
🦙LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models🌐
Using temporal modality representation as proxy for spatial information spaces


The paper discussed in this article blurs the gap in modalities between temporal data (text) and spatial data (mesh). Paper leverages vast amount of knowledge in pre-trained models and then further fine-tuning it to understand meshes (represented in a certain format, which we will discuss in later section) .

LLMs had been on the rise given there enormous scalability and quality improvement with data and compute. This factor led to training of huge models covering a multitude of topics, frameworks and corresponding knowledge.
These architectures are further specialized to handle other modalities like spatial images (ViT) and 3D (both understanding and generation). But, as I mentioned they are specialized, which means we end up changing encoder/input handling, for example, to accomodate pixels as input, images are broken into patches and then used. The same principle could be logically extended to videos (temporal patches) and 3d data/meshes (voxels). Hence making the architecture (link between text backbone and image backbone) though connected, but disjoint. For this we need seperate training and optimization.

Next logical question is : What if we could remove this hassle and leverage the large volume of information inside LLMs directly to understand spatial information? This is where the work done in LLama-Mesh comes into picture. The framework utilizes textual representation of spatial data along with captions/text to construct an LLM that understands and is capable of generating meshes/3D objects.
Table of content
Objective
Ideal method
Methodology
Model
Input representation/Quantization
Data
Compute requirements for training
Inference
Outcome
Thoughts/future explorations
What we learnt today?
Objective
What if we could use a single framework for handling both spatial (in our case 3d specifically) and temporal data, along with a single method to handle auto-regressive mesh generation and understanding. For doing this we need a method to convert input data to a format which could be treated as a sequence or text. To put thing more concretely, we need a system which uses ONLY conventional text-to-text LLM architecture, but their output and input could be deterministically decoded into corresponding modality (without any specialized learning mechanism).
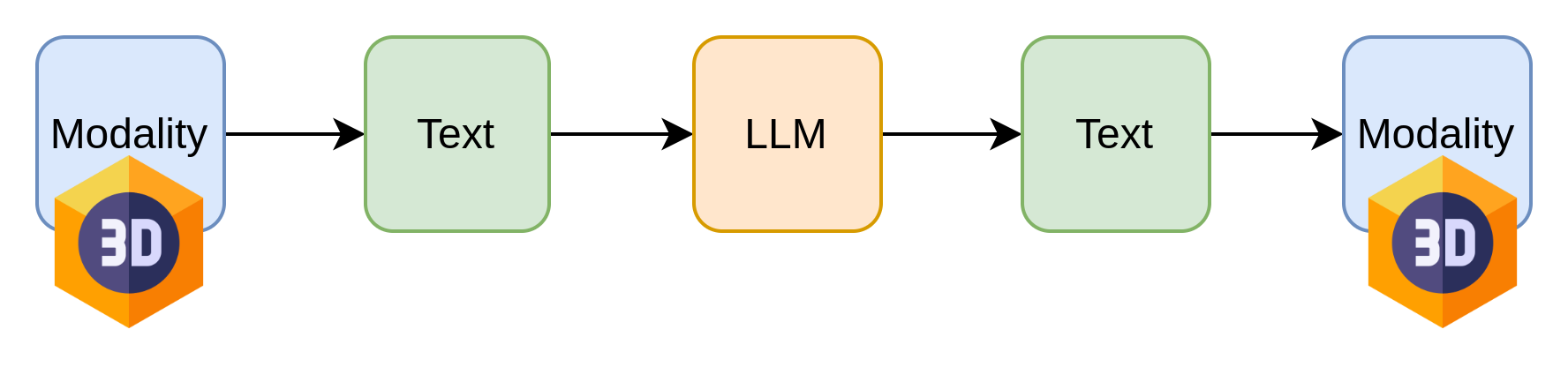
Objective summarized
A unified framework which goes from one modality to another, without any need to change the underlying model architecture.
A deterministic method to convert spatial data to temporal/sequence which could be fed to our LLM and then retrieved back.
Ideal method
Simplest way to achieve this (for any modality not just 3d mesh) is to represent everything as binary (as done in BLT1)
The ideal method would look something like:
Convert mesh/image to binary sequence.
Use the binary sequence for understanding and generation tasks.
Decode it back to corresponding format.
But, this leads to huge number of bits and eventually tokens, especially for meshes, imagine representing x-y-z coordinates (0 to 1) and color (0-255) for an object in 3d space, if you have 10,000 vertex, each is represented by a coordinate and color (let's omit opacity), then you will end up having 60,000 unique values, each if converted to binary (8 bytes each) would be 4,80,000 tokens. Now imagine the scale with floating points and opacity on a large space (with more than 100k vertexes). This could be replaced with sub-word type tokenization, but firstly, it doesn’t solve the size issue completely, secondly, how would you even represent an 3D object as parsable sequence? But, this is the only option we have for now.
Hence, the simplest way would be to use a deterministic format to get a parsable sequence, which could be understood easily without any loss of information. This leads to industry standard file formats like obj, ply and glb. Authors decided to stick with obj format as it is simpler to use, easily readable (verbose) and works well with static objects (our use-case). Each format have their respective advantages and disadvantages which could understood from the comparison table below.

