
🌌LUSIFER: Language Universal Space Integration for Enhanced Multilingual Embeddings with Large Language Models🤖
Utilising language shared subspaces as proxy for training task aligned embedding models without explicit need of language specific data


With rise in LLM capabilities, multiple downstream tasks and use-cases have emerged, ranging from zero shot classification to needle-in-haystack searches.

Central to these tasks is high quality representations/embeddings. Check out these two articles to understand the knitty-gritty details and base ideology behind representation spaces and their requirement.


One of the most important and potentially challenging task is retrieval (specially dense retrieval), simply defined as finding similar information from a large corpora, which inherently is dependent on embedding alignment. As the retrieval task forms backbone of modern day problems like search engine (as in perplexity.ai), they have to be extremely precise and tuned to generate best search results. The function which serves as embedding generator is referred as embedding model and is central component of any retrieval pipeline. The search, hence is heavily dependent on retrieval which in itself is a outcome of this embedding model.
Hence, we demand few intrinsic qualities from our embedding model for dense retrieval.
It should be blazing fast and hence we need an efficient function to generate these embeddings.
Extremely strong multilingual capabilities across any domain specific task.
Table of content
Why multilingual retrieval?
Objective
Ideal case
Methodology
Training architecture
Training pipeline
Outcome
Thoughts/Next steps
What we learnt today?
Why multi-lingual retrieval?
Imagine searching for an item over the search engine we talked about above and you end of up with something completely nonsensical. The worst part is that we cannot have different embedding model for each language, because not only it will decrease the speed of our pipeline but also will make it susceptible to error, as there needs to be a preceding block before all the language specific embedding models for assignment, any mistake there will trickle down to bad assignment and hence poor generation. Imagine searching something in Spanish, your assignment model classifying it as French and fetching embedding from the French model. Also, as discussed in our LCM article (find link above) language in itself is bad translation of thoughts, hence we need to work over concepts/latent space/embeddings.
The simplest way to solve this is to bring everything to a common space, which is conventionally done by language translation, where any input language is first converted to English (or any heavily sampled language) and then fed to a single embedding model (good with English only).
Another way could be to train a single model that knows every language and fetch embedding out of it. Though it solves both of our issues, it adds a new one, the quality of embeddings. These embeddings are specialized for multiple downstream tasks, for example, a embedding model for unstructured data won't work good enough with structured data (tables). Though we can train a very large model on all possible data, but, it defeats our 1st requirement; also, the current datasets for languages are primarily composed of English and similar languages. For less representative/low resource languages where samples are not present for a certain tasks, training such big architecture becomes problematic. For example, imagine building a RAG application over structured data on Swahili documents, the unstructured language documents in itself are very scarce, leave the structured part of it.

Objective
Now, let's summarize quickly
1. We want a fast and high quality multi-lingual embedding model for any downstream tasks.
2. We cannot use translation operation as it is slow and adds erroneous function on top of pipeline.
3. We can train a large embedding model, but, it would be slow and we don't have sufficient data for each downstream tasks for every possible language.
4. We also want to leverage the already existing models trained on the available multi-lingual datasets (we don't want to reinvent the wheel), but, in such a way that they can align with any embeddings from LLM designed for any downstream task.
Ideal case
Let's go through a quick analysis of what we ideally have.
1. We have good quality multi-lingual representation model (but it doesn't perform task alignment properly).
2. We have efficient and well trained down stream LLMs for generating high-quality embeddings for downstream tasks (but it struggles with multi-lingual data).
Now, how can we connect these two together and that too without using any language specific data? this is supposedly our ideal case. The answer is given in the paper which we are discussing here.
Methodology
Training architecture

