
RPT : Reinforcement Learning during Pretraining
Making RL (RLHF/RLVR) part of Alignment Tuning step is one of the major reasons for recent development in LLM, but, what if we do do the same during Pre-training stage itself

Table of content
Introduction
Pre-training vs. Alignment Tuning
Pre-training: Quantity over Alignment
Alignment Tuning: Quality over Quantity
Reasoning : Re-visit
Why Reasoning is So Important?
Methods to Introduce reasoning in LLMs
Output/Inference level : CO-X family
Architecture level : Continuous Thought Machines
Objective level : Using Rewards to model Reasoning (RLVR)
Emergent Reasoning through Reinforcement
But, Why embed reasoning during pre-training?
The Ideal Case
Methodology: Reinforcement Pre-Training (RPT)
Experiments/Results
Thoughts
Conclusion
1. Introduction
If there’s one single factor that has fundamentally changed the way we think about AI today, it’s the rise of large language models (LLMs). They’ve gone from academic curiosities to industrial workhorses, redefining how we build applications, communicate, and even reason.
But what exactly led us here? It wasn’t just more data or bigger GPUs, but, the way training pipeline was designed. It was the multi-stage training recipe that crystallized over the past few years, a pipeline where we first expose models to massive oceans of raw text, and then carefully refine their behavior through alignment and reasoning-focused techniques.
This staged design is not just an engineering hack. It reflects a deeper truth about intelligence itself:
At scale, pre-training gives models the breadth of knowledge; hence, they can talk about almost anything. Pre-training is like throwing the model into an ocean of text. The goal here is mode covering; the model must learn to spread its probability mass across the full variety of natural language patterns. Think of it as teaching the model to “cover all bases,” whether it’s Shakespeare, StackOverflow, or social media slang.
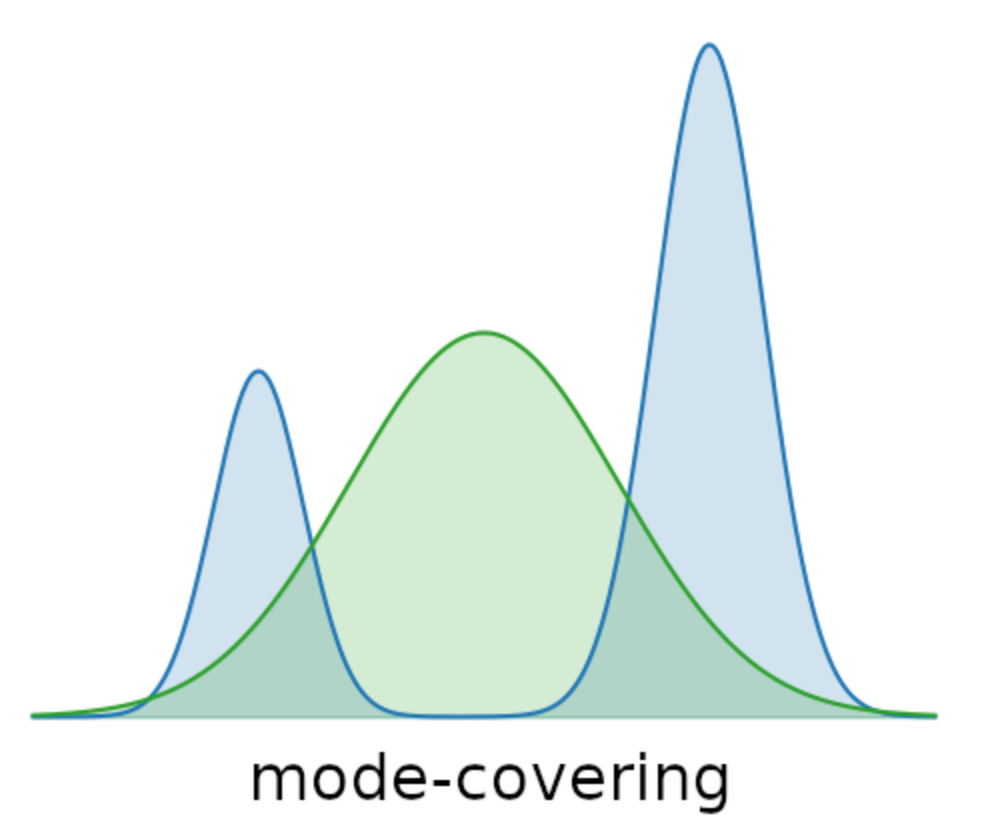
But alignment tuning gives them the depth of usability, they can talk the way we want, follow rules, and even reason. Alignment tuning flips the script. Now, instead of covering all modes, we want mode seeking, which simply is steering the model toward the “human-preferred” parts of its distribution.
Why is this multi-stage approach so important? Because pre-training alone leaves us with stochastic parrots; knowledgeable but ungrounded. Alignment alone would starve the model of diversity. By combining mode covering (breadth) with mode seeking (focus), they strike the balance between coverage and control, between capability and reliability.
And now, with the idea of Reinforcement Pre-Training (RPT), researchers are asking: what if reasoning itself could be baked into the earliest stages of model training, rather than patched in later through alignment?

This is where the story begins.
2. Pre-training vs. Alignment Tuning
The beauty of modern LLMs is that they rely on two distinct but complementary training phases. Each has its own philosophy, trade-offs, and compute requirements. Understanding this split is crucial if we want to see why reinforcement pre-training (RPT) is such a big deal.
 for Language Models")
Pre-training: Quantity over Alignment
Pre-training is all about coverage. The model is fed trillions of tokens (books, web text, code, papers) not because all of it is clean or directly useful, but because the sheer quantity ensures that the model captures a broad distribution of language and knowledge.