But, how do we understand .obj files?

Simply put, obj files have three major components (which we should worry about w.r.t the paper), that are Vertex and Faces.
Vertex (V)
Defines the 3D coordinates of a vertex.
Format:
v x y z [w]x,y,z: Position in 3D space.w: Optional weight (default is 1.0).
Example -> v 1.0 2.0 3.0 #(x, y, z)
Faces (F)
Specifies polygons (triangles or quads) by referencing vertices and optionally normals.
Format:
f v1 v2 v3v: Vertex index.vn: Normal index (optional).
Example -> f 1 2 3 #(vertex index 1, 2 and 3 make a triangulation)Vertex Normals (
vn)Defines the direction of the surface at a vertex, used for lighting calculations.
Format:
vn x y z
Example -> vn 0.0 0.0 1.0
Now we know the objectives and background information of the standard, we are going to leverage this and dive straight into methodology followed in the paper.
Methodology
Model used is pre-trained Llama-3.1-7b-instruct which is then fine-tuned through SFT (Supervised Fine-tuning) over a synthetically generated data (discussed further).

The 3d data is used in obj format (as discussed above), it basically contains normalized coordinates for each vertex and face information for identifying connection between vertices.
These normalized values are considered as string/text and hence it becomes a simple text generation task, the only difference is instead of writing a story, it's each generated token is basically a coordinate value of an obj file (for understanding and generation both).
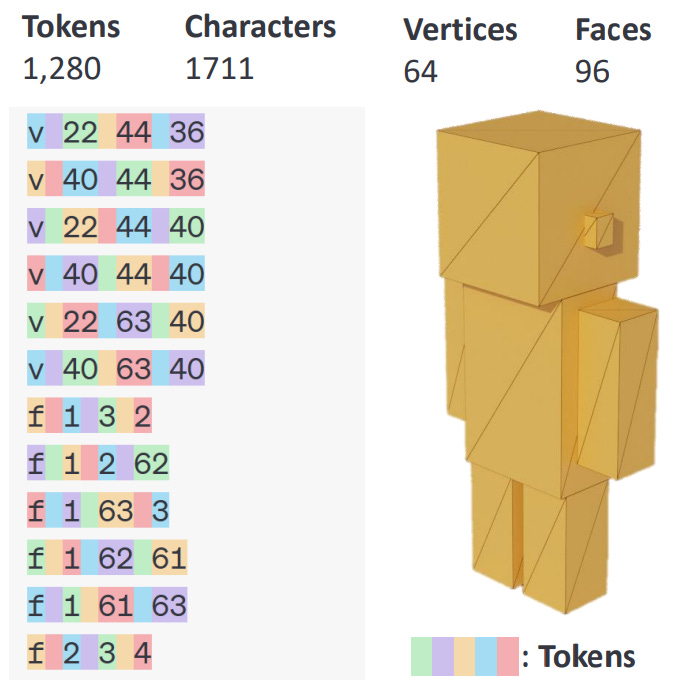
Input representation/Quantization : But, these norm values if used directly will lead to large number of tokens (due to our tokenization strategies, see the image below, decimal places would serve as characters to tokenize).

Hence, authors quantize these floating points into 64-bit integers which then could be efficiently tokenized. Process for quantization and dequantization:
Let's say we are doing 4-bit quantization, first of all, we make a 16 length (2^4 level) array, filled with evenly spaced value between (-1,1).
The input value which is already normalized, is matched against the closest value in level array above.
The index of closest element is taken as the final value (which is a integer).
The dequantization process is exact opposite, the predicted integer index is taken and corresponding value is fetched and used as norm value.

Quantization and de-Quantization from QLoRA explanation by AIBytes (check references below) Special tokens : <start of mesh> and <end of mesh> used to signal mesh information to model.
Data
The data is synthetically generated from objaverse and is composed of 500 faces and total 31k meshes.
Each extracted mesh is rotated by
{0°, 90°, 180°, 270°},hence generating a total of 125K mesh.For retrieving description of mesh, Cap3D2 is used. Hence, we have (mesh, description) pairs, this could be used for to-and-fro training (text to mesh) and vice versa.
Data is composed into two parts, Rule based and LLM augmented (check image below), simply put it's datapoint with single question vs chat. The dataset contains 40% mesh generation, 20% mesh understanding and 40% understanding-generation conversation samples.

