
Multi-modal representation learning : A deepdive and comparison of CLIP, SIGLIP and BLIP architectures
This article discusses in detail about refined parametric methods like CLIP, BLIP and SIGLIP, which help us in designing of a architecture capable of multi-modal understanding and representation.

Table of content
Why Representations Are Important?
Why Multi-Modal Representation Learning is the Holy Grail of Intelligence?
Some Previous Work and How Multi-Modal Representations Were Learnt in Older Times
Generalized Objective for Multi-Modal Representation Learning
Key Alignment strategies
Fusion Strategies
CLIP: Contrastive Language-Image Pretraining
Why CLIP Works: Learning Alignment through Agreement
Deepdive in the math
Key Intuition: Learning with No Explicit Supervision
But, where CLIP falls short?
SigLIP: Sigmoid Loss for Language–Image Pretraining
What’s Different in SigLIP?
Benefits and Tradeoffs of Sigmoid-Based Loss
BLIP: Bootstrapping Language–Image Pretraining
Multi-Objective Training Strategy
The BLIP Training Pipeline
Limitations
BLIP-2 (difference over BLIP)
Downstream Applications of Multi-Modal Representations
Thoughts
Conclusion
1. Why Representations Are Important?
Continuing from our previous article on Self-supervised Learning, where we saw Representation learning sits at the heart of every intelligent system. Whether it's a model classifying an image, translating text, or answering a multi-modal query; what it fundamentally does is: map raw, messy input into a space where similar things are grouped together and dissimilar ones are pushed apart. This space is what we call the representation or embedding space.
But what makes a good representation?
A high-quality representation compresses the signal while preserving its semantics. It untangles complex relationships in the input, giving downstream models an easier job. Consider how a neural network might embed a sentence like "a man playing a guitar" and an image depicting that exact scene. Ideally, their embeddings should lie close to each other, reflecting their shared semantics, even though the modalities are different.
This becomes especially tricky when we rely on supervised learning. Labels offer coarse-grained signals. They're sparse, noisy, and often reflect human bias. More crucially, they only teach the model what to focus on at the final layer. Earlier layers which are ones responsible for learning general-purpose features are left unguided. This leads to issues like:
Layer selection: Which intermediate layer actually holds the most informative representation? Should we use the penultimate layer or one buried deep in the middle?
Label bottlenecks: Most real-world datasets lack clean annotations. This fundamentally limits representation quality and generalization.
This is where Self-Supervised Learning (SSL) enters; it is a paradigm shift where data supervises itself.
In our previous article on SSL which you can find here :

We explored how powerful representations can be learned without manual labels by leveraging pretext tasks from solving image jigsaws to matching augmentations. We classified SSL methods into three broad philosophies:
Contrastive Learning (e.g., MoCo, SimCLR): where the goal is to pull together augmentations of the same image and push apart others.
Clustering-based Learning (e.g., DeepCluster, SwAV): which group similar data samples via learned prototypes.
Distillation and Redundancy Reduction (e.g., BYOL, Barlow Twins): where a student mimics a slowly updating teacher without requiring negatives, sometimes encouraging decorrelation between features.
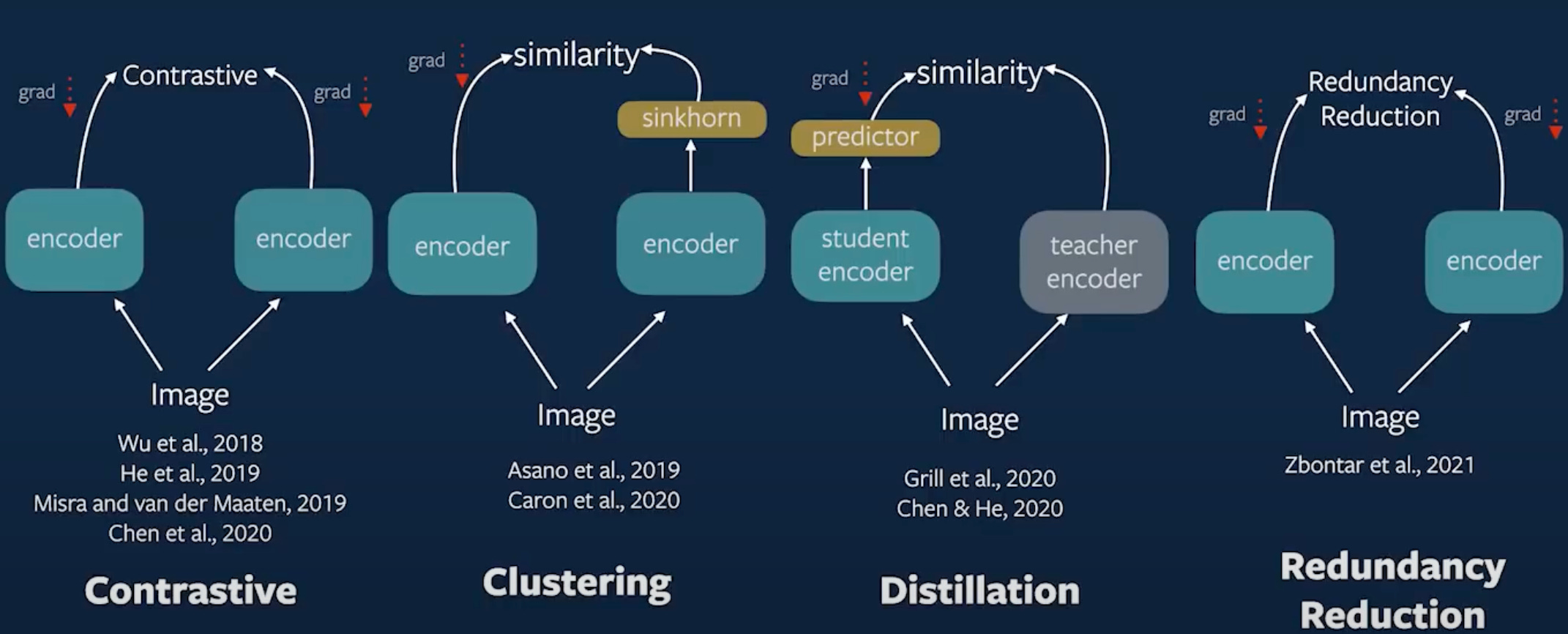
Each of these methods attempts to learn a compact, semantically aligned feature space. But, while they work well within a single modality (like vision or text), the real world doesn’t come packaged in neat silos. We perceive and reason across modalities all the time like text, images, sound, motion.