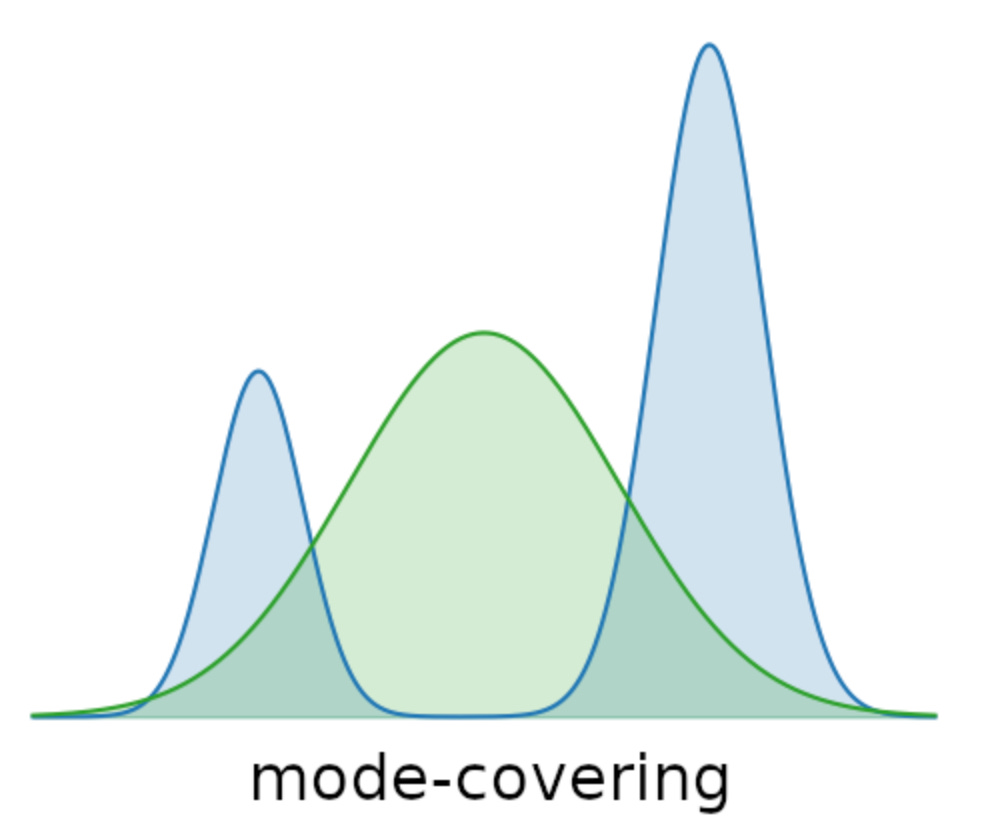
This stage is mode covering: the model learns to span as many possible regions of semantic space as it can, even if the alignment to human intent is weak. The trade-off? It’s compute-hungry. Because autoregressive training is Markovian (each token depends only on the history so far), learning is inherently inefficient; the model essentially stumbles its way through sequence space, one step at a time. But the upside is coverage at scale: the model sees everything.
Method: Autoregressive training (predict the next token). While effective, this is inherently Markovian (the model only sees one step ahead at a time). This makes learning slow and inefficient, since each new token depends on recomputing context.
Pre-training builds raw competence, but doesn’t inherently produce useful reasoning or alignment with human goals. Think of this as laying the foundation: broad, heavy, and computationally expensive.
Alignment Tuning: Quality over Quantity
Once the model has been pre-trained, we move to the alignment stage. Here the dataset is much smaller, but richer in human preference signals. Alignment tuning is all about precision/mode seeking.
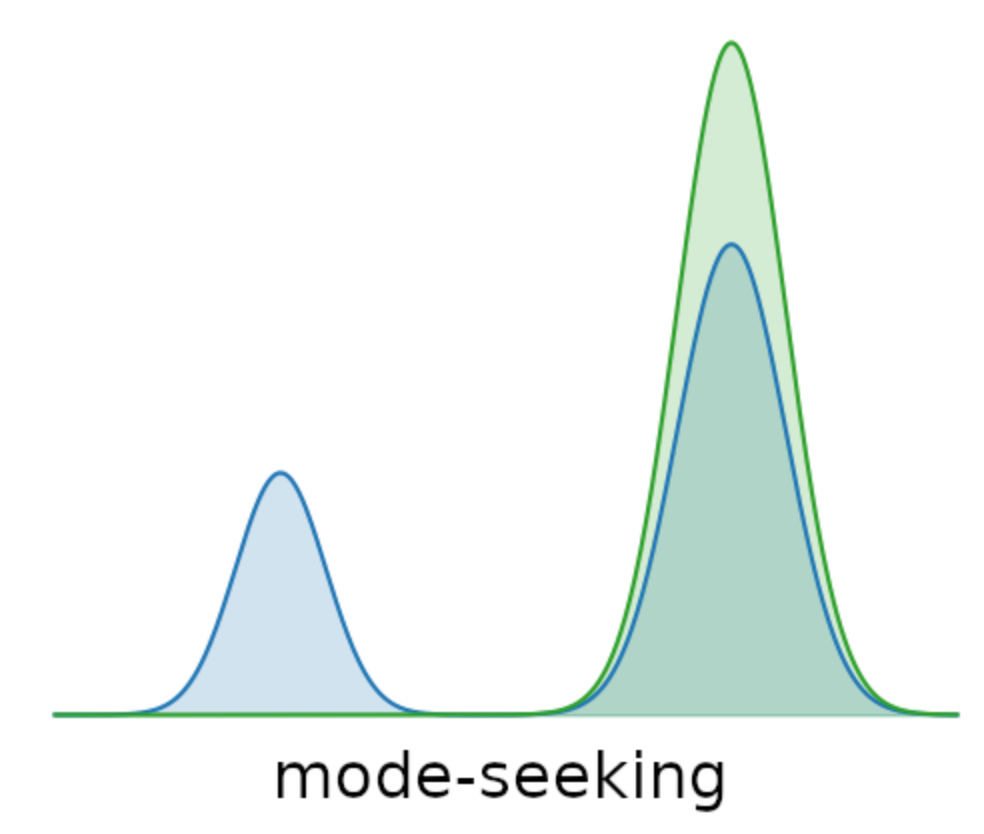
Here, instead of throwing billions of messy sequences, we feed it carefully curated, human-annotated, or preference-driven data. Reinforcement learning from human feedback (RLHF), Direct Preference Optimization (DPO), or instruction tuning are examples. This stage is mode seeking: the model is nudged toward the “good” parts of its knowledge (truthful, helpful, safe, task-specific, etc.) while suppressing the undesirable behaviors. Unlike pre-training, the dataset here is small, but each example carries far more weight because it encodes alignment, not raw coverage. Methods include:
Supervised Fine-Tuning (SFT): Train on curated input–output pairs (e.g., “Ques: What is photosynthesis? Ans: …”).
