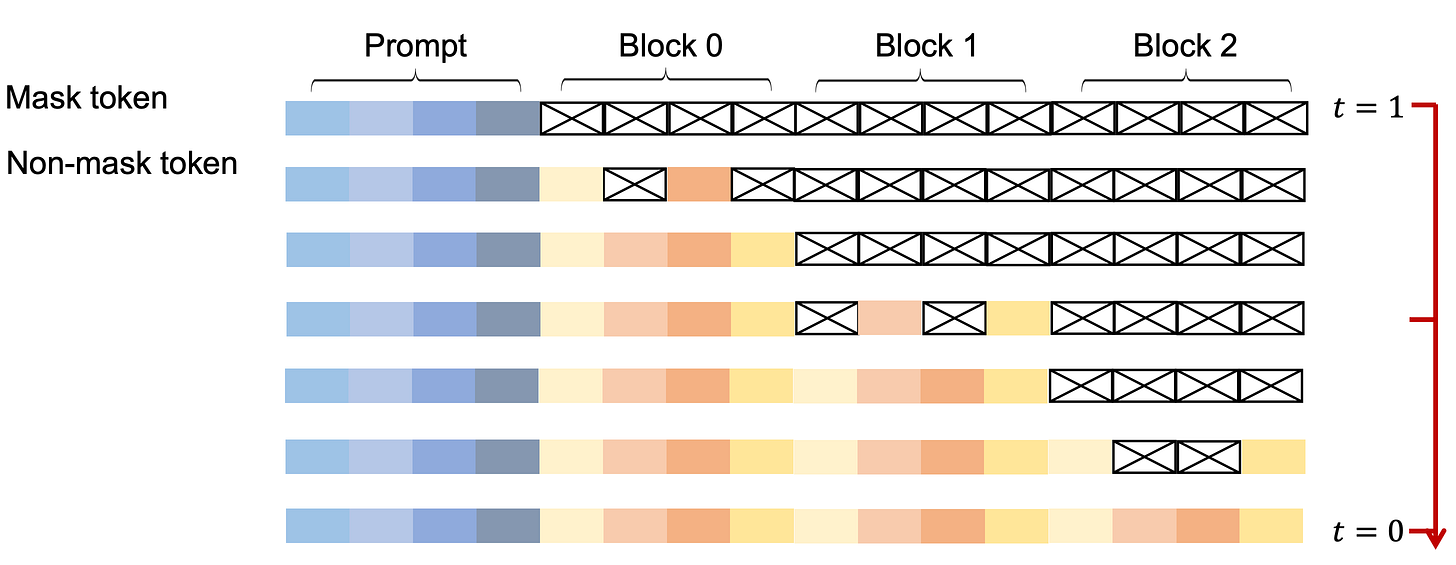
A Conceptual Overview of the Semi-autoregressive Sampling
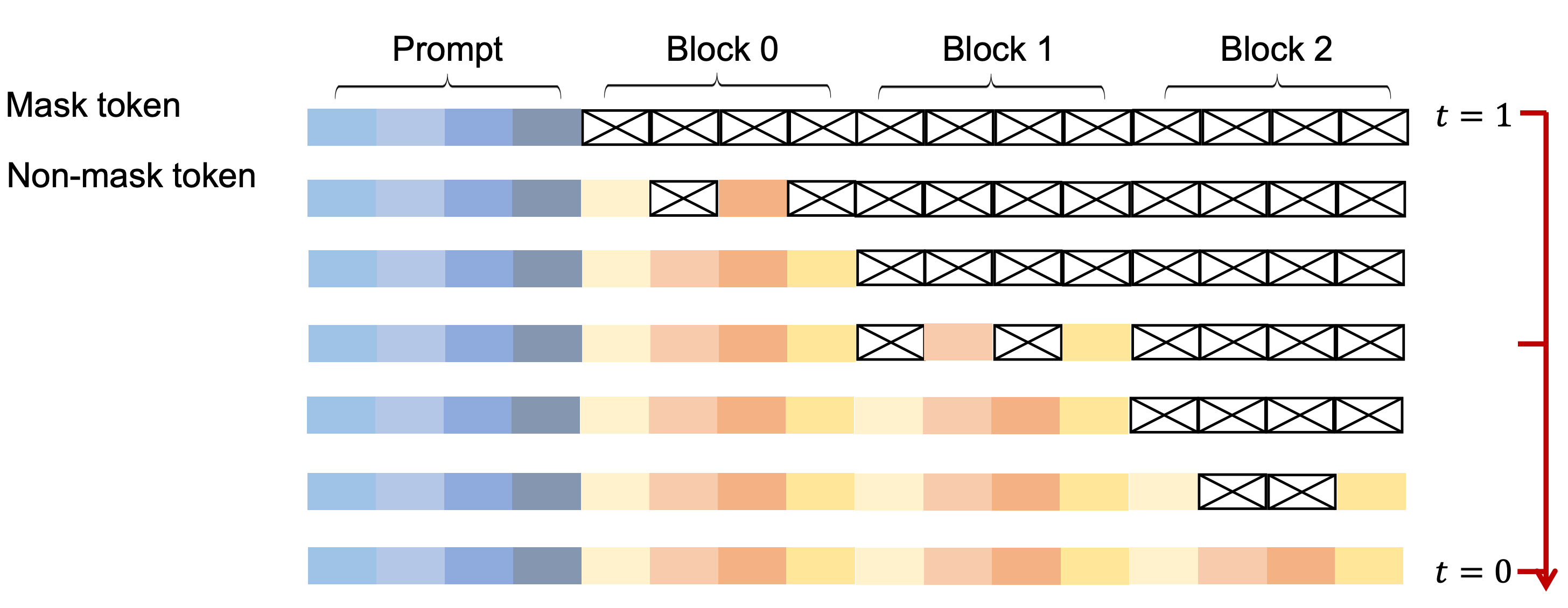
Now, we understand both the training as well as Inference module as mentioned