This brings us to the next natural question: what makes multi-modal representation learning so special?
2. Why Multi-Modal Representation Learning is the Holy Grail of Intelligence?
At the core of human cognition lies a simple but profound ability to unify sensory inputs into coherent thought. We see a red apple, feel its roundness, recall its taste, and read the word “apple”; all seemingly distinct signals, yet represented cohesively in our minds. This is multi-modal grounding. And learning such shared representations across different input modalities is arguably one of the most vital steps toward artificial general intelligence.

In technical terms, the goal of multi-modal representation learning is to discover mappings from different data types, say, images and texts into a shared latent space. In this space, semantically similar inputs, regardless of modality, lie close to each other. Think of it as a universal language that allows cross-modal understanding, like projecting an image of a “golden retriever” and the caption “a playful dog” to neighboring points on the manifold.
In ideal case, Imagine we have a collection of functions {φ₁, φ₂, ..., φₘ}, each transforming inputs from a specific modality into a common representation space 𝓩. The power lies not just in these functions independently, but in their alignment; φ₁(x_image) ≈ φ₂(x_text), if both x_image and x_text refer to the same concept.
Such a space unlocks a world of possibilities:
Zero-shot learning: You can describe unseen classes in natural language and retrieve matching images without retraining.
Cross-modal retrieval: Retrieve images with text, or videos with audio clips.
Multi-modal reasoning: Combine signals across modalities to perform inference like answering questions about a diagram or summarizing a movie scene.
But why is this representation so powerful?
Because it isn’t tied to any single output task. Instead, it abstracts meaning itself.
And while single-modal SSL methods (like contrastive image learning) taught us how to learn useful features from data alone, multi-modal SSL introduces an additional, and far richer, form of supervision through cross-modal alignment.
But this vision hasn’t always been the norm. Earlier systems struggled to bridge the modality gap. So before diving into modern breakthroughs like CLIP, SigLIP, and BLIP, let’s take a quick tour through some traditional approaches and how they attempted multi-modal learning (each with their own merits and limitations).
3. Some Previous Work and How Multi-Modal Representations Were Learnt in Older Times
Before today’s sleek architectures like CLIP or BLIP took over, the space of multi-modal learning was already bustling with ideas; some pragmatic, others aspirational. What most of them tried to solve was this: how can we align knowledge from different modalities so that one informs the other?
Generalized Objective for Multi-Modal Representation Learning
At its core, multi-modal representation learning can be framed as learning functions:
Where:
Xv: visual modality (e.g., image space)
Xt: text modality (e.g., sentence space)
fθ and gϕ: encoders parameterized by θ and ϕ, mapping their inputs to a shared ddd-dimensional embedding space.
The overall goal is to bring matched pairs closer and unmatched ones apart, typically using some objective:
This formulation allows room for contrastive loss, distillation, generative objectives, or any mix of them.
Key Alignment strategies
Let’s break down the key strategies of approaches and how to think about them in terms of alignment strategy and representation goal.
1. Frozen Backbone with Adapters
One early strategy was to pretrain a model on one modality, freeze its weights, and then train an adapter or projection from another modality onto this space. For example, you’d have a frozen vision backbone trained on ImageNet, and learn to project captions or text onto that same space.
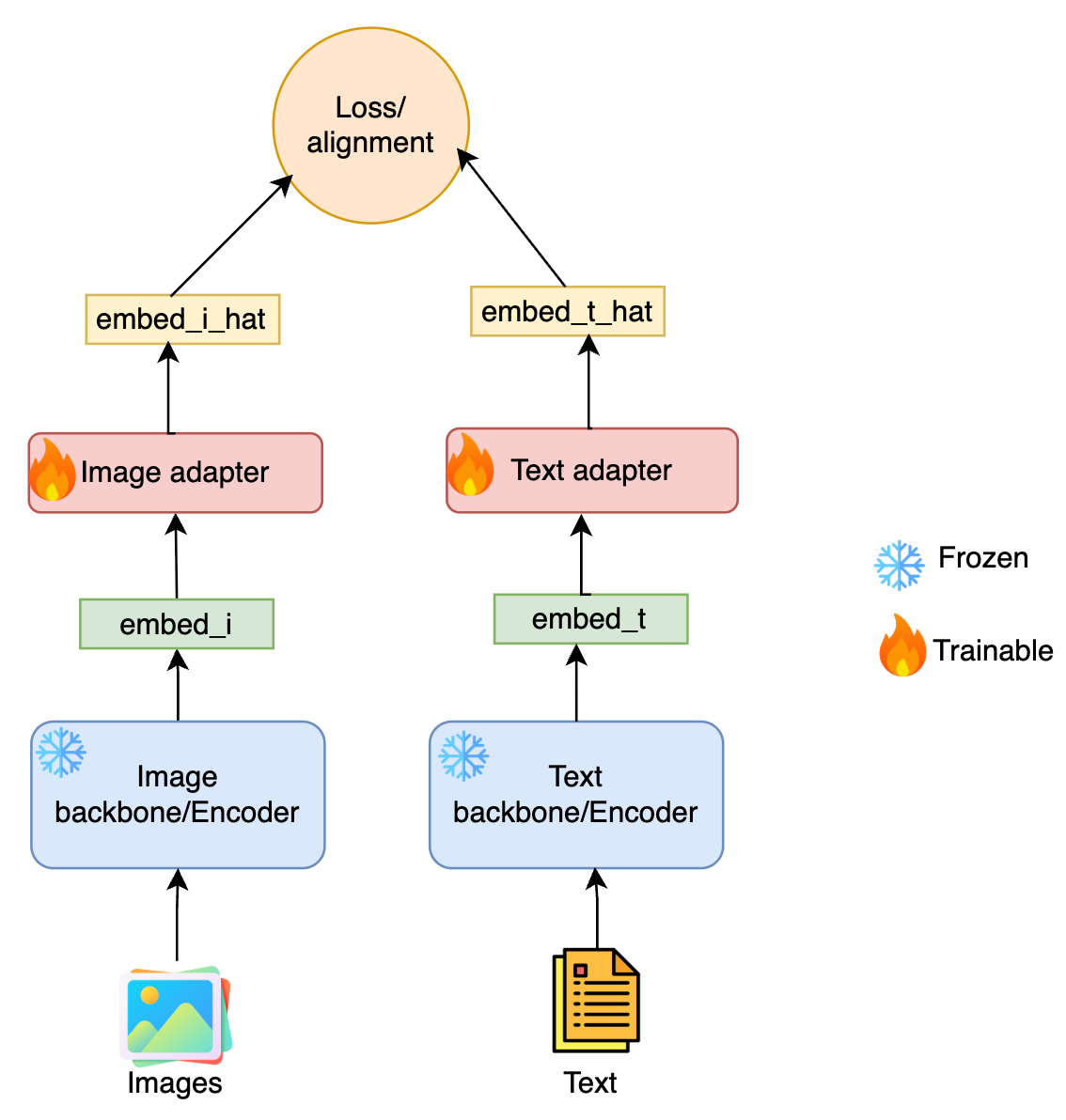
This approach was relatively simple to implement, and made use of powerful pretrained vision or language models. But it had a clear downside; i.e. feature-set imbalance where one modality dominates the latent space as it has more information to represent. Text becomes a second-class citizen if you're aligning it to image space (or vice versa), limiting the symmetry and expressiveness of the shared embedding.
This setup assumes a pretrained frozen model fθ (say, an image encoder), and learns a projection gϕ to align text embeddings.
Let’s say x_v from Xv is passed through frozen encoder fθ, and text xt∈Xt is passed through learnable gϕ. The goal is:
This encourages the text representation to project near the fixed visual embedding, using a simple L2 distance as the alignment criterion.
2. Autoregressive Mapping (Cross-Modal Generation)
Another class of models treated multi-modality as a sequence generation problem. Take image captioning as an example: you encode an image, and then train a language decoder to generate text tokens autoregressively. The reverse is done for tasks like text-to-image synthesis.

This paradigm is useful when one modality is the "driver" and another is the "target". But it doesn’t really capture mutual representation. Instead of building a shared latent space, it builds a direct translation from one modality to another, which doesn’t generalize well to tasks like retrieval or similarity search across modalities. This treats one modality as input and the other as output. For instance, generating text y=(y1,...,yT) from an image xv:
Here, the encoder fθ transforms the visual input into a context vector, and a language decoder generates the sequence. The loss is cross-entropy over each token.
This works well for translation but doesn’t yield a shared representation space. Still, it’s a great fit for generative tasks, and we’ll see this idea echoed later in BLIP2’s section on generative Q-former.
3. Joint Embedding Space (Contrastive or Metric Learning)
The most effective class of models in recent years has focused on joint embedding learning where both modalities are independently encoded and then trained to land close in a shared latent space.
For instance, given a set of paired image-text samples, the goal is to make their embeddings closer than those of mismatched pairs. This is typically trained using a contrastive loss or metric learning objective, which encourages semantically aligned items to cluster.
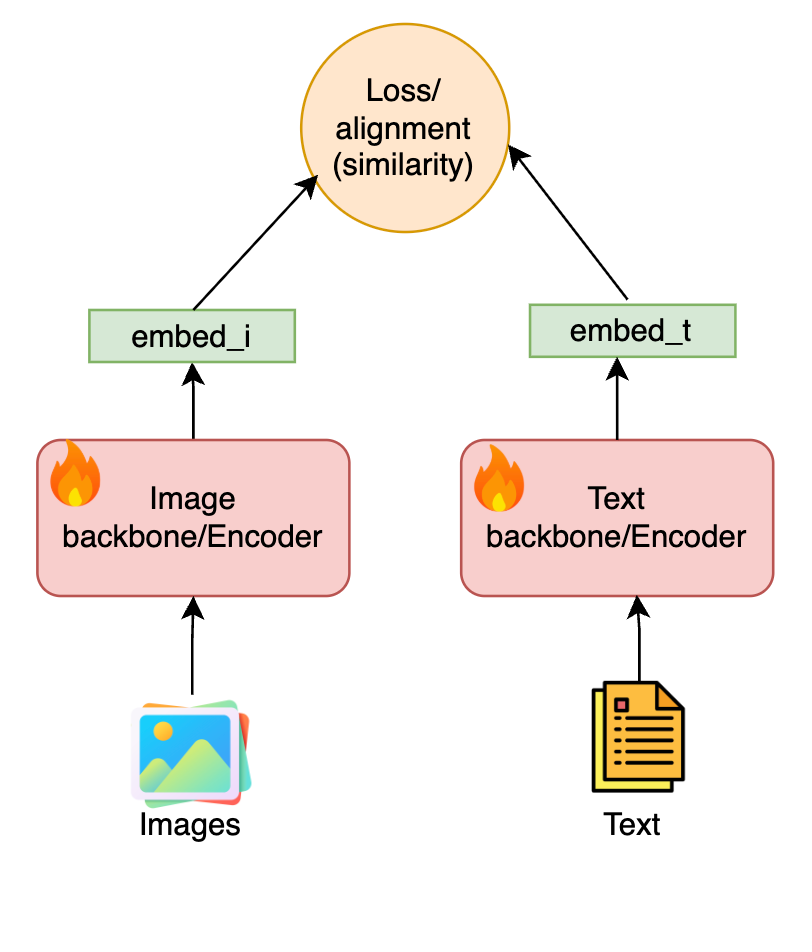
The beauty here is symmetry: images and texts both live and breathe in the same space. This opens the door to cross-modal retrieval, zero-shot transfer, and more.