Reinforcement Learning with Human Feedback (RLHF) or RLAIF: Use preference comparisons to fine-tune behaviour (either through human prefernece or using a oracle/capable model as reference).
Since data is limited, alignment tuning can only “reshape” the model’s prior distribution, not completely override it. Hence, This is the polishing phase: light in compute compared to pre-training, but transformative in how the model interacts with us.
The Trade-off: Compute vs. Knowledge
Here lies the tension:
Pre-training is compute-heavy but ensures vast knowledge.
Alignment is data-expensive (since human feedback is costly) but gives usability.
That said, now let’s quickly understand why reasoning while learning is so important?
3. Reasoning : Re-visit
One of the biggest lessons from the LLM journey so far is that knowledge ≠ reasoning (knowing is not understanding). A model can memorize trillions of tokens, yet still fail at tasks that require multi-step logic, planning, or abstraction. This is why reasoning has become the holy grail of LLM research not just knowing facts, but using them effectively.
Why Reasoning is So Important?
Reasoning is more than a convenience; it changes what LLMs are capable of:
Generalization/Adaptability: A model that reasons can adapt to novel problems, rather than regurgitating memorized answers.
Abstraction: Reasoning lets models manipulate symbolic structures (math, logic, planning) instead of just surface-level text.
Reliability: Without reasoning, outputs can look fluent but be fundamentally wrong (hallucination).
Put differently: reasoning is alignment’s natural companion. Pre-training gives raw breadth, alignment makes models safe, but reasoning makes them useful (and to certain extent, less prone to Hallucinations).
Methods to Introduce reasoning in LLMs
LLMs are not just parrots of language, their real power emerges when they reason. Reasoning is what allows a model to go beyond shallow token prediction and instead chain together ideas, steps, and constraints toward a solution. Over time, researchers have explored different ways of teaching LLMs to reason:
The CO-X Family of Reasoning Methods (Output/Inference level)

Over the years, researchers have proposed a series of strategies, often nicknamed “CO-X” methods; to make language models reason more effectively by shaping how they generate text. These don’t fundamentally change the model’s architecture; instead, they reframe reasoning as a formatting or decoding trick layered on top of autoregressive prediction.
Chain of Thought (CoT): The simplest and most widely used. Here we ask the model to “think step by step,” nudging it to output intermediate reasoning before producing an answer. The magic is not in deeper intelligence, but in format: the model has seen plenty of stepwise patterns during training, so mimicking them improves math, logic, and multi-hop tasks.
Chain of Reasoning (CoR): A natural extension of CoT. Instead of just writing steps, the model learns to plan: breaking problems into sub-goals, deciding which tools or functions to invoke, and tracking rationale across turns. CoR makes LLMs act more like planners, though still inside the sequential token-prediction pipeline.
Continuous Chain of Thought (COCONUT): A newer refinement. Instead of discrete jumps between reasoning steps, COCONUT smooths the process into a continuous trajectory in latent space. Each partial thought blends into the next, shaping a vector-valued reasoning path rather than a list of sentences. This hints toward architectures that treat reasoning as a fluid, evolving process, a direction later explored by Continuous Thought Machines (CTMs).
In short, the CO-X methods all share the same intuition: if reasoning is hard to encode directly, make the model simulate it through carefully designed generation patterns. CoT does this with discrete steps, CoR with planning and tool use, and COCONUT with continuous latent flows.
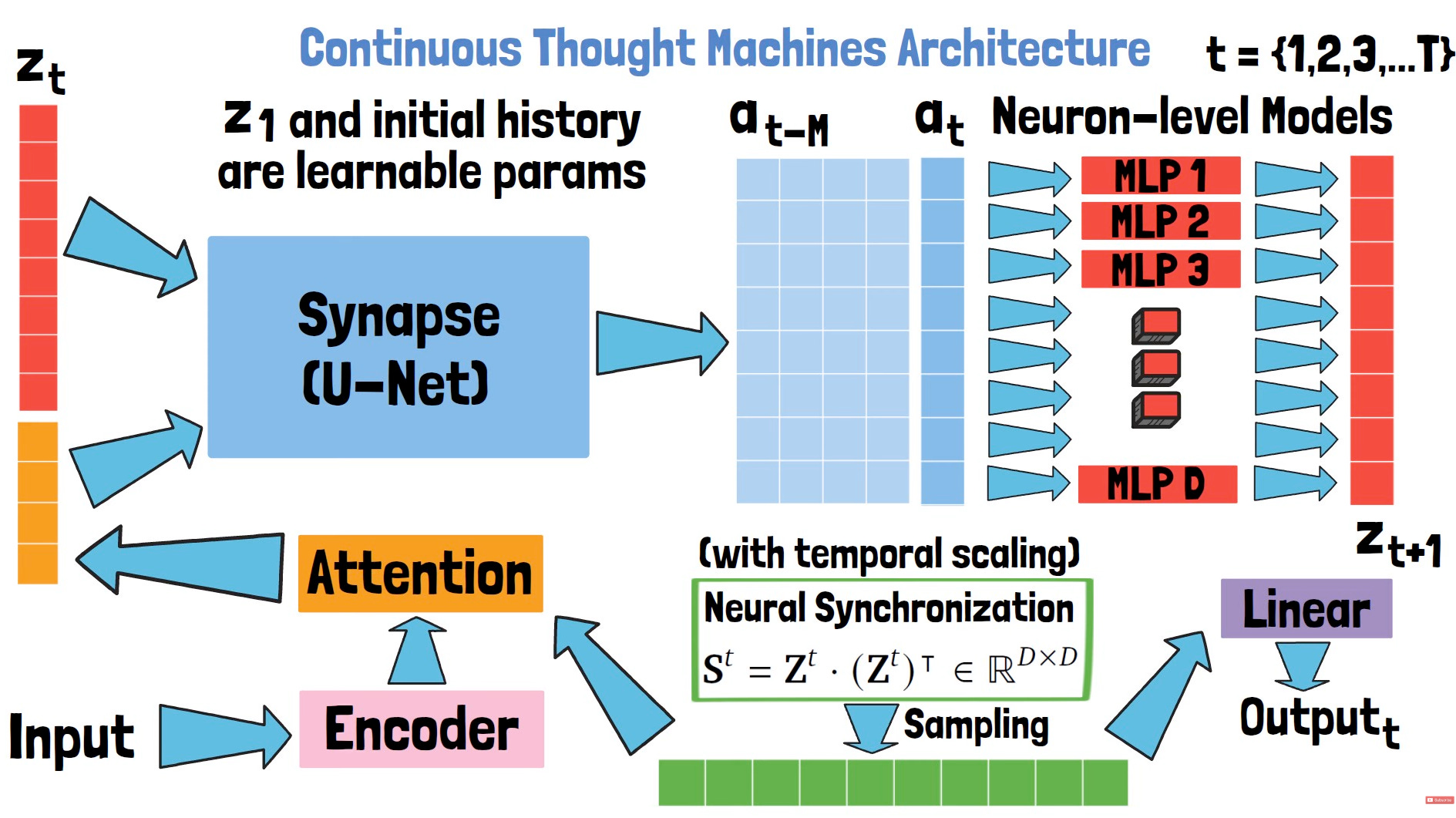
Continuous Thought Machine (architecture level)
Imagine if a transformer didn’t allocate the same compute to every token, but instead spent more time thinking on hard parts and less on trivial ones. That’s the idea here: dynamic compute allocation across time. For complex tokens or key reasoning steps, the model loops longer (more “ticks”), while for easy fillers it moves faster. The result is efficiency without sacrificing depth, by giving more brains (compute/ticks) where it matters.