in the paper, I would still encourage you to go through the paper for understanding more nuances like hyper-parameters and compute requirements.
Outcome/Results
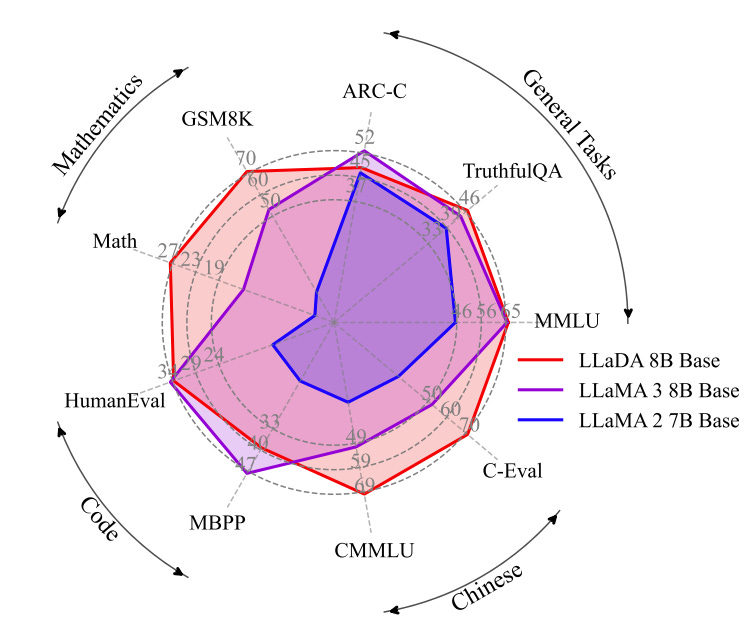
