
A Primer on Self-supervised Learning
Learn without labels, think beyond tasks. Self-Supervised Learning is how machines teach themselves, from contrast to clustering, from pixels to patterns; this is the backbone of modern AI systems.

Table of content
Why Representations Are Important?
What is Weakly Supervised Learning?
What is Self-Supervised Learning?
Description
But, Why Does SSL Work So Well?
Self-Supervised Learning Deep Dive
Similarity Maximization
Contrastive Learning
Clustering-Based Methods
Distillation-Based Methods
How This Generalizes Across Modalities?
Redundancy Reduction
Barlow Twins
VICReg and Others
How Redundancy Reduction Plays Out in Practice for Barlow twins
How SSL Shows Up in Modern Architectures?
Masked Language Models (MLMs)
Diffusion Models
Siamese Networks and Self-Distillation
Other SSL-Inspired Tricks
Thoughts
Conclusion
1. Why Representations Are Important?
Before diving into self-supervised learning, let’s address the foundational question; why do we care about learning good representations in the first place?
At the core of any learning algorithm lies its feature space ;a transformation of raw inputs (pixels, tokens, or signals) into a form the model can reason over. For a model to generalize well, its internal representation must capture semantics, not just memorize appearances. A face should still look like the same face under new lighting. A sentence should hold the same meaning even if paraphrased. That’s where the power of good representations lies ;they abstract away nuisances while preserving what matters.
Why pure supervised approaces are a bottleneck / sub-optimal way to learn data features?
In supervised learning, we often tie our representations tightly to labels, hence we learn P(y|X) whereas our focus should be to learn P(X). This works, but only up to a point. Labels tell you what an input is ;not how it should be represented. For instance, two dog images with wildly different backgrounds will get the same label, and the model might latch on to irrelevant pixels (like grass vs. sofa) if that helps reduce loss. So even though the model performs well on the label task, its representation might be brittle and shallow.

This becomes even trickier when we think about layer selection. Supervised models don’t build a uniform, general-purpose embedding ;they build task-specific hierarchies, and you’re left wondering: should I take the output from layer 4? Or 9? Or average across them? The representation isn’t naturally modular or transferable.
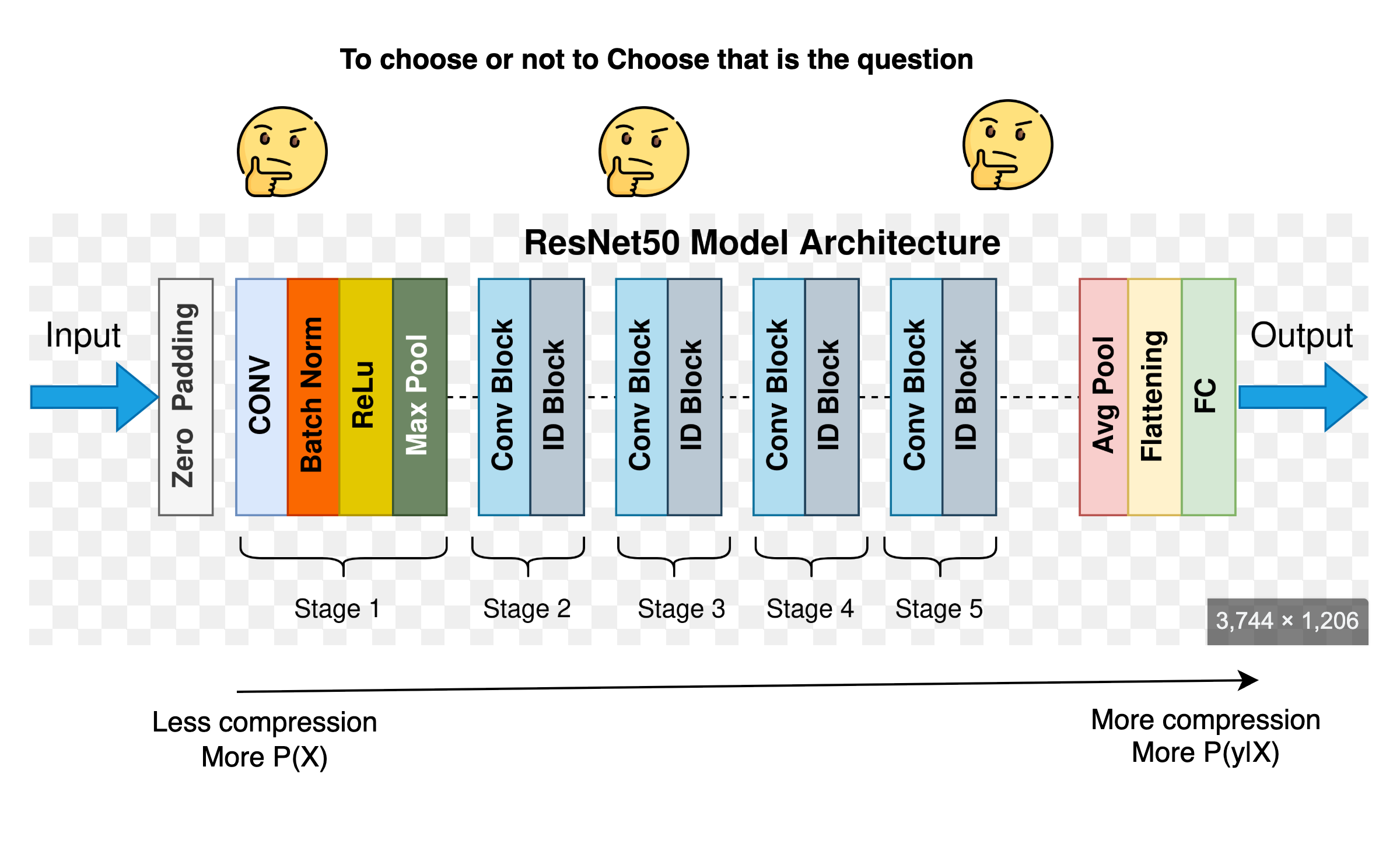
Even worse, supervised learning demands massive amounts of labeled data ;which is costly, slow, and often domain-limited. For niche fields (e.g., medical imaging, scientific instruments), getting clean annotations is nearly impossible. This creates a fundamental bottleneck: if learning is tightly bound to human labels, scaling becomes a dead end. You can find a dedicated line of reasoning for representations in our articles on BLT, LCM and LUSIFER.
So, we need something better; a method where representations are shaped not by rigid label constraints, but by the structure within the data itself. One that forces models to learn patterns, compositions, invariances ;not just names. And ideally, one that doesn't rely on humans for every new task.
That's where self-supervised learning begins to shine.
But before that, let’s explore a slightly less ambitious setup ;one where the labels aren’t fully supervised, but are weakly derived from the data itself.