Using Rewards to model Reasoning (RLVR) (Optimization Level)
Works like DeepSeek takes reasoning one step further by showing how reinforcement learning with variable rewards (RLVR) can induce reasoning as an emergent behavior. Instead of treating language generation as a greedy, one-step lookahead problem (predict the most likely next token), DeepSeek reframes it as pathfinding in a vast semantic space. The model isn’t just rewarded for correct final answers, it’s rewarded for following useful intermediate reasoning steps. Over time, this shifts its behavior from shallow token mimicry toward deeper exploration: searching multiple steps ahead, weighing alternative paths, and converging on structured solutions.
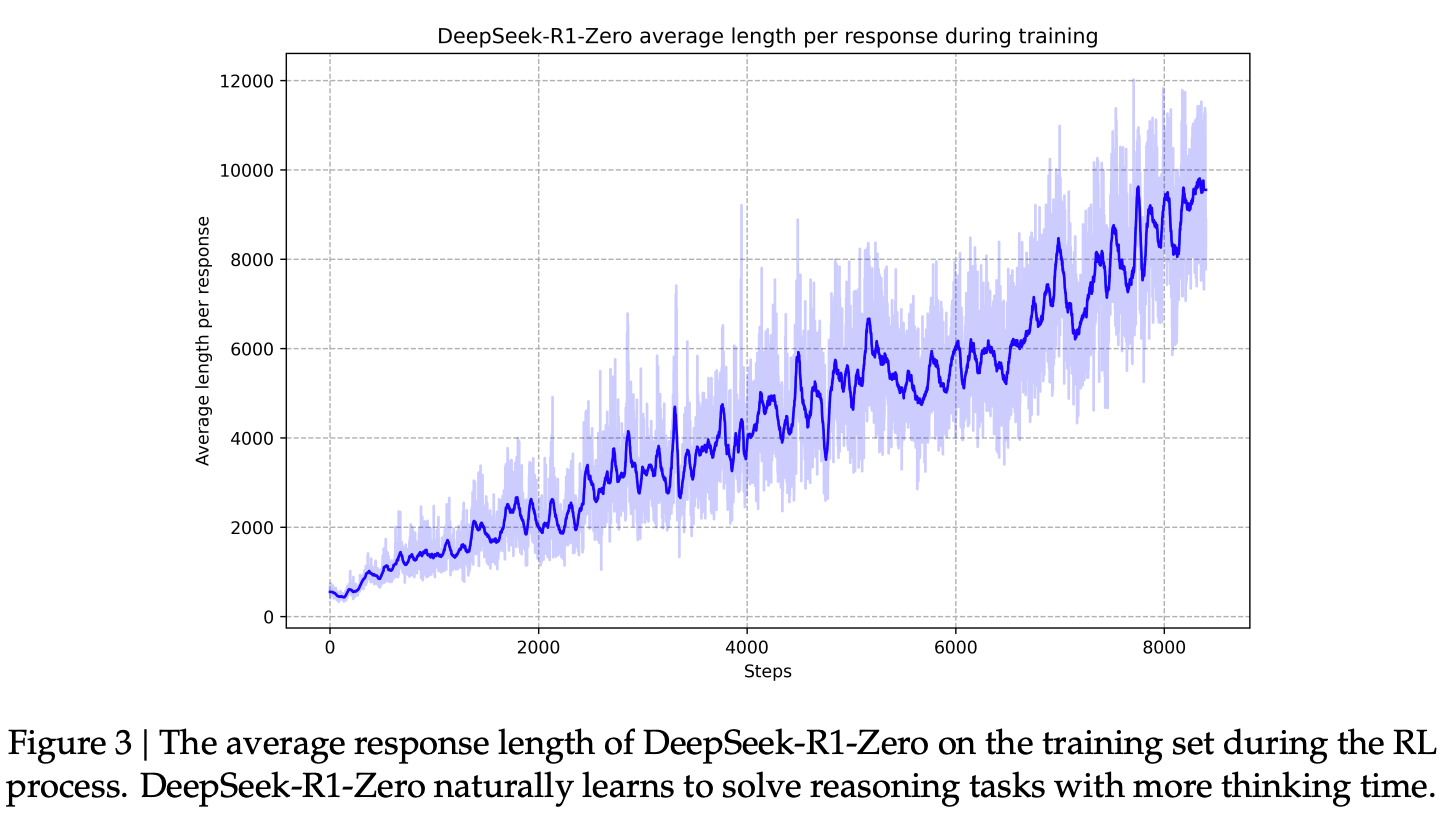
At its core, all these methods push LLMs toward a simple but profound shift: from predicting the next word to constructing a reasoning trajectory. But, methods like CoT, CoR and COCONUT are mostly targeted towards inference or Alignment tuning, whereas CTMs is a different way of architecture design for the reasoning process. RLVR is the only place where reasoning is baked in as an optmization task, which is the closest thing to the paper we are eventually going to discuss. The only problem with RLVR in case of DeepSeek is that its applied at alignment tuning step again; and this is where a very important question emerges; can we do RLVR at pre-training stage itself?