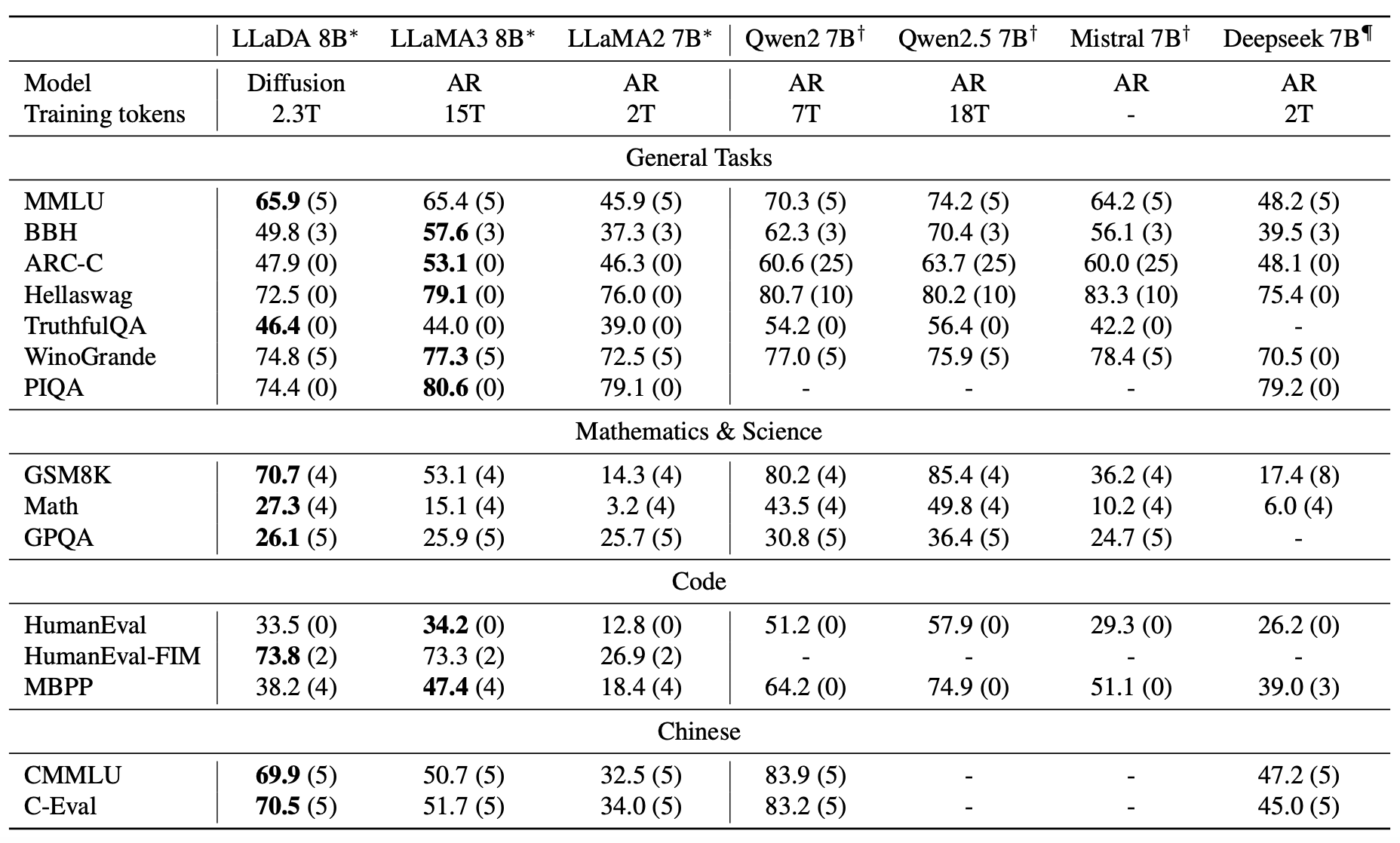
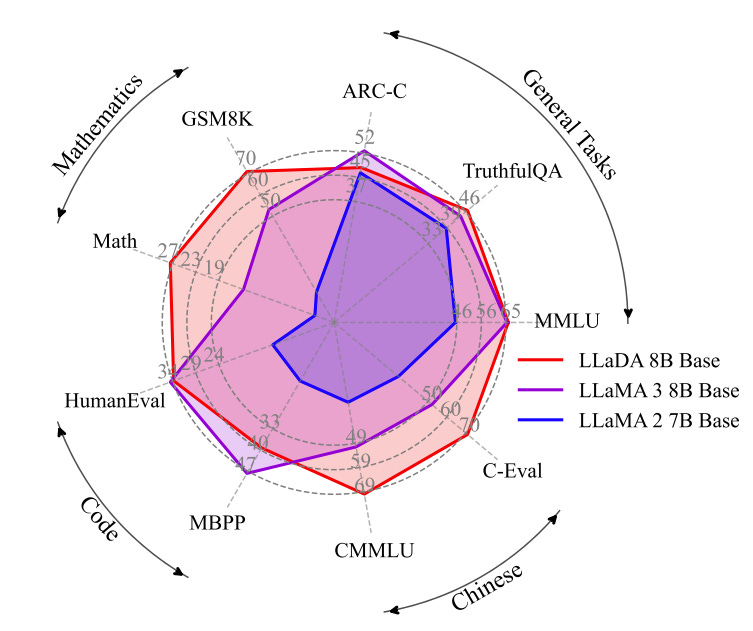
Llada-8B beats llama2 on multiple benchmarks, and plays on par against Llama3. For understanding the below mentioned benchmarks, visit here.