The paper presents a three block mechanism which is comprised of:
A multi-lingual encoder block (A) to convert any language to an embedding vector. Here, they used XLM-R1 (which is a large scale language generation model trained on multi-lingual datasets).
A connector block (B) to convert encoded embeddings from A to usable form for embedding model (C) referred as H_align. The H_align embedding is of same shape/dimensions as that of the target LLM representation space and serves as a bridge between source and target distribution of one LLM/source (our encoder) and target LLM (Embedding model). Connector is a series of sophisticated dense blocks, making up a small trainable parameter set.
An target embedding model block (C) to take in the embeddings and generate task specific representations. This embedding model could be anything, for example, gpt2, llama, etc.
The pipeline is trained only using english language, and is supposedly working for every available language (we will cover this point in next block).
Training pipeline
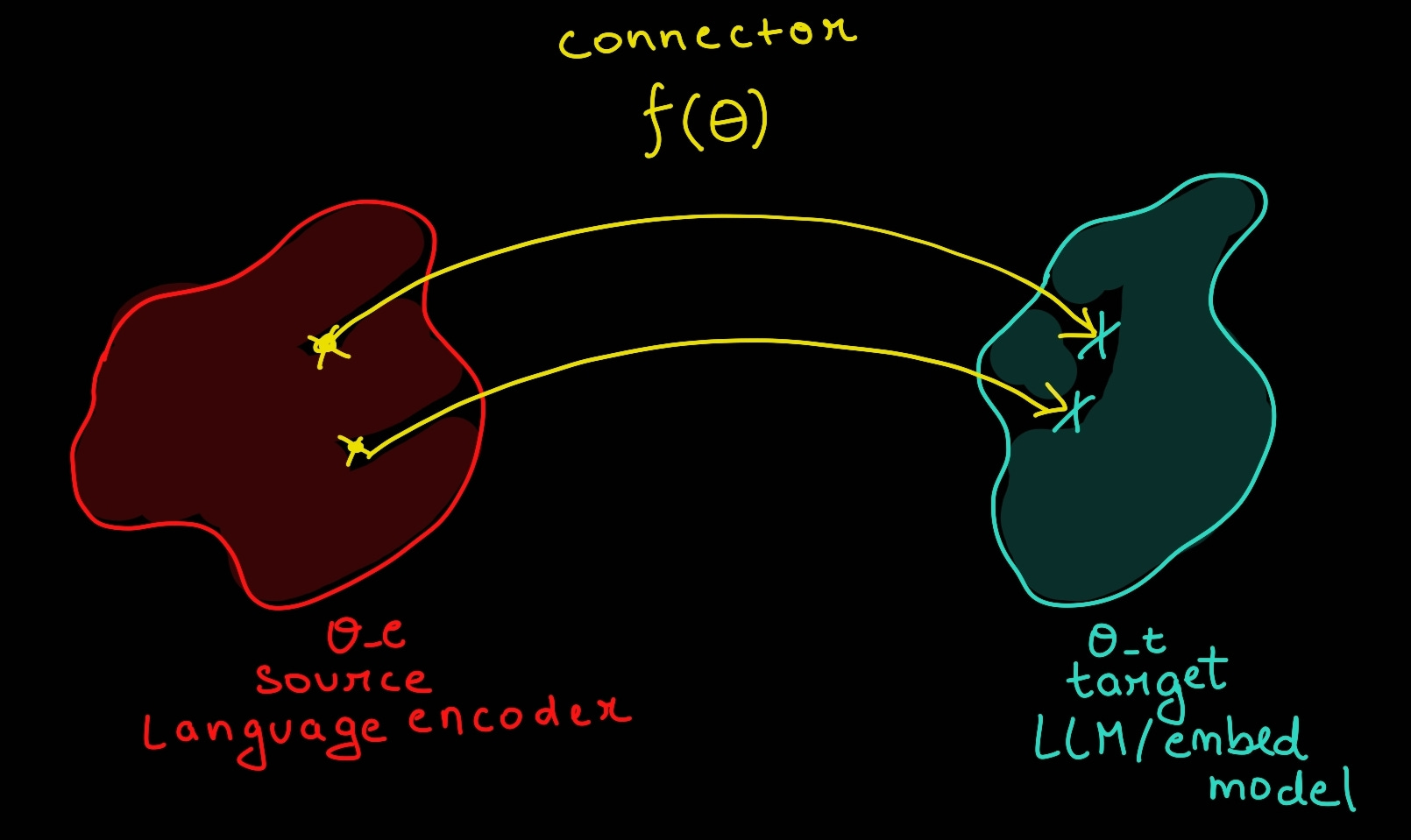
Now, we know the three components of the architecture (also evident in the image above), let's look at the training methodology for these three blocks. Authors followed a two-step process for training the architecture.
Few assumptions are made here, which serve as crux of the paper eventually and validated in the paper empirically.