This involves learning two encoders such that matched pairs are close, and unmatched pairs are far in a shared space. For a batch of NNN paired samples:
Where:
sim(⋅,⋅) is a similarity measure (e.g., cosine)
τ is a temperature hyperparameter (controls the weighting/scaling of values in exp space)
This is typically symmetric, i.e., a similar loss is computed from text to image. This is what CLIP uses.
The downside? Most of these methods depend heavily on batch-level negatives (e.g., other items in the mini-batch serve as negatives), which we’ll see later becomes a pain point and an opportunity for newer methods like SigLIP.
These paradigms like projective adaptation, autoregressive generation, and joint embedding collectively paved the road for modern multi-modal representation learning. Each came with different assumptions about what matters more: preserving modality-specific richness or enforcing global semantic alignment.
Fusion Strategies
The above section tells us how to merge and align the representations, but, another important question is when to merge/align the representations. There had been typically three ways to do this:
Early Fusion : In Early-stage merging (also called early fusion), raw or low-level features from different modalities, say, pixel embeddings from an image and token embeddings from text are concatenated or merged early in the pipeline, often followed by shared layers. This allows the model to jointly learn cross-modal interactions from the ground up. It’s appealing because it offers rich entanglement of features, letting one modality influence the learning of the other right from the start. But the downside? Noise and structural mismatch across modality-specific alignment can dominate or suppress meaningful interactions. Think of mixing sound and color gradients before understanding either properly.
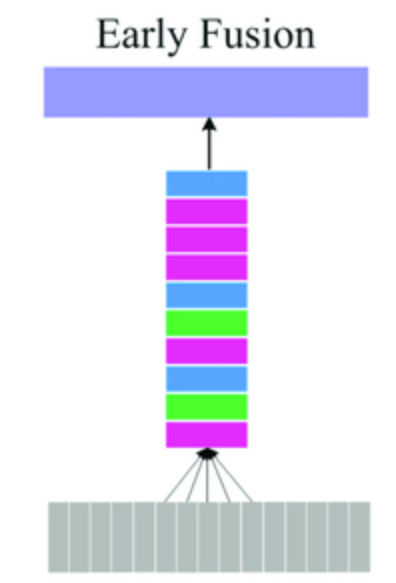
Late fusion : On the other extreme lies Late fusion, where separate modality-specific backbones extract mature, high-level features, and these are only combined toward the end, say, via attention, cross-modal gating, or even simple averaging. This is safer, often more stable, and modular. It’s the strategy adopted in BLIP and BLIP-2 (this we will cover later), where frozen vision and language encoders are aligned post-hoc through contrastive or generative heads. The limitation here is clear: semantic alignment becomes an afterthought, which may leave subtle gaps in shared understanding.

Intermediate Fusion : And somewhere in the middle lies intermediate fusion, allowing gradual, layer-wise mixing of modalities via cross-attention or adapters. This retains the interpretability and control of separate backbones, while allowing information to cross-pollinate more organically. Methods like Perceiver or Florence implicitly dance around this idea.
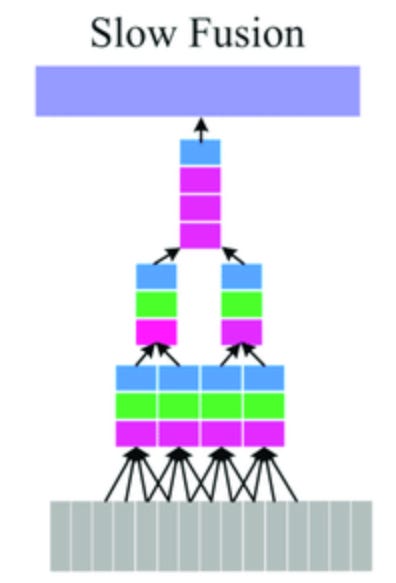
In essence, the “when to merge” question is not binary it’s architectural tuning of how early or late different signals should co-evolve. The ideal point probably isn’t fixed, it’s task-specific, modality-sensitive, and ripe for dynamic control. A promising direction might involve adaptive fusion controllers that decide fusion timing and weightings during training itself.
With that historical grounding, we’re now ready to deep dive into the architectures that shook up the field, beginning with the pivotal moment: CLIP.
CLIP: Contrastive Language-Image Pretraining
CLIP, or Contrastive Language–Image Pretraining, was OpenAI’s ambitious answer to a fundamental question in AI: “Can we train a vision model that understands images the way we describe them in natural language?”
Rather than training a classifier for a specific set of classes, CLIP trains two separate models ; one for images and one for text ; such that they learn to embed their inputs into the same latent space. In this shared space, semantically related image–text pairs lie close together, while unrelated ones are pushed apart. This is a paradigm shift: instead of fixed-category classification, the model learns open-ended understanding ; capable of zero-shot reasoning about any concept it’s seen in text or image form.
Why CLIP Works: Learning Alignment through Agreement
Imagine you’re shown a picture of a dog playing in a park. Without being told what’s in the picture, if someone gives you 5 possible captions, one of which is “A dog running in a green field”, you can probably match the correct one, even if you’ve never seen that specific dog before. That’s essentially what CLIP does during training.