Let’s talk about weakly supervised learning first.
2. What is Weakly Supervised Learning?
Before self-supervision became mainstream, one intermediate solution began to catch traction; weak supervision. Think of it as using whatever imperfect signal you can find in the data to bootstrap a learning task.
In weakly supervised learning, we don't provide manual, gold-standard labels for every data point. Instead, we rely on metadata, heuristics, distant supervision, or implicit cues as proxy labels. These labels are noisy, incomplete, or indirect, but they often correlate with the underlying structure we care about.
Take for example image datasets scraped from the internet. A filename like "sunset_beach_023.jpg" isn’t a label in the strict sense; but it can be used to weakly supervise a task like scene recognition or aesthetic quality. Or consider hashtags on social media; not always accurate, but they’re rich signals nonetheless. Even timestamps, user interactions, or GPS coordinates can all be treated as weak labels depending on the task.

Let’s say you’re working with a massive dataset of bird sounds. Annotating exact bird species for each recording is expensive. But if the file contains a location tag; say, “recorded in Northern California”; that geo metadata can act as a weak label. You could then train a model to associate sound patterns with regions, and indirectly learn species-level differences without ever seeing exact bird names.
Another good example is in medical imaging. Instead of manually labelling every x-ray, you might use diagnosis codes from patient records or even radiology reports as noisy labels. It’s not perfect; but it’s far more scalable.
But weak supervision still depends on some form of external labelling; however noisy or latent it might be. This means it still requires pre-existing structures around the data; like metadata pipelines or prior knowledge. It's a useful compromise, but not fundamentally label-free.
Which brings us to the real game-changer: self-supervised learning, where the data supervises itself. No human tags, no external metadata, just raw inputs and clever learning objectives.
That’s where things get interesting.
3. What is Self-Supervised Learning?
So far, we’ve seen how supervised learning depends on human-labeled data, and how weak supervision tries to scrape structure from metadata or context. But both rely on external labels. What if we could flip the idea of supervision on its head?
Self-supervised learning (SSL) does exactly that. Instead of relying on someone else to define the learning signal, we generate it from the data itself; by defining tasks where the input can be split, transformed, or perturbed in a controllable way. These tasks are called pretext tasks.