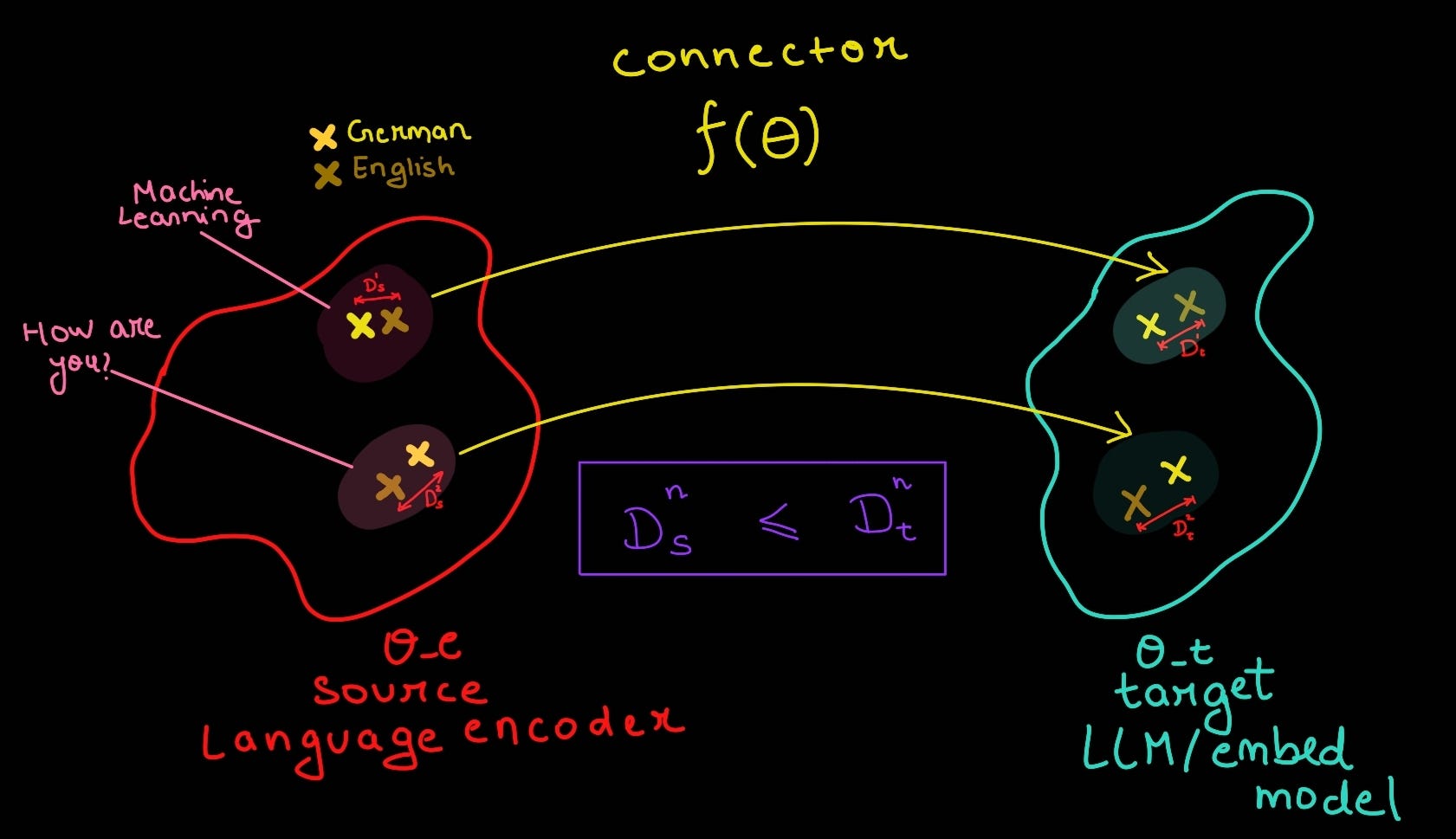
Assumption 1 : Languages have shared semantic representation space, hence, any information mentioned in two different languages should have high degree of similarity. This directly infers that semantic information across multiple language but same information is tightly clustered together.
Assumption 2 : Exploration/projection of any sample from this shared embedding space (our encoder) to the target LLM space, should mean that we can do the same for any sample/language from the same cluster and still maintain strong alignment (as the distance change is bounded). In our case the projection is performed over english language, which being the most representative sample, almost forms the cluster centre.