Compute requirements for training : The model is trained over these datapoint pairs and is optimized through generic temporal loss over 32 A100 GPUs for 21k iterations, which took around 3 days on batch size of 128.
Inference : During Inference, for mesh understanding, the model is fed with quantized .obj file text sequence, which is then described by the model, whereas for mesh generation, it expects a prompt with required instructions and generates a quantized sequence of string (vertex and faces) which is then de-quantized and could be saved as .obj file (hence could be visualized; as seen below).

LLAMA-MESH achieves several new tasks, including mesh generation and understanding, while completing other tasks like the original LLM.





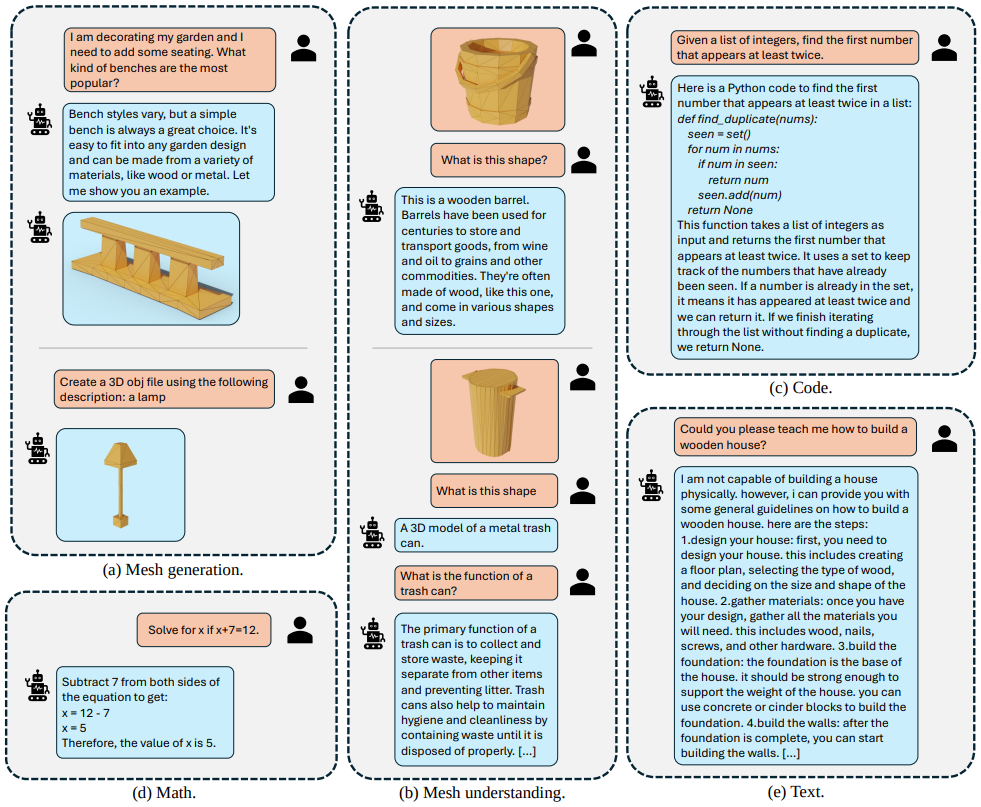
Outcome
An unified model for mesh understanding and generation
Model is able to retain much of training data without facing major catastrophic forgetting.

Proposed method (in the blue column), after being fine-tuned to generate OBJ files, maintains language understanding and reasoning capabilities comparable to the base model while extending its functionality to 3D mesh generation.

Thoughts/future explorations
Quantization leads to information loss on resolution scale, could this be improved through better data types like bfloat.
SFT leads to forgetting information, could this be replaced with QLoRA.
Trying out the idea with smaller Language models specially trained for structured data.
What we learnt today?
LLMs inherently have fair sense of understanding of spatial structure of datapoints/objects, hence with some fine-tuning they were able to project latent representations onto usable space (in our case .obj format).
For any modality if we are able to represent it into parasable and readable textual/sequential format, LLMs would be able to handle them and leverage the dense knowledge representations to form correlation between our use-case and their latent space.
A stronger tokenization strategy is required here for more precise input representation, as we saw quantization kills a lot of information, hence, not a good choice for high resolution tasks.
Most importantly, just by using synthetic data, a model could be fine-tuned to map the synthetic input space onto real world learnt/latent space, it means model can be trained on large real data and then we can iteratively tune on smaller synthetic/specialized data without any need of further manual annotation. This opens a lot of scope for iteratively making model more robust (anyways this is a common trend for most of the new generation LLMs, but, in my understanding has been done for the first time on 3D meshes).
For further nuances and details, please go through the paper here :
https://arxiv.org/abs/2411.09595
That's all for today.
We will be back with more useful articles, till then happy Learning. Bye👋
https://cap3d-um.github.io/