Let’s take an example from vision. Suppose you crop an image into patches, shuffle them, and ask a network to reassemble the correct order. You’ve now created a jigsaw puzzle task; no labels needed. Or rotate an image randomly, and ask the model to predict the rotation angle. These are pretext tasks because they aren’t directly meaningful in the real world; no one needs a rotation predictor; but they force the model to understand structure, orientation, and object coherence in the image. And that’s exactly what a good representation should do.
In formulaic terms, self-supervision says:
Where fθ is the feature extractor, and the goal is to make sure that the representation doesn’t change even if the input undergoes a transformation; like flipping, cropping, distorting, or reordering. These transformations become the labels.

The core assumption here is simple yet powerful: if two different views of the same data point (e.g., two crops of an image) are still semantically the same, then their features should align. This assumption of invariance under transformation lies at the heart of SSL. But if we push this idea too far, we run into a dangerous edge case; mode collapse.
Mode collapse is when the model learns to output the same representation no matter the input. It learns to ignore the augmentations; and everything else too. Why? Because if the objective is to make all augmented views match, the trivial solution is to map every input to the same constant vector. It's invariant, sure; but also useless.
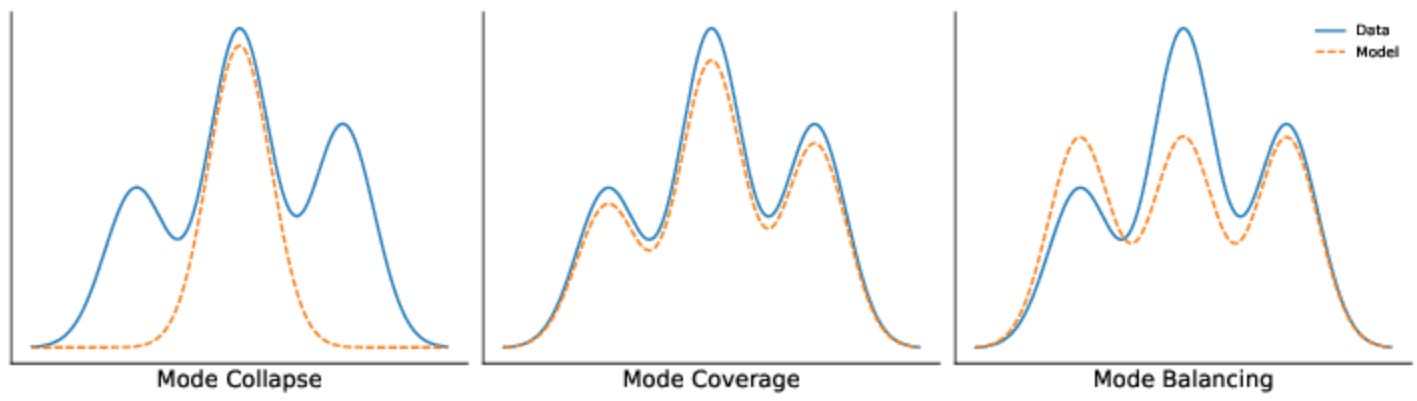
This is where design matters. Successful SSL systems have to walk a fine line; enforcing consistency under transformations without collapsing representational diversity. Methods like contrastive learning, asymmetric architectures, and decorrelation penalties are built precisely to prevent this collapse, as we’ll explore in the next section.
But before that; let’s pause for a personal note.
Why Self-Supervised Learning Is My Favourite Topic ❤️
SSL isn’t just a clever hack; it’s a philosophical shift. It allows us to learn directly from the data; without human bottlenecks, without rigid taxonomies, and without assuming what matters in advance. That’s especially powerful in low-data regimes, niche domains, or edge applications where labels are scarce or expensive. Even more exciting are the practical implications. SSL lets us pre-train models on raw sensor streams, medical scans, audio clips, or even logs; all without needing to define a formal label set. From industrial anomaly detection to medical diagnostics, this opens up whole new classes of problems.