Though there are deeper reasons behind this which has to do with Lipschitz bound assumption2 (but let's skip this for now, and assume/trust the shared projection operation we talked about).
Alignment training:

This step involves training of our language encoder
(theta_e)and connector(theta_c)to align with target LLM representation space (this is kept frozen).
Authors followed two distinct techniques for this:Masked language modelling3: Here, authors mask out multiple section of text randomly and models task is to predict the missing sections. This objective was backbone behind the success of BERT. The reason it works so well is because the model is learning to denoise the signal/text, where masks could be considered as noise, in doing so, it learns the structure of space and hence high quality representation, for my compute vision folks, this is exactly same as that of denoising AutoEncoders.

denoised space (red colored is data). MLM performs the very same task but on sequential data (language). Check this out to understand more about MLM :
Auto-regressive completion task 4 : Given the text sequence, authors use conventional language completion task. Basically, next token prediction.
The above two objectives in conjunction to each other allow the connector and encoder to learn the projection function from source to target LLM space. How? As the target LLM is frozen, any error/loss is projected onto weight space of connector and then the encoder, hence, they get optimized to generate encoding such that it aligns well with target LLM representation space.
Representation training :
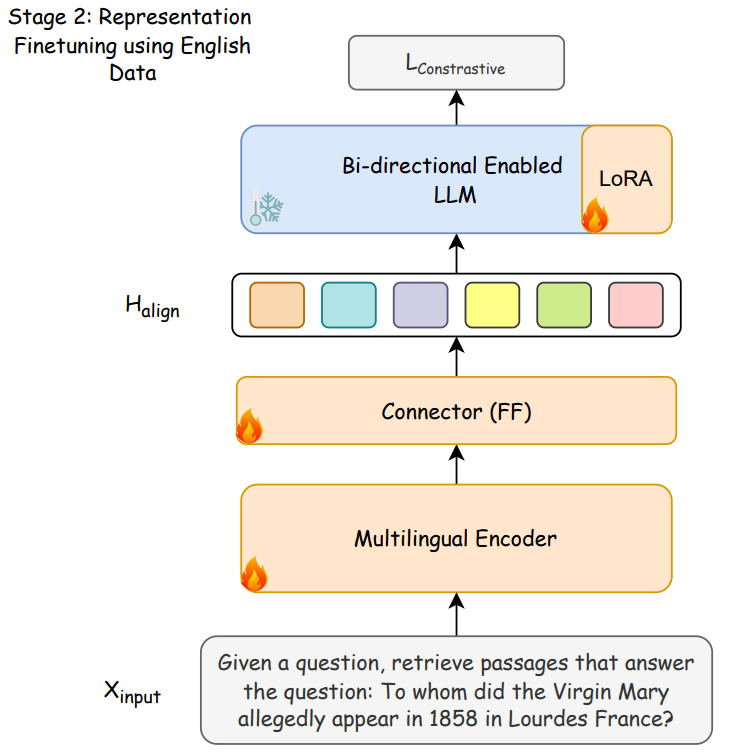
In this step, whole architecture is trained using a contrastive objective function, simply put, any information containing same info should have high similarity as score and different information should have low similarity. For this, authors did both negative in-batch sampling as well as hard-negative sampling. Also, the target LLM is trained in a bi-directionally, which improves the semantic understanding hence quality of representation of model.
In this step, Multi-lingual encoder and connector are trained completely, but, we don't want target LLM to lose any downstream performance, hence, we just tune it using PEFT5 LoRA (Low Rank adaptation). We will cover in detail about all fine-tuning methods in upcoming blogpost.




The paper also introduced new multi-lingual benchmark dataset across 5 tasks. The contribution included 123 datasets across 14 languages.