Its objective isn’t to generate captions or classify images per se. Instead, it’s to learn a semantic agreement function: if the image and text feel like they describe the same idea, then their embeddings should lie close together in a learned vector space.
So, CLIP defines a contrastive learning task over a large dataset of image–text pairs scraped from the internet (e.g., from alt-text, captions, titles). Each image xix_ixi is processed by a vision encoder fθ(xi), while its associated caption tit_iti is processed by a text encoder gϕ(ti). These encoders might be ViT, ResNet for vision, and a Transformer for text.

The goal: Bring embeddings f(xi) and g(ti) closer if they belong to the same pair, and push apart all other mismatched pairs in the batch.
Lets, quickly have a deepdive in the math behind it
Given a batch of NNN image–text pairs, CLIP uses a symmetric contrastive loss:
Each sub-loss is a softmax over similarities between embeddings:
Where:
sim(a,b) is cosine similarity,
τ is a learnable temperature scalar controlling the softness of distribution.
The text→image loss is symmetric, you can also think of this as minimizing variance(distance)/maximizing similarity (across diagonal term) while maximing co-variance(distance)/minimizing similarity (across non-diagonal). In ideal case once a good quality encoder is trained, a NxM matrix (where N are images and M are text) will lead to a diagonal matrix (assuming order consistency).
Why Softmax? Why Contrastive?
CLIP uses a softmax over the batch to create a distribution over all possible matches. Basically asking: “How likely is this image to go with this caption compared to all other captions in the batch?”
This batchwise formulation gives contrastive learning its discriminative edge: the model learns to rank correct pairs higher than all other (negative) samples. The softmax sharpens the distribution; sharper scores help the model assign higher confidence to true matches.
This has one major implication:
CLIP does not learn absolute similarity. It only learns relative similarity over batches, which makes it great at ranking, but less effective at saying “how similar are two embeddings globally?” In my opinion a regularization term made of distance between eigen(NxN, rank=k) and eigen(MxM, rank=k), should result into a projection mechanism that is capable of sort of absolute similarity.
Key Intuition: Learning with No Explicit Supervision
What makes CLIP magical is it doesn’t require manually labelled categories. Instead, it leverages the weakly-supervised structure of internet-scale data. Captions become the supervision; fuzzy, sometimes noisy, but surprisingly rich.
So, instead of telling the model : “This is a dog” and “This is a cat”. CLIP says: “Here’s an image and a text. Are they talking about the same thing?”
This generalizes far better as you’re not bound by class labels. If a new object or concept appears in the test set, but was described in natural language during training, CLIP can often understand it. This is the essence of zero-shot generalization.
CLIP opened the floodgates for multi-modal alignment at scale. With just an image and its description, it could learn:
Generalizable representations
Powerful similarity-based reasoning
Zero-shot classification without task-specific heads
It’s the base of many systems today, from multi-modal RAG, zero-shot detection, image search, to alignment models for vision-language agents.
But, Where CLIP Falls Short?
Despite its brilliance, CLIP has limitations:
Softmax Dependency: The contrastive softmax requires large batches for good negative samples. With small batches, the model can get biased or collapse.
Relative Only: The embeddings are optimized for ranking, not absolute positioning. So global semantic similarity isn’t always meaningful.
Bias and Shortcut Learning: CLIP is still susceptible to co-occurrence biases. E.g., it might associate "snow" with "wolf" due to frequent co-captions, even when shown a husky in a summer park.
SigLIP: Sigmoid Loss for Language–Image Pretraining
CLIP was revolutionary, but not perfect. One of its biggest drawbacks came from the very thing that made it powerful: its softmax-based contrastive loss. While softmax helps rank image–text pairs within a batch, it inherently limits the model’s understanding to relative comparisons. This is where SigLIP (from Google Research) steps in.
The name SigLIP stands for Sigmoid-based Language–Image Pretraining, and at its core is a philosophical shift: “Rather than viewing image–text matching as a ranking problem, what if we treat it as an independent binary classification problem?”
In SigLIP, each image–text pair is judged on its own, without requiring the context of other pairs in the batch. This is more aligned with how humans assess image–caption alignment, I don’t need 31 other captions to tell if one matches the image.
What’s Different in SigLIP?
Instead of applying a softmax across all pairs (like CLIP), SigLIP uses a sigmoid activation and binary cross-entropy loss over devices:
Let’s denote:
xi as the image embedding from vision encoder fθ
ti as the text embedding from language encoder gϕ
sim(xi, tj)=cos(fθ(xi), gϕ(tj)) as their similarity, where cos represents cosine similarity
Then the loss for a batch of N image-text pairs becomes:
Where:
y_ij=1 if i=j (i.e., image and text belong to the same pair),
yij=0 otherwise
σ is the sigmoid function
This treats each (image, text) pair as an independent binary classification, “does this image match this caption?”
But, Why replacing Softmax with Sigmoid actually helps?
There are several intuitive reasons:
Softmax is batch-dependent
The softmax function normalizes across the batch. This means a pair’s loss isn’t just based on its quality but also how strong the other pairs are. This leads to:Sensitivity to batch size
Requirement for large, diverse batches
Lack of global semantic interpretability
Sigmoid is pointwise
With SigLIP, each pair is judged on its own merit. You can now compare any image and any caption, even from different batches or time frames. It’s better suited for retrieval tasks, embedding space interpolation, and fine-grained similarity comparisons.More Flexible Architecturally
Since there’s no need to compute scores for every pair in a batch (like softmax does), SigLIP is more scalable, and can even work with streaming data or asynchronous setups.