And honestly; the sheer creativity of SSL methods is inspiring. Every pretext task feels like a small puzzle, asking: What could I predict from this data that forces the model to understand something deeper about it?
But, Why Does SSL Work So Well?
The answer lies in its inductive bias. Most augmentations used in SSL; like crops, color shifts, or reorderings; preserve the semantic content while altering the surface. When we force a model to ignore the surface while staying sensitive to structure, we’re nudging it to encode what the data actually is, not how it looks.
Put differently, SSL builds a feature space where samples with similar meaning; but different appearances; cluster together. That’s the essence of generalization. It’s almost poetic. Instead of asking the model to memorize names, we ask it to discover identity. And that, in many ways, is a better definition of intelligence.
4. Self-Supervised Learning Deep Dive
At the heart of SSL lie different philosophies of how to learn meaningful features without labels. But at a high level, we can categorize most modern methods into two broad approaches:
Similarity Maximization : where we explicitly align augmented views of the same instance in feature space.
Redundancy Reduction : where we focus on ensuring the learned features are diverse, decorrelated, and structured.
Let’s begin with Similarity Maximization.
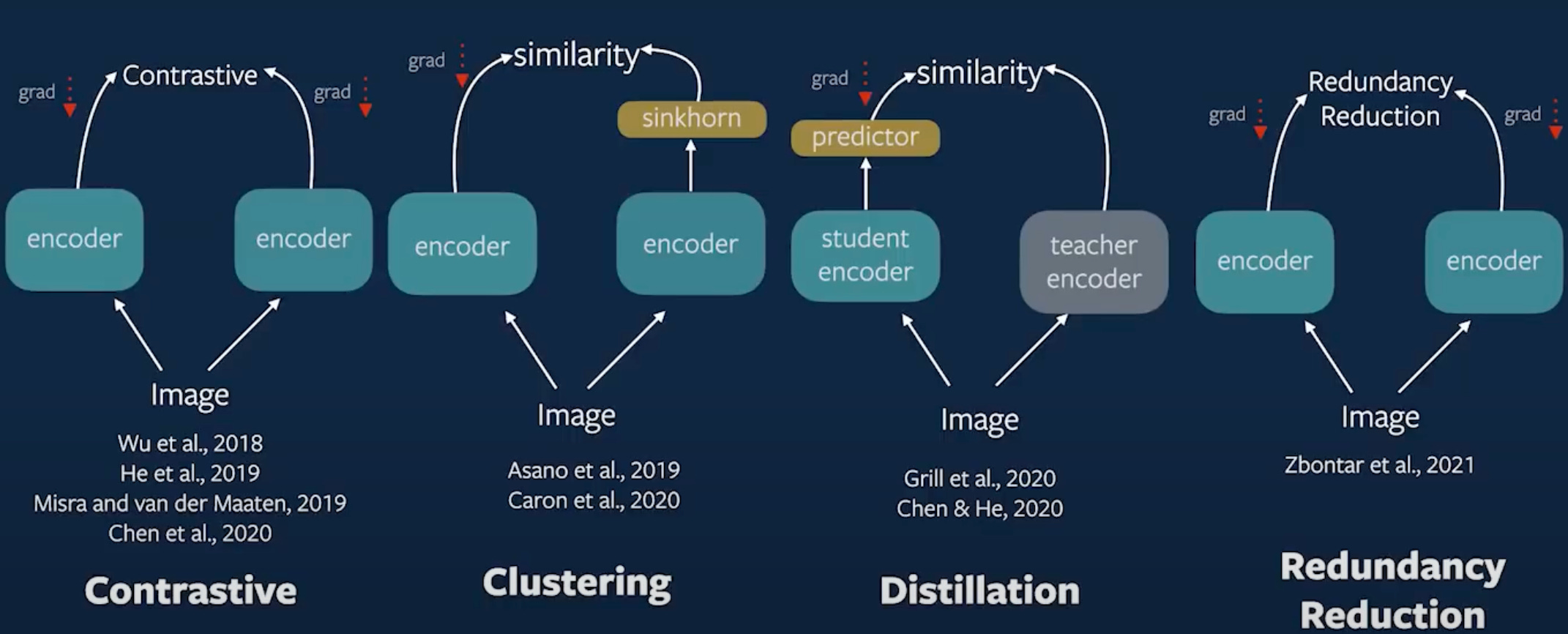
4.1 Similarity Maximization
At the heart of many self-supervised methods lies a deceptively simple goal, if two views of the same data point represent the same underlying concept, then their embeddings should be close in some feature space. This principle, called similarity maximization, powers most early SSL models.
The core idea is this: take an input sample x, apply two independent augmentations t1 and t2, and push their representations closer:
In this family of methods, we’re given two or more augmentations of the same input, say x1 and x2, and the objective is to bring their representations closer together:
This forms the core contrastive setup. But how we define “distance”, how we handle negatives, and how we ensure non-trivial solutions; these give rise to different flavours.
4.1.1 Contrastive Learning
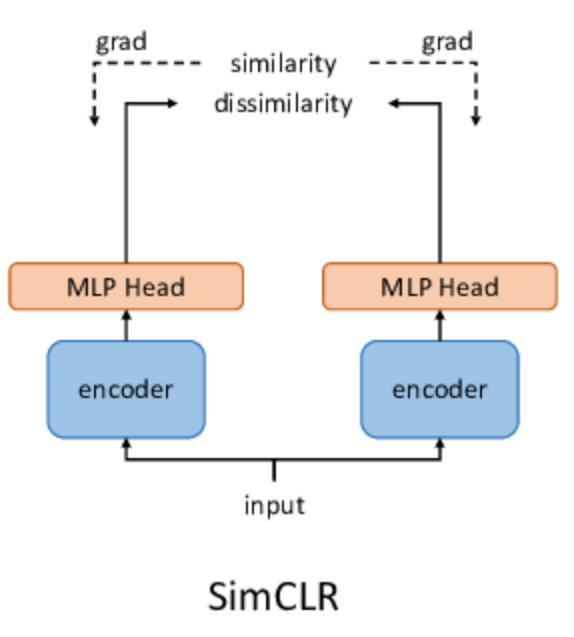