Outcome
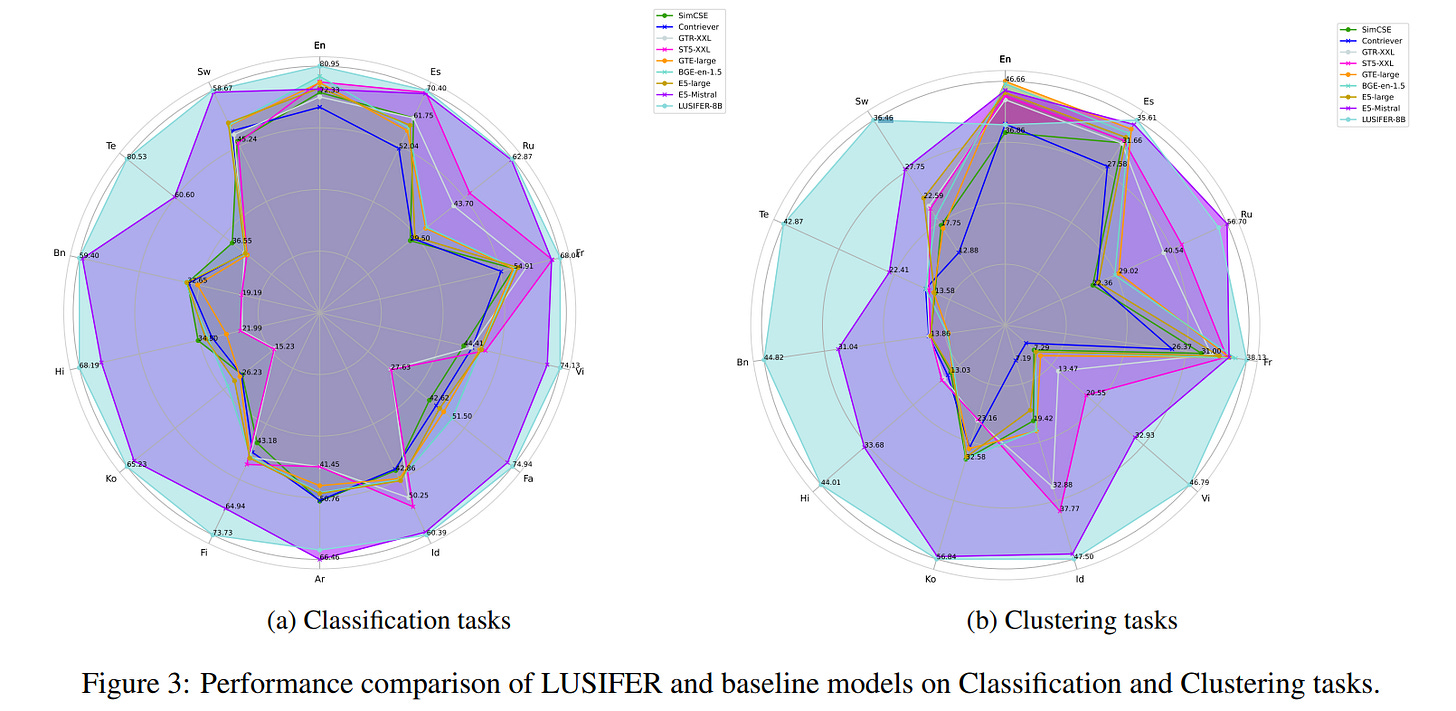
LUSIFER achieved state-of-the-art results across multiple embedding tasks (example, similarity, ranking, clustering), also, demonstrated significant improvements for medium and low resource languages.

It showed strong zero-shot multilingual capabilities, allowing task-optimized embedding models to generalize across languages without requiring explicit multilingual training data (only tuned on English variants of tasks).

By using LoRA, it delivered strong performance with minimal computational overhead, avoiding full model fine-tuning. Hence, more scalable and efficient.
Introduced a new benchmark with 5 embedding tasks, 123 datasets and 14 languages.
Demonstrated substantial performance gains (up to 15-20%) for low-resource languages, addressing the lack of robust multilingual embeddings.