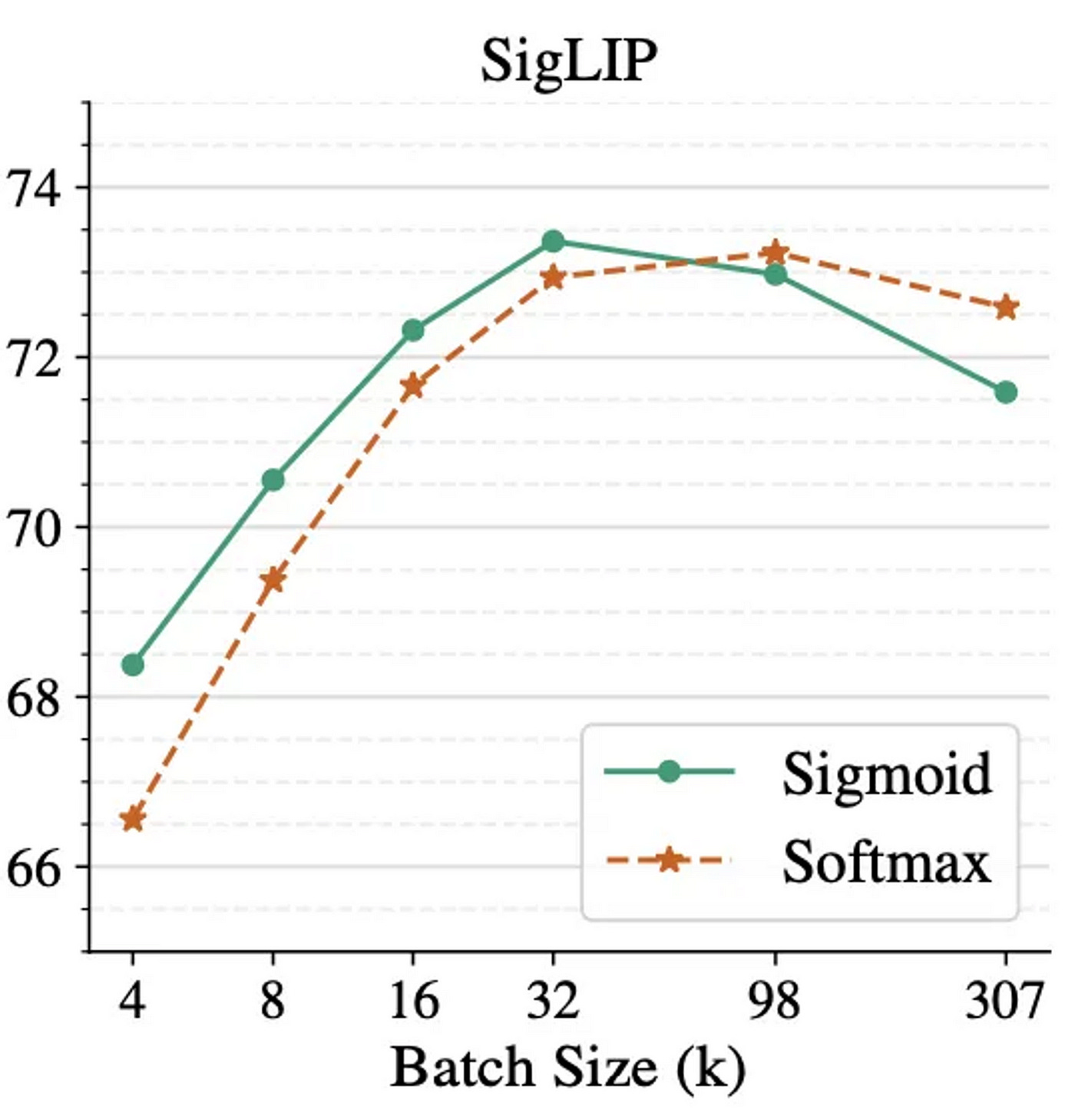
Benefits and Tradeoffs of Sigmoid-Based Loss
Advantages:
Global semantic space: Embeddings trained with sigmoid loss can be compared meaningfully across the dataset.
No batch sensitivity: Loss doesn’t require large or diverse batches.
Better generalization in some retrieval tasks (as shown in empirical benchmarks).
Simpler alignment objective: Just determine if a pair matches, rather than outscoring all others.
Drawbacks:
Class imbalance: Since there are N positives and N^2 - N negatives per batch, the loss must handle skewed supervision. Often mitigated with sampling strategies or weighted loss.
Harder negatives are less emphasized: Unlike softmax, sigmoid doesn’t naturally emphasize negatives that are almost correct, potentially losing some fine contrastive learning power.
Reduced mutual information maximization: The softmax-based InfoNCE loss (used in CLIP) directly ties to mutual information estimation between modalities. Sigmoid loses this property, though gains in generality.
Why This Matters: More than Just a Loss Function
SigLIP isn’t just a drop-in replacement. It reflects a paradigm shift in how we think about multi-modal alignment.
CLIP asks: “Is this caption better than the others for this image?”
SigLIP asks: “Does this caption match this image, yes or no?”
This makes SigLIP more robust in noisy environments, less brittle to batch selection, and more flexible in downstream usage; especially in cases where the semantics of alignment are binary or threshold-based.
In practice, SigLIP models have demonstrated better performance on zero-shot retrieval, semantic search, and tasks where global distance between embeddings is crucial.
BLIP: Bootstrapping Language–Image Pretraining
Before BLIP, most multi-modal models followed one of two schools:
Contrastive approaches (e.g., CLIP) which align images and texts via paired embeddings.
Generative approaches (e.g., image captioning models) which train one modality to output another.
But both approaches are partial. Contrastive models are great at global alignment, but don’t learn fine-grained understanding or reasoning. Generative models can learn semantic composition, but are limited to specific output forms.
BLIP asks a simple question: “What if we combined multiple training objectives; each focused on a different cognitive capacity to learn better representations?”