Contrastive learning is perhaps the most well-known flavour of SSL. It’s based on a simple idea, pull together positive pairs, and push apart negative ones.
")
You start by generating two views xi and xj of the same image x, and treat them as a positive pair. All other views from other images in the batch are considered negatives. The model is trained using a contrastive loss like NT-Xent:
Where:
sim(zi,zj) is cosine similarity,
τ is a temperature hyperparameter,
zi are normalized projections of encoded features.
This is what powers SimCLR, a simple yet powerful framework where large batch sizes help get more diverse negatives.
But SimCLR needs big compute. So MoCo (Momentum Contrast) takes a different route: instead of a large batch, it maintains a dynamic queue of negative samples (A Memory Bank) and uses a momentum encoder to build stable targets.
 | by Nour Eldin Alaa | Medium")
Then comes PIRL, which adds spatial understanding. It learns representations that are invariant not just to augmentations, but also to patch permutations by enforcing local part-based consistency (patch from same image should be similar).
All of these share a common idea: a strong encoder learns invariant features by being trained to distinguish “same vs different”. But they also share a weakness: they rely heavily on negative samples. If negatives are too similar to positives (false negatives), learning suffers.
4.1.2 Clustering-Based Methods
What if we don't explicitly define negatives at all?
Enter clustering-based approaches like DeepCluster, SwAV, and SeLA. These don’t work with contrastive losses. Instead, they assign pseudo-labels based on cluster assignments and train the model to match augmented views to the same prototype.
SwAV (Swapped Assignments between Views) is a great example. It avoids sampling negatives entirely. Instead, it uses a prototype space and swaps the prediction target across augmented views:
Here q(xi) is the predicted probability over prototypes for view i, and p(xj) is the fixed assignment from another view.
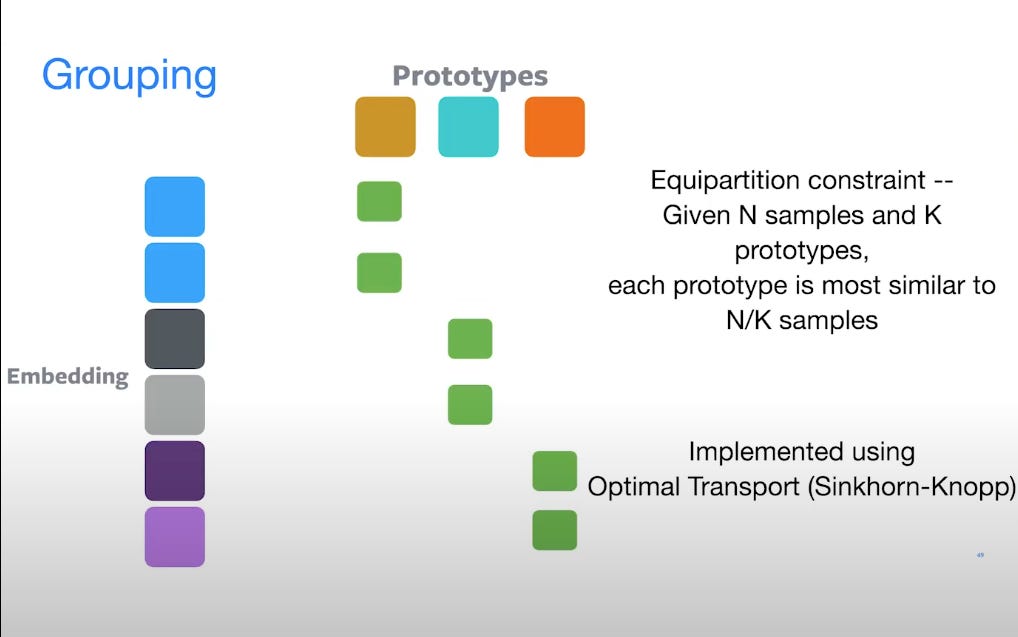
To ensure these prototypes are evenly used (to avoid collapse), SwAV uses Sinkhorn-Knopp algorithm, which simply put is a smart matrix normalization trick that encourages equipartition across prototypes/cluster centres.