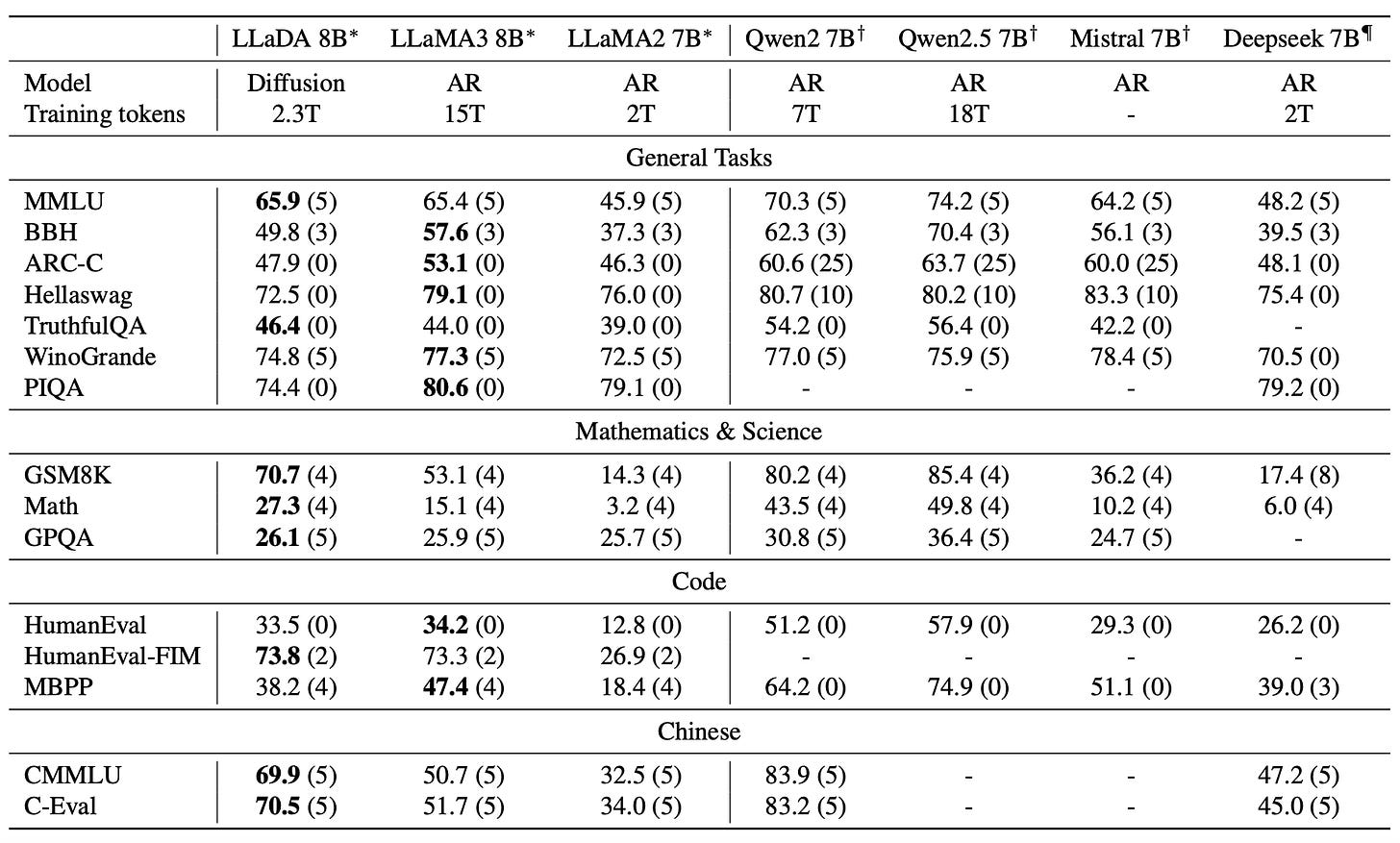
MDM (Maksed Diffusion Model) architecture in experiments showed up requiring less flops to reach their optima (which was lower than best possible optima by ARMs)
Inspite of using much fewer tokens llada shows almost same performance as larger models like llama3 (and let's not forget this is without any RL based optimization).