Emergent Reasoning through Reinforcement
Language Generation as Pathfinding
Text generation can be seen as navigating a massive search space of tokens. In plain autoregression, the model performs a greedy one-step lookahead, hence, picking the most probable next token given history. This works for fluency, but fails for planning or multi-step problems. RL changes the picture: instead of scoring tokens locally, it evaluates entire sequences with rewards. Generation becomes a k-step search problem, where trajectories are explored and shaped by feedback. This shift from local greediness to global exploration is the seed of reasoning.Variable Rewards Drive Multi-Step Patterns
The magic lies in non-uniform rewards. A model isn’t just told “right or wrong”; it learns how good one trajectory is relative to others. For example, in math tasks: low reward for just outputting the answer, medium reward for partial reasoning, high reward for complete step-by-step logic. Over time, the model internalizes that multi-step reasoning sequences yield the highest payoff, pushing it to simulate planning ahead instead of predicting shallow token continuations.Emergence of Structured Computation
Why does this look like reasoning? Because RL adds long-horizon credit assignment: success at the end (correct solution, coherent explanation) backpropagates to earlier token choices. This forces the model to form internal chains of computation rather than surface-level co-occurrences. Effectively, RL transforms generation from shallow local sampling into approximate global search. What emerges isn’t hard-coded logic, but structured token trajectories that mirror human reasoning.
But, Why embed reasoning during pre-training?
Scale is wasted without structure
Pre-training is where the model sees most of its data. If this stage only teaches shallow token correlations, then billions of tokens are essentially used for memorization. By embedding reasoning here, we exploit scale to learn semantic relations and causal patterns early, rather than trying to patch them later with small alignment datasets.Makes downstream alignment easier
Alignment tuning is compute-light and data-light compared to pre-training. If reasoning is already seeded in the pre-training stage, then alignment only needs to polish and guide it; instead of “retro-fitting” reasoning onto a model that never internalized it. This lowers the burden of reinforcement tuning and improves sample efficiency.Balances breadth and depth
Pre-training is designed for mode covering (breadth of knowledge), while alignment is more mode seeking (depth of reasoning on specific tasks). By embedding reasoning into pre-training, we bridge this gap: the model doesn’t just cover text distributions but also learns how to navigate within them. This dual optimization makes models both knowledgeable and capable of structured inference.
4. The Ideal Case
Let’s imagine a world where compute and token cost don’t matter, the only question is: how much semantic richness can we bake into pre-training itself?
Pre-training with rich features