The idea is simple, given we have embeddings (from encoder) and codes (from prototypes), even if we swap the embeddings, as they are part/crop of same image they should still be approximately allocated to same type of prototype space/cluster groups.
The result? You get a clustering method that’s online, non-contrastive, and avoids the need for massive batch sizes or memory banks. These methods are especially appealing for low-resource settings.
4.1.3 Distillation-Based Methods
A newer direction in similarity maximization removes both negatives and clustering. Instead, it distills a moving target into a student by forcing alignment between two networks in a self-supervised fashion.
Take BYOL (Bootstrap Your Own Latent); There are no negatives, No clustering. You simply pass augmented views into two encoders; one student and one momentum-updated teacher and align their representations.
This sounds like it should collapse. But surprisingly, it doesn’t, because the teacher is updated using exponential moving average of the student, breaking symmetry and preventing triviality.

Then there’s SimSiam, which pushes this even further. It uses a stop-gradient trick and no momentum at all. Instead, it learns using an asymmetric architecture; one side with a predictor head, the other without. This shows that asymmetry alone is enough to prevent collapse.

These distillation-style methods are elegant, simple to implement, and work surprisingly well, even outperforming contrastive setups in low-batch, low-compute environments.
How This Generalizes Across Modalities?
Although most self-supervised techniques were first popularized in computer vision, the core idea of learning by aligning multiple views of the same input is incredibly flexible; and translates beautifully across data modalities.
Let’s start with images. Visual data is inherently redundant; a cat image can be cropped, color-shifted, blurred, or rotated, yet still remain semantically a cat. That’s why techniques like SimCLR, MoCo, and BYOL work so well here; cropping or distorting the image acts as the augmentation, and the model learns to extract content that’s stable despite these transformations. Think of it as training a model to look through the noise and see the essence.
In text, things look a bit different; you can’t just crop a sentence. Instead, you use word dropout, token masking, sentence reordering, or even back-translation as augmentation. For instance, two paraphrased versions of a sentence serve as positive pairs. Models like BERT rely heavily on these kinds of self-supervised setups; where the objective is to predict missing words or reconstruct shuffled inputs. SimCSE pushes this even further, using dropout as the only source of augmentation to generate different views of the same sentence.

In time-series data, augmentations can be applied along the temporal axis. For example, you can jitter, crop, or warp a subsequence. Suppose you're working with ECG data; you can add small time warps or Gaussian noise to simulate variations in heartbeat patterns. The model then learns to represent the underlying rhythm, not the surface-level fluctuations. This has proven useful in biosignals, industrial IoT, and even finance.
Even video becomes a playground for SSL. Each video clip inherently contains multiple temporal views; one can shuffle frames, predict motion vectors, or learn future frames given the past. Contrastive Video Representation Learning (CVRL), for instance, uses clips from the same video as positives and others as negatives; essentially saying, "learn to tell apart what's part of the same scene."

Across all these modalities, the principle is the same:
Good representations are those that remain stable under transformations that don’t change semantic meaning.
The only thing that changes is what counts as a meaningful augmentation; and that depends on the domain. In vision, it’s crops and colors. In text, it’s token manipulation. In time, it’s jitter and warps. But in all cases, the model is forced to learn what stays constant; and that becomes the basis for generalization.
4.2 Redundancy Reduction
While contrastive and clustering-based methods focus on similarity between augmented views, another line of work takes a different path: rather than maximizing similarity, it focuses on minimizing redundancy.
The idea is simple: if your model encodes useful information from data, then its representations shouldn’t just be invariant, they should also be disentangled and diverse. In other words, each feature dimension should carry distinct information about the input. If multiple neurons encode the same thing (say, just brightness or edge orientation), your representation isn’t very informative.
This motivates redundancy reduction–based SSL methods; where the model is trained to make the representations of two augmented views not only close to each other, but also de-correlated across dimensions.
4.2.1 Barlow Twins
Let’s start with Barlow Twins, a pioneering method in this family. It draws inspiration from neuroscience, particularly the theory that biological systems perform redundancy reduction to maximize information throughput.
In Barlow Twins, we take two augmentations of the same input x, say x1 and x2, and encode them through the same network fθ. This gives two representations: z1=f(x1), z2=f(x2).