This leads to a multi-objective training regime that reflects how humans learn from images and language, sometimes matching, sometimes judging correctness, sometimes describing.

BLIP is a multi-objective approach to learning robust and generalizable multi-modal representations and is built around 3 key components:
Vision Encoder
Typically a ViT, which converts images into patch-level embeddings. These embeddings capture spatial and semantic information from the image.Q-Former (Querying Transformer)
A small transformer with a set of learnable query tokens. These tokens are passed through cross-attention layers to extract specific, task-relevant information from the image embeddings. (Think of these like “attention spotlights” scanning the image for what matters).Text Encoder / Decoder
Based on BERT and GPT-like models. The encoder processes text during understanding tasks, while the decoder is used for generation.
Multi-Objective Training Strategy
BLIP is trained with three parallel objectives, each encouraging a different form of multi-modal understanding:
1. Image–Text Contrastive Loss (ITC)
A direct extension of CLIP:
Encode an image →
f_img(x)Encode the paired caption →
f_txt(y)Compute contrastive loss across a batch (InfoNCE):
Where:
sim(·)is cosine similarity.τis temperature.y_jare other captions in batch.
Purpose is very simple, bring semantically matching image–text pairs closer in a global representation space.
2. Image–Text Matching (ITM)
A binary classification task: does this image match this caption or not?
Here, cross-attention is used between image and text; as the model explicitly reasons over how different parts of image and text relate.
This teaches the model to understand the relationship, not just the presence of correlation, hence, solves the shortcut problem in contrastive losses.
3. Language Modeling (LM) or Captioning Loss
Given image features (especially Q-former outputs), generate the appropriate caption. This is trained with cross-entropy loss over the predicted tokens:
This teaches the model to compose language from visual inputs, building deeper grounding (necessarily a L2 loss).
Why Multi-Objective Training Matters
Each objective serves a different role:

By combining them:
You avoid overfitting to one modality.
You increase generalization across downstream tasks.
You build a richer manifold where both matching and generation tasks benefit.
This is the key reason why BLIP performs well on both retrieval and captioning benchmarks, something CLIP alone struggles with.
The BLIP Training Pipeline
Here’s how a single training sample flows through BLIP:
Input: Paired image and caption
(x, y)Encode Image: Vision encoder processes
x → z_imgQuerying: Q-former distills
z_imgintoz_q, guided by learnable queriesText Encoding: Text encoder processes
y → z_txtCompute Losses:
Use
z_qandz_txtin contrastive loss (ITC)Use Q-former and cross-attention on
z_txtfor ITMFeed
z_qinto decoder to generatey, apply LM loss
The total loss is typically:
Where λ’s are tuned to balance different components. Often, ITC is used early in training to initialize representations, and LM is emphasized later.
Extra Notes
The Q-former is the secret sauce : it lets BLIP generalize across tasks while using the same visual backbone.
BLIP was trained on huge image–text datasets, including filtered LAION and Conceptual Captions.
Unlike CLIP, it can be used as a unified backbone for both retrieval, captioning, and VQA, truly multi-task.
BLIP introduces a multi-objective philosophy to vision–language learning. Instead of aligning modalities using a single loss, it uses a modular system that trains different “skills”:
Understanding alignment (contrastive),
Judging correctness (matching),
Producing fluent descriptions (captioning).
This allows it to serve as a foundation model for multiple downstream tasks far beyond what CLIP or SigLIP could offer.
Limitations of BLIP and how next generation (BLIP-2) addresses them
Rigid Coupling of Vision and Language Models
BLIP required joint training of both image and text encoders, making it resource-heavy and inflexible. This tight coupling limited modularity and reuse of large pretrained models.
BLIP-2 introduces a decoupled architecture, by freezing both vision (e.g., ViT) and language (e.g., Flan-T5) backbones and introducing a lightweight trainable Q-Former adapter. This allows modular upgrades without retraining the full stack.Limited Generative and Instruction-Following Abilities
BLIP was primarily optimized for retrieval tasks (e.g., image-text matching), lacking natural support for generative use cases like captioning or VQA.
BLIP-2 bridges this gap by feeding the Q-Former’s outputs into a frozen LLM’s token space, enabling autoregressive generation and strong instruction-following via instruction-tuned LLMs.High Training Overhead and Poor Transferability
BLIP’s architecture required significant compute and struggled to generalize across tasks or modalities without retraining.
BLIP-2 mitigates this with its plug-and-play design, reducing training cost by freezing large components while still achieving strong task performance through multi-objective learning and cross-modal alignment.
Now we know intricate details about of BLIP, where are some potential grounds for improvements and next generation BLIP2 solves it, lets have quick reference to BLIP2 for better understanding.
BLIP-2: Making Vision-Language Models Modular
BLIP-2 builds on BLIP by introducing a modular design that separates vision and language components. The key motivation is efficiency: instead of training large vision-language transformers from scratch, BLIP-2 reuses frozen pre-trained models; a frozen image encoder (like ViT from CLIP) and a frozen large language model (like Flan-T5 or OPT).
The only trainable part is a Querying Transformer (Q-Former) which is a lightweight module that extracts task-specific signals from the frozen vision encoder. This Q-Former generates compact token-like vectors which are projected into the language model’s embedding space, effectively allowing the LLM to "see" without being retrained.
![2301.12597] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://substackcdn.com/image/fetch/$s_!fN84!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fec301505-1d90-4e2f-8432-8a486b9559eb_830x375.png "2301.12597] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models")
Training happens in two stages:
Pretraining the Q-Former using contrastive and matching objectives (ITM/ITC), aligning vision and language in a shared latent space.
Vision-to-language generation : where the Q-Former’s output is passed to the LLM and fine-tuned via next-token prediction (language modeling), supporting captioning, VQA, and instruction following.