Suppose the pre-training corpus is not just noisy internet text, but sufficiently rich in semantic relations, logical patterns, and contextual depth. Even if it’s not as specialized as alignment datasets, the raw scale and diversity of pre-training would make it the natural place to exploit these relations.Reasoning built in, not patched later
If we can capture those semantic connections during pre-training, then reasoning doesn’t need to be retrofitted through expensive alignment steps. Instead, the vast number of pre-training samples already train the model to build internal structures of logic and inference. Alignment tuning then becomes polishing rather than overhauling.Mode covering and mode seeking
With unlimited compute, we no longer face the tradeoff between breadth (mode covering, absorbing all of human text) and depth (mode seeking or drilling into reasoning patterns). The model could do both: cover the space broadly, while also converging on reasoning-rich optima.Proxy supervision, not labels
Of course, we don’t want to label billions of pre-training samples. Instead, we use the generation task itself as a proxy, reinforced through something like Reinforcement Learning with Variable Rewards (RLVR). This lets the model learn to prefer semantically consistent and reasoning-rich continuations even without explicit annotation.
In this ideal setup, the boundary between pre-training and alignment tuning blurs. Pre-training already aligns the model toward reasoning, while alignment only sharpens the edges. Reasoning isn’t an emergent afterthought; it’s a first-class citizen from the very beginning of training.
5. Methodology: Reinforcement Pre-Training (RPT)
At the heart of RPT lies a simple but powerful idea: instead of just predicting the next token directly, the model is asked to reason about it first. This turns ordinary language modeling into a two-step process : think → then predict.
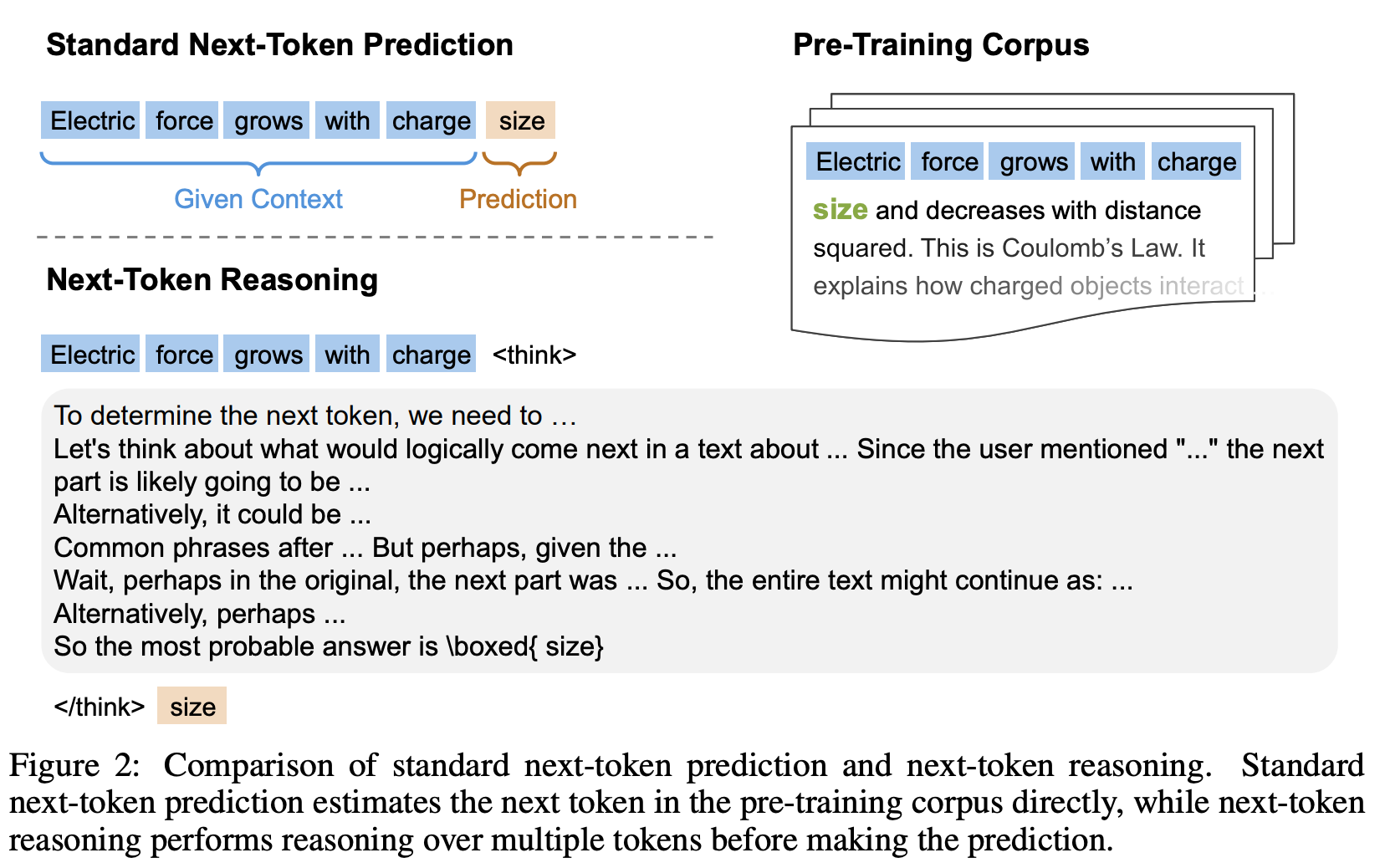
1. Next-Token Reasoning Task
Traditionally, pre-training is defined as: given an input sequence x0,x1,…,xT at each position t, the model sees the prefix x<t as context and predicts the next token xt.
In RPT, we extend this setup. For every context x<t:
The model π_θ must first generate a reasoning sequence, denoted c_t. This can look like brainstorming, self-critique, or step-by-step derivation.
Only then does it output the final prediction yt.
Formally, the output at each step is:
This seemingly small change completely reframes pre-training. Instead of treating the training corpus as just token-level correlations, we reinterpret it as a massive collection of reasoning problems. Every next-token prediction now hides an implicit reasoning chain and the model is trained to surface it.
2. On-Policy Reinforcement Learning
To train this behavior, RPT uses on-policy reinforcement learning. For each context x<t, the model is asked to produce not one but G candidate reasoning trajectories/Rollouts:
Each trajectory consists of:
c_t^i: the chain-of-thought reasoning.
y_t^i: the final prediction for the next token.
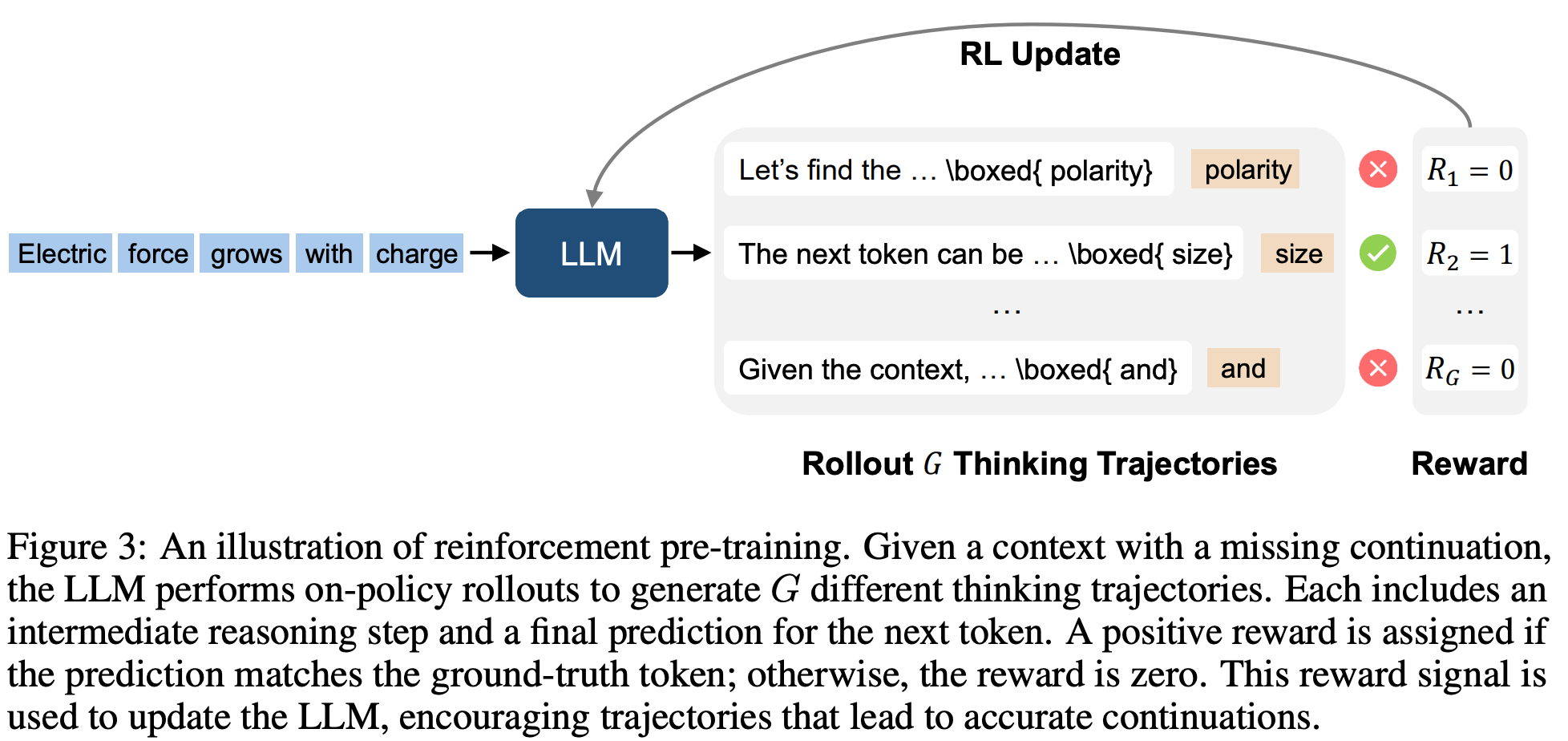
So rather than committing to a single guess, the model explores multiple possible reasoning paths/Rollouts (much like brainstorming before giving a final answer).