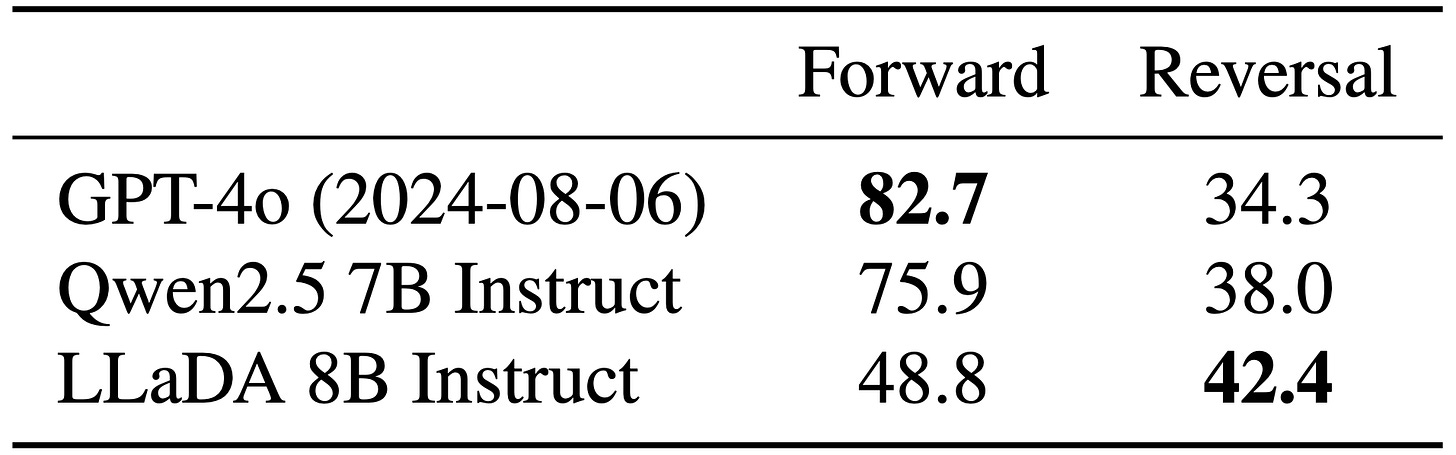
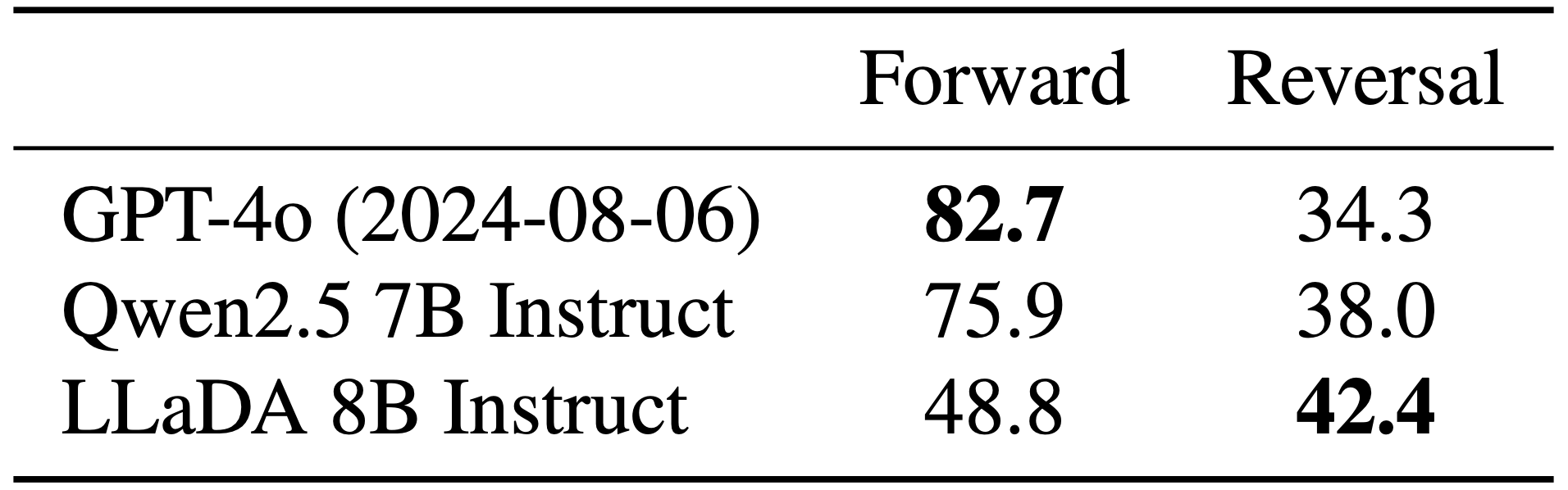
Beats much larger counterparts like GPT4-o in "reversal poem completion" benchmark.
Thoughts
A different way to look and tackle the problem of language modelling itself, hence inclining more towards human-thoughts like prediction.

darker colours indicate tokens predicted in the later stages of sampling, while lighter colours correspond to earlier predictions. This makes conventional prompt engineering methods obsolete which rely on assumption of left-to-right/writing like generation. Imagine sampling 100 masks, replacing mask in middle (unlike prompt at beginning in conventional setup) with some random statements and then denoising it to get full blown story. Hence, you could selectively bias parts of sequence to behave in a certain way by inducing explicit positional information (hence, it might be easier to poison the prompt and perform attacks over model, but, the distributed nature of generated tokens also gives multiple defence points; this would be interesting to watch unfold in near future).
LLADAs dependency on sequence length is curse as well as blessing, because now we can explicitly keep less mask tokens for tasks with relatively smaller output space. Hence, giving us felixibility in saving space/compute and time.
It would be really interesting to tune the same architecture with RL based optimization like PPO, GRPO, etc. and then compare across other use-cases and large models.
It would be interesting to see formulation of the language modelling task as other types of diffusion process like SDEs (Stochastic differential equations) or score function based diffusion systems (though discrete representation would be more challenging) or even flow based models like LCMs, flow matching, etc.

Conclusion
LLADA provides an interesting approach towards language modelling or I would say any discrete modelling task, not only it is simple but also really efficient and flexible (thanks to some useful yet controllable hyperparameters).
That said, let's have a quick overview of the article, we started with brief introduction over current state of LLMs and challenges with ARMs, then we hovered over to Diffusion models as potential solution where we understood advantages and shortcomings of these models, then we formulated method to effectively use denoising but discretely (as discussed in paper), thereafter we dived into the paper understand training and Inference module in detail. Finally we ended up with some result followed by some of my personal thoughts.
With this we come to the end of the article, I hope you found it interesting and insightful.
Please go through the paper for further nuances and details,
📝Paper : https://arxiv.org/abs/2502.09992
That's all for today.
Follow me on LinkedIn and SubStack for more insightful posts, till then happy Learning. Bye👋