Then we compute the cross-correlation matrix C∈Rd×dC between z1 and z2 over the batch:
This matrix tells us how aligned each dimension of one representation is with each dimension of the other.
Now here’s the key idea:
We want the diagonal entries of C to be close to 1 → same dimensions match across views.
We want the off-diagonal entries to be close to 0 → different dimensions are uncorrelated.
The loss becomes:
This does two things at once:
Forces features from both views to align (invariance).
Encourages each neuron to learn something different (diversity).
The beauty here is that there's no need for negatives, no momentum encoders, and no clustering, just good old batch statistics and linear algebra.
Here’s an example intuition: Imagine learning to represent handwritten digits. A trivial solution would be that all neurons detect loops; great for ‘6’, useless for ‘1’. Barlow Twins forces the model to spread out, assigning one neuron to detect roundness, another to slant, another to stroke length, etc. hence, capturing more diverse traits.
4.2.2 VICReg and Others
Barlow Twins inspired a family of de-correlation-based approaches.
VICReg (Variance-Invariance-Covariance Regularization) extends Barlow by explicitly adding three terms:
Invariance: minimize distance between augmented views.
Variance: ensure each feature has non-zero variance (prevents collapse).
Covariance: reduce off-diagonal entries in covariance matrix (redundancy).

VICReg has better stability, especially under high-dimensional settings. Like Barlow Twins, it operates in a non-contrastive setup; hence no negatives required.
How Redundancy Reduction Plays Out in Practice for Barlow twins
Just like similarity-maximization methods, these techniques generalize across data types:
Images: Barlow Twins is known for impressive performance on ImageNet linear evaluation. It’s especially useful when batch sizes are limited and contrastive setups are hard to scale.
Text: Redundancy reduction isn’t as common yet, but recent work explores using token-level decorrelation across augmented views like masked spans or reordered clauses.
Time-Series: By encoding sequences and ensuring de-correlated latent features, models can better separate periodic signals, anomalies, and trends, which is crucial for applications like bio-signal monitoring or anomaly detection in sensors.
What sets this family apart is its simplicity and elegance. There are no memory queues, no hard negatives, and minimal architectural overhead. These models often converge faster, and are easier to implement without exotic training tricks.
5. How SSL Shows Up in Modern Architectures
Once a curiosity, self-supervised learning is now a foundational principle quietly driving some of the most powerful systems we interact with daily from large language models to image synthesis pipelines. Many of these models don’t explicitly advertise themselves as “self-supervised,” but dig into their training pipelines, and you’ll find the same old idea: learn by predicting parts of the input from other parts.
Let’s explore a few key examples.
Masked Language Modeling (MLM)
Let’s start with language. The transformer revolution began with BERT, which was trained using masked language modelling; a textbook example of self-supervision.
You take a sentence like: “The cat sat on the [MASK].”

And the model is asked to predict the masked word “mat”. There's no external label; only a transformation applied to the input, and the original content becomes the target.
Formally, the task can be seen as:
Where M is a random masking pattern, and x\M is the input with masked tokens.
This approach forces the model to deeply understand contextual structure. To fill in the blank, it must grasp grammar, semantics, and even world knowledge. It’s self-supervision at its best and it scales. Nearly every modern language model (BERT, RoBERTa, DeBERTa, ELECTRA, etc.) uses some variant of this idea.
Diffusion Models
Self-supervision also plays a central role in diffusion-based generative models like Stable Diffusion, Imagen, and DALL·E 3.
In diffusion, you start with clean data (say, an image), gradually corrupt it by adding noise over TTT steps, and then train a model to denoise:
“Given a noisy image at step t, predict what it looked like one step earlier.”

Again, the model never sees human-provided labels. Its only job is to learn the structure of the data by reversing a synthetic corruption process.
In fact, the objective here resembles Denoising AutoEncoders (DAE), an early SSL concept. Diffusion could be thought of as multi-step DAE, obviously with a more sophisticated loss calculations. The model learns a conditional distribution:
And the overall loss is often a form of mean squared error (MSE) between the predicted noise and the true noise:
This training setup is entirely self-supervised: the model learns to recover structure from noise; no labels, just raw samples.
Siamese Networks and Self-Distillation
Methods like BYOL, SimSiam, and even DINO are powered by Siamese architectures where two branches process augmented views of the same input, and the goal is to make their representations align. While this started in self-supervised image recognition, it’s now a core idea in representation learning for multimodal, video, and speech models.
Even models like CLIP though trained with supervision, borrow ideas from self-distillation and multi-view alignment. SSL taught us that powerful representations emerge when we treat multiple views of the same object as semantically consistent, even when they differ in appearance.