3. Prefix-Matching Reward
How do we know which predictions are correct?
Here comes the clever part: RPT introduces a prefix-matching reward.
Suppose the true continuation of the sequence is x≥t.
The model’s prediction y_t^i is evaluated at the byte level (not just token level).
The prediction gets a reward of 1 if it exactly matches the prefix of the ground-truth continuation and ends at a valid token boundary. Otherwise, reward is 0.
Formally:
where l is the byte-length of the prediction and Lgt is the set of valid ground-truth boundaries.
Why this matters:
It allows us to verify predictions that span multiple tokens (e.g., multi-character words, subwords).
It works even when predictions involve out-of-vocabulary tokens.
Most importantly, it gives clear and strict feedback: either the path aligns with the ground truth (reward = 1) or it doesn’t.
4. Optimization Objective
Finally, the model is trained to maximize expected/average reward across all contexts and generated candidates (the authors went with GRPO formulation here):
Here, D is the dataset of all prefixes.
Intuitively:
The model explores many reasoning + prediction paths.
It gets rewarded only when the final prediction is a valid prefix of the true continuation.
Over time, this forces the model to internalize reasoning strategies that consistently lead to correct completions.
5. Pre-Training Setup
Dataset: OmniMATH
For reinforcement pre-training, the authors use the OmniMATH dataset
It contains 4,428 competition-level math problems and solutions, collected from trusted sources like AoPS Wiki and AoPS Forum.
Why math? Because math naturally demands multi-step reasoning and has objective correctness, making it an ideal testbed for reinforcement-driven reasoning.
Token-Level Data Filtering
Not all tokens in math solutions are equally challenging. For example:
Tokens like “=” or “+” are trivial to predict.
But key numbers, symbols, or intermediate steps require true reasoning effort.
To filter training data accordingly, they use a clever proxy step:
A small model, DeepSeek-R1-Distill-Qwen-1.5B, is used to measure token-level difficulty.
For each token, they compute the entropy of the model’s prediction distribution over the top-16 candidates.
Low-entropy tokens (easy predictions, model very confident) are discarded.
High-entropy tokens (uncertain predictions, more reasoning required) are prioritized.
This ensures the training focuses compute on the hardest parts of math reasoning instead of wasting cycles on trivial completions.
Base Model and Framework
For the Base model, authors used DeepSeek-R1-Distill-Qwen-14B. Chosen because it already has basic reasoning capabilities, making it a good starting point for reinforcement learning with GRPO (Group relative policy optimization).
RPT essentially lifts next-token prediction into the reasoning space through its formulation as an optimization task via RL. Now, as seen in image below RL is not just the “cherry on cake” (usage during Alignment tuning); but, now its part of each step, hence, a superset (or the cake itself).
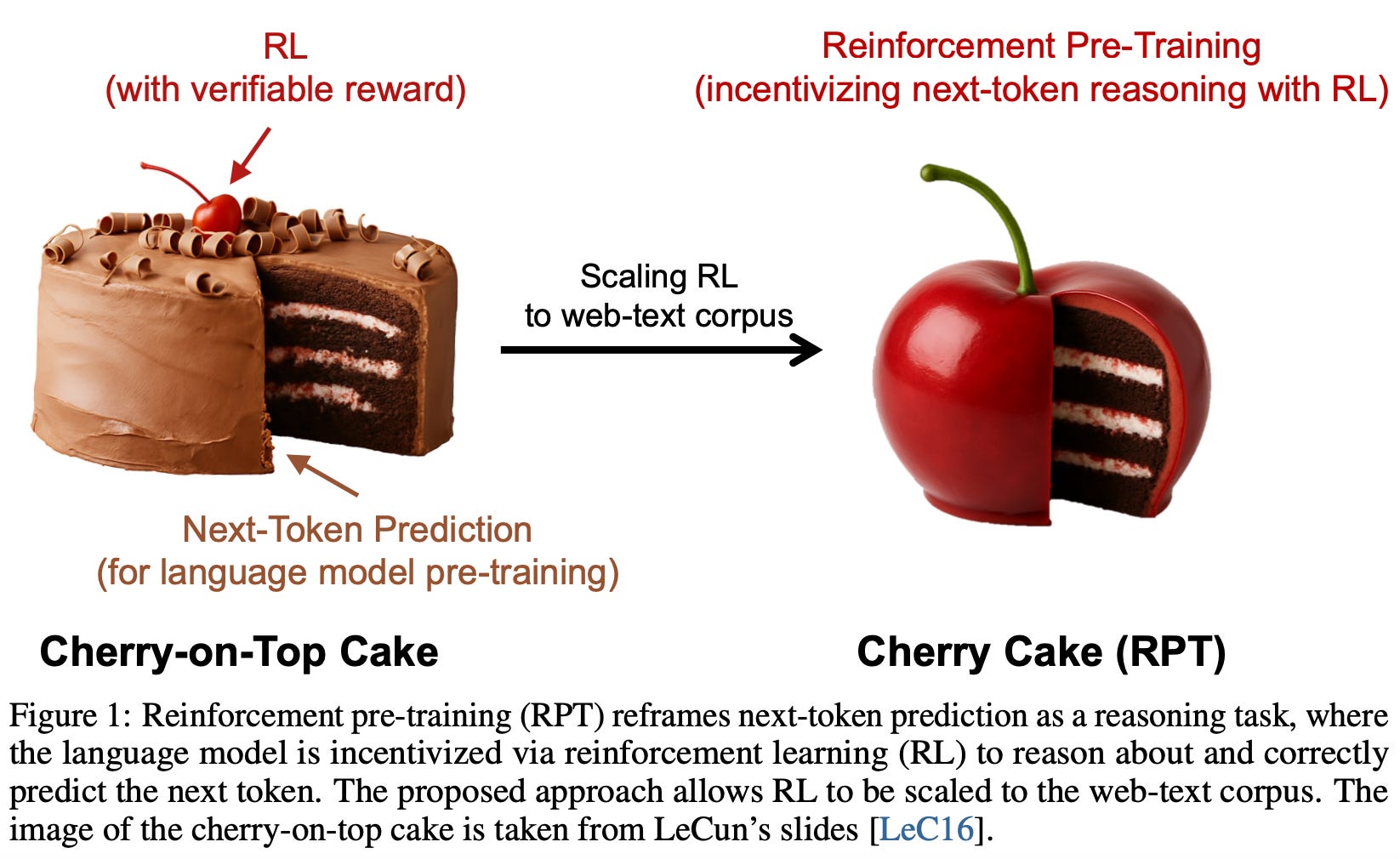
Hence, instead of correlating tokens one by one, the model learns to plan ahead: “what reasoning path is most likely to land me at the right next token?” By combining exploration (multiple trajectories) with strict rewards (prefix matching), it makes reinforcement learning scale naturally to the pre-training stage.