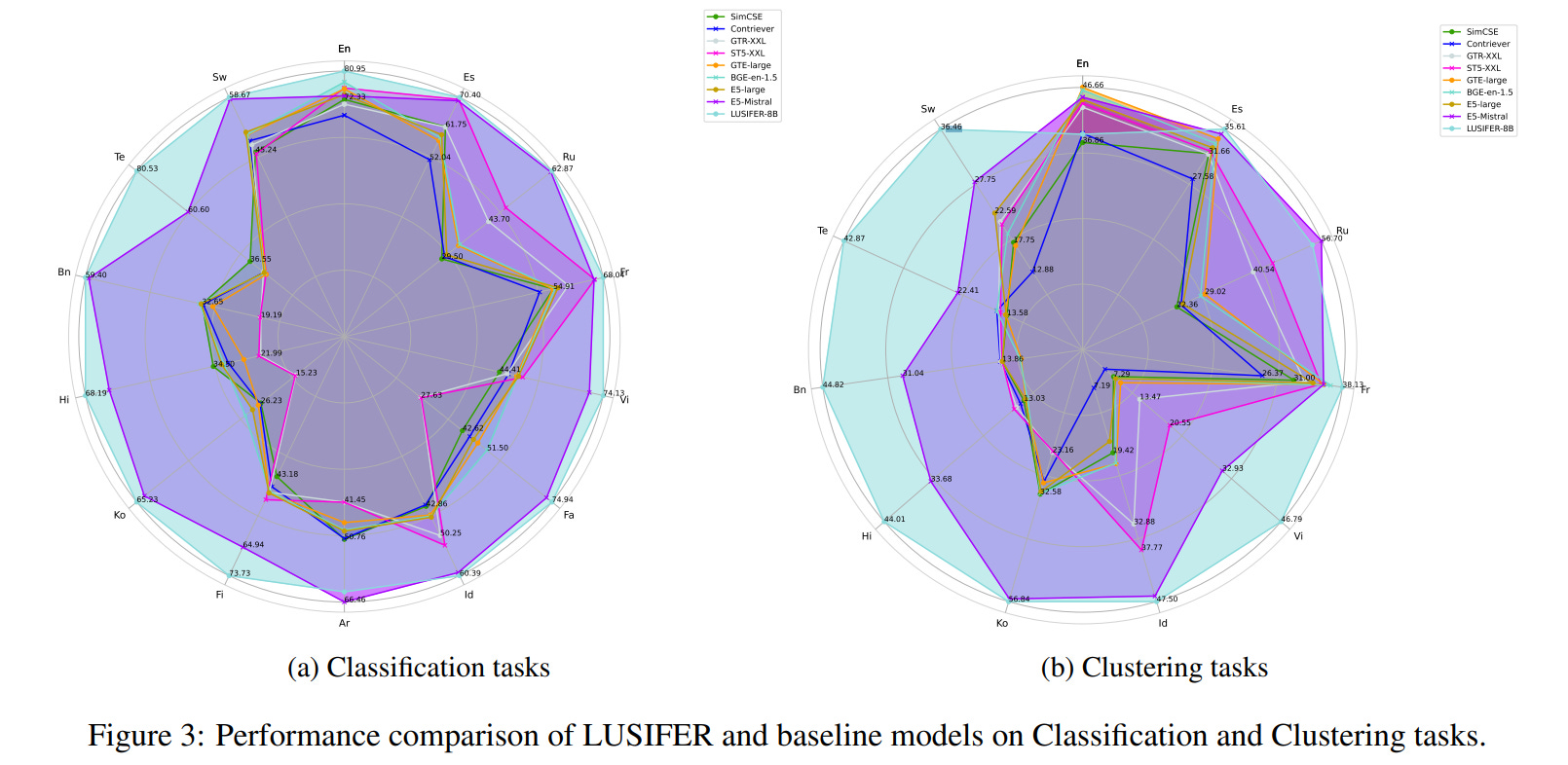
Thoughts /next steps
Usage of multilingual text encoder is a bit restrictive, as we have very less written data of low resource languages. Why not use speech models as encoders (we have more spoken data).
Using PEFT with connectors as well, and making larger connectors to accommodate for more fine grained works.
Using a contrastive loss against a translation and comparison based objective, which operates on the converted/translated embedding and predicts alignment between the English only variant vs the converted one.
What we learnt?
We explored about the issues and pitfalls of using retrieval methods for multi-lingual datasets.
We discussed possible methods around it and then talked about ideal conditions to solve the problem.
We solidified possible objective and then discussed how this is achieved by LUSIFER.
We also discussed what else we can do on top of the current pipeline (as an experiment) to make it more verbose and representative.
For more fine-grained details of ablation and experimental setup, make sure to checkout the paper : https://arxiv.org/abs/2501.00874
That's all for today.
We will be back with more useful articles, till then happy Learning. Bye👋
https://arxiv.org/abs/1911.02116
https://math.berkeley.edu/~mgu/MA128ASpring2017/MA128ALectureWeek9.pdf
https://huggingface.co/docs/transformers/main/en/tasks/masked_language_modeling
https://en.wikipedia.org/wiki/Autoregressive_model
https://huggingface.co/docs/peft/en/index