Other SSL-Inspired Tricks
Masked image modeling (as in MAE): mask out image patches and predict them back.
Contrastive vision-language learning: like in ALIGN or CLIP.
Pretext-based audio representation: e.g., wav2vec or HuBERT, where audio frames are masked and predicted.
SSL in robotics: predicting ego-motion from frame pairs to learn action-relevant representations.
Across all of these, the pattern is clear: create a transformation that hides or alters information, and train the model to reconstruct, contrast, or realign.
6. Thoughts
By now, it's clear that self-supervised learning (SSL) isn't just some academic curiosity; it's a pragmatic, scalable, and beautiful way of learning. But like everything in machine learning, different methods behave differently depending on the data modality, architecture, and even training dynamics.
Let’s reflect on some of the broader takeaways, starting with when and where different methods excel.
When Does What Work Best?
In general, if you're working with high-dimensional data and a rich set of augmentations; like in vision or video; contrastive learning tends to do really well. The presence of hard negatives helps sharpen the boundary between semantically different objects. That’s why SimCLR and MoCo shine on datasets like ImageNet.
But if you're working with small batch sizes or low-resource settings, clustering or distillation-based methods might be more efficient. BYOL, SimSiam, and SwAV don’t need huge memory banks or large compute; they work elegantly even in constrained environments. Plus, they tend to converge faster.
And when you're building systems that demand representational diversity; where interpretability or disentanglement is key; redundancy reduction techniques like Barlow Twins or VICReg are often a better fit. You don’t just want a representation; you want a structured, rich one.
Videos: The Untapped Goldmine of SSL
One idea I find particularly fascinating is the use of videos as natural supervision signals. Think about it; videos contain both spatial and temporal variation. If a model can learn to associate the motion of a bouncing ball or the changing lighting on a face over time, it’s learning physics, structure, and object permanence; all without labels.
SSL methods in video can combine spatial augmentations (like crops or color changes) with temporal ones (like frame reordering, future prediction, or slow-fast sampling). This opens the door to learning representations that aren’t just robust to change; they encode change itself.
In robotics, this could help machines learn cause-effect relationships. In healthcare, it could detect motion-based anomalies. And in AI planning, it could lead to more grounded decision-making.
One Representation to Rule Them All?
A long-standing dream in ML is to learn a universal representation; one that generalizes across tasks and domains. SSL might just be our best shot.
Why? Because it doesn’t depend on labels. It lets the model discover structure on its own; and that structure is often closer to the true manifold of the data than anything handcrafted.
But we must be careful. Many SSL methods are sensitive to batch size, augmentation type, and architecture. And in some cases, the representations are great for one task (say, classification), but not for another (like segmentation or depth estimation). So the dream of universality still requires task-aware fine-tuning and adaptation modules, around which we wrote a very detailed blogpost which you can find here:
Still, SSL is the strongest foundation we've ever had for moving toward general-purpose intelligence.

7. Conclusion
If there's one thing Self-Supervised Learning (SSL) teaches us, it's this; we don’t always need someone to tell us what to learn. Sometimes, data contains enough structure to supervise itself. And more often than not, that form of supervision is more scalable, more natural, and more transferable.
Throughout this article, we started by understanding why representation learning matters, and how supervised labels fail to encourage deep understanding. We explored how SSL emerged as a natural solution; by crafting clever pretext tasks that force a model to extract signal from within the data itself.
We went for a deepdive into two main SSL strategies;
Similarity Maximization, which aligns multiple views of the same input (via contrastive, clustering, or distillation methods)
Redundancy Reduction, which ensures diversity and structure in the learned features (via Barlow Twins, VICReg, etc.)
We then discussed how these concepts quietly drive the training paradigms of modern systems; from masked language modeling in BERT, to denoising in diffusion models, to Siamese structures in BYOL and SimSiam.
Finally, we reflected on practical tradeoffs, modality-specific strengths, and the fascinating future of using videos as rich supervision signals.
With this we come to the conclusion of yet another primer, my attempt with these articles is awareness and sufficiency for explorations. In no way this or any other article of mine is complete/comprehensive enough to cover the entire depth and breadth of the beautiful theory behind these systems. For reference, Abstract algebra, vector spaces and manifold theory are crucial to understand representations, but, it is not feasible for me to go through any of them with sufficient clarity. Hence, please do that random walk in higher space of knowledge given that you have a direction/structure now with this article.
Here are few References
That's all for today.
Follow me on LinkedIn and Substack for more such posts and recommendations, till then happy Learning. Bye👋