This design makes BLIP-2 more scalable, as heavy components remain frozen. Also, by aligning modalities through a small intermediate adapter, it reduces compute while preserving multimodal alignment.
Unlike CLIP/SigLIP that rely on contrastive learning alone, BLIP and BLIP-2 handles multiple objectives in stages, allowing retrieval, generation, and reasoning without overfitting or requiring all components to be co-trained.
5. Downstream Applications of Multi-Modal Representations
High-quality multi-modal representations like those learned through CLIP, SigLIP, and BLIP/BLIP-2 unlock a range of powerful downstream applications that go beyond just image-text retrieval. Because these models align information across modalities into a semantically meaningful representation space, they enable robust cross-modal reasoning, flexible querying, and impressive generalization.
Multi-Modal Retrieval and RAG
By projecting both visual and textual inputs into a shared representation space, models like CLIP and BLIP make it easy to build retrieval-augmented generation (RAG) systems that operate over multiple modalities. Imagine a system that can “look” at a frame from a video and pull up related textual documentation, or answer questions about a schematic image using text from a manual.
BLIP-2 takes this a step further by enabling generative capabilities on top of retrieval, forming the backbone of vision-language agents.
Semantic Compression and Reasoning
High-quality latent representations serve as a compressed semantic bottleneck. For instance, an image of a classroom and the sentence “a lecture in progress” may lie close in the latent space hence implying shared meaning. This semantic compression helps with memory-efficient storage, fast similarity-based reasoning, and even downstream tasks like clustering or anomaly detection.
Creative Content Generation
Because these embeddings carry rich semantic meaning, they can guide cross-modal generation. For example, generate a description of an unseen image (captioning), or visualize an idea expressed in a sentence. BLIP-2 especially excels here by leveraging frozen LLMs for detailed and controlled generative outputs conditioned on vision inputs.
Safety, Moderation, and Filtering
The aligned space also allows for scalable content filtering, like detecting mismatches between image and text (useful for deepfake detection, misinformation flagging, etc.). Classifiers built on top of aligned representations can flag unsafe content across modalities with relatively few training examples.
Interpretability and Attribution
One under-explored but promising use case is interpretability. When visual and textual data lie in the same space, it's easier to attribute predictions to semantically meaningful concepts. For example, a model’s classification of “surgeon” can be traced back to latent activations tied to visual cues (scrubs, operating table) and linguistic evidence. Tools can visualize which concepts in the representation space contributed most to a decision, opening doors for explainable AI.
Thoughts
As we journey through CLIP, SigLIP, and the BLIP family, what becomes increasingly evident is that representation isn’t just about alignment; it's about agreement across modalities, time, and task. Each methodology solves a piece of this puzzle, yet leaves subtle trails of questions and possibilities in its wake.
Take SigLIP for instance, while its use of sigmoid contrastive loss simplifies certain batch-dependent constraints and allows point-to-point comparisons, it may bias the representation space toward local pairwise structures, losing out on global semantic balance. This suggests a potential for hybrid methods hence, retaining sigmoid’s point specificity but combining it with global regularization objectives.
BLIP and BLIP-2 stand as textbooks on how multi-objective learning brings structure to chaos, from contrastive to generative supervision. Yet they rely on frozen backbones for vision and language encoders, this decision that balances stability and performance, but might limit full cross-modal fluidity. Could a carefully warmed-up backbone unlock even deeper alignment?
Another pressing thought is: What makes a representation truly generalizable across tasks and domains? In our previous article on SSL, we explored how representations evolve under different learning paradigms. The addition of multi-modal signals seems to refine those learned manifolds even further, pushing boundaries in creativity, robustness, and reasoning.
Lastly, there’s a philosophical itch: Are we forcing modalities into shared spaces prematurely? Maybe a richer architecture lies in understanding where and how to merge signals rather than just how to align them. Modality-specific pre-processing, dynamic attention fusion, and feedback-based grounding might be the next frontier.
We’ve made impressive strides; but this field, perhaps more than any other, still feels like a work in progress, a canvas in motion.
Conclusion
Learning to represent the world through multiple modalities : text, vision, sound; isn’t just a machine learning challenge. It’s an epistemic one. If intelligence is the ability to compress perception into abstraction and action, then multi-modal representation learning sits right at its core. Models like CLIP, SigLIP, and BLIP don’t just give us better embeddings, they reveal ways to connect how machines see with how they reason.
We began this article by revisiting the importance of high-quality representations and recapped our earlier journey through contrastive, distillation, and redundancy reduction methods from SSL. We then zoomed into why aligning representations across modalities is not just a technical goal, but a fundamental cognitive need. Along the way, we unpacked architectural nuances like early vs. late fusion, the role of adapter layers, and the evolution from fixed backbones to more fluid, compositional interfaces. We then explored from CLIP’s paired contrastive objectives to SigLIP’s refined use of sigmoid scoring and BLIP’s multi-objective, multi-phase pretraining, each method offered unique takes on alignment and generalization. We dissected their architectures, training paradigms, and design decisions, and grounded them in both their mathematical rationale and downstream applicability; from retrieval and RAG to interpretability and generative tasks.
At its heart, this field is still maturing; but the signals are strong. The future of multi-modal learning won’t just be about stacking more data or training bigger encoders;it’ll be about designing alignment-aware, goal-sensitive, and interpretable systems that see and think like us. Onward to building better bridges between the senses.
Some references:
CLIP : https://github.com/openai/CLIP
SIGLIP : https://arxiv.org/abs/2303.15343
BLIP : https://arxiv.org/abs/2201.12086
Fusion strategies : https://www.geeksforgeeks.org/deep-learning/early-fusion-vs-late-fusion-in-multimodal-data-processing/, https://arxiv.org/html/2411.17040v1
That's all for today.
Follow me on LinkedIn and Substack for more such posts and recommendations, till then happy Learning. Bye👋