6. Experiments

The experiments are structured to answer one central question: does Reinforcement Pre-Training (RPT) actually improve reasoning and language modeling beyond conventional next-token prediction? To do this, the authors evaluate across multiple fronts like core language modeling, scaling properties, reinforcement fine-tuning, zero-shot generalization, and reasoning pattern analysis.
1. Language modeling setup
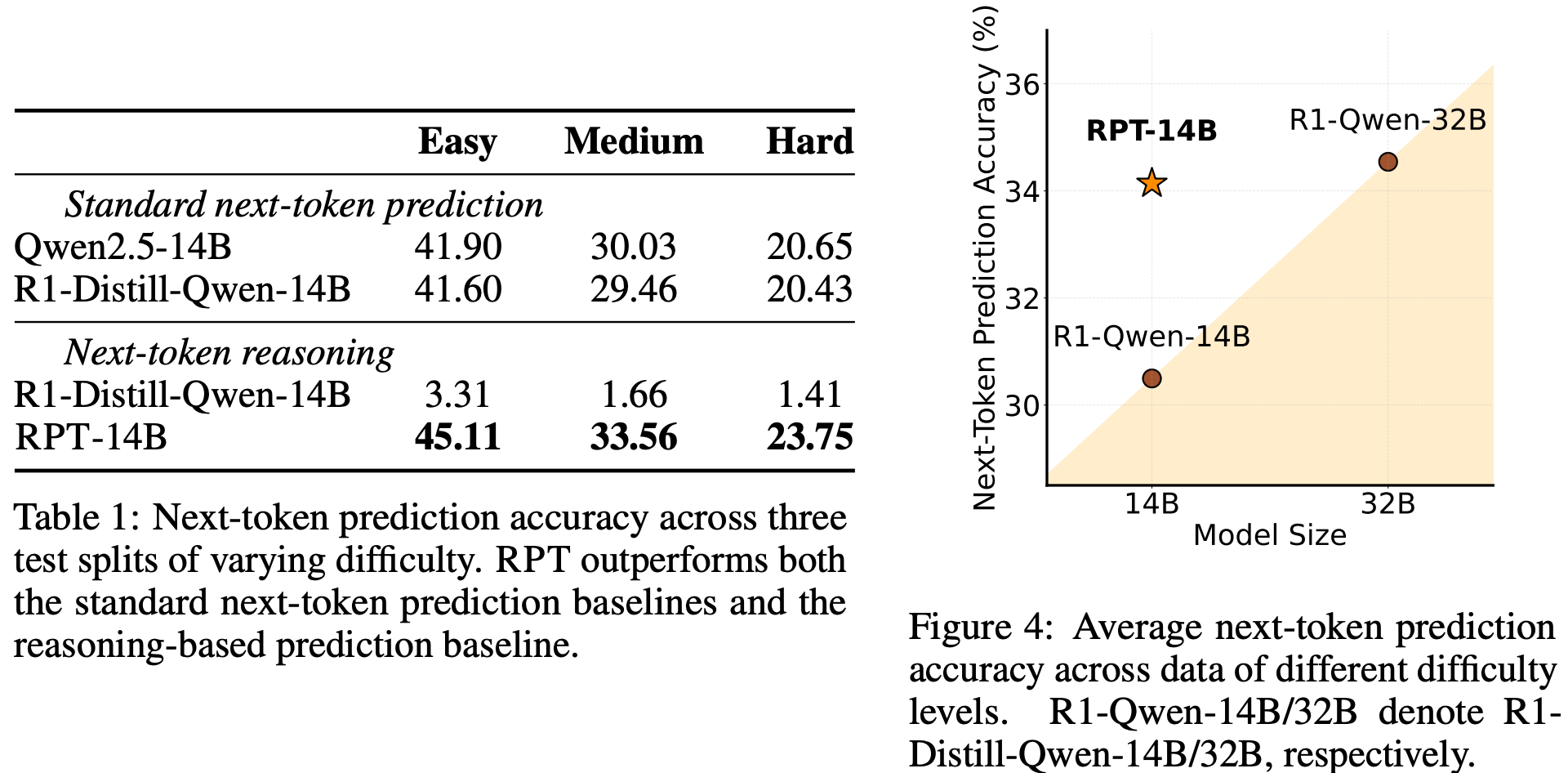
In the language modeling setup, a held-out validation set of 200 samples from OmniMATH was used. Tokens were categorized into easy, medium, and hard splits based on entropy, which essentially measures the uncertainty of prediction. Baselines included standard next-token prediction using Qwen2.5-14B and R1-Distill-Qwen-14B, as well as a next-token reasoning baseline using R1-Distill-Qwen-14B with chain-of-thought style reasoning.
The results were striking: RPT-14B consistently outperformed all baselines across difficulty levels. On hard tokens, for example, accuracy improved from about 20% to nearly 24%. Even more impressive, RPT-14B matched or exceeded the performance of a much larger R1-Distill-Qwen-32B. This suggests that reinforcement pre-training doesn’t just improve memorization but injects genuine reasoning signals that help the model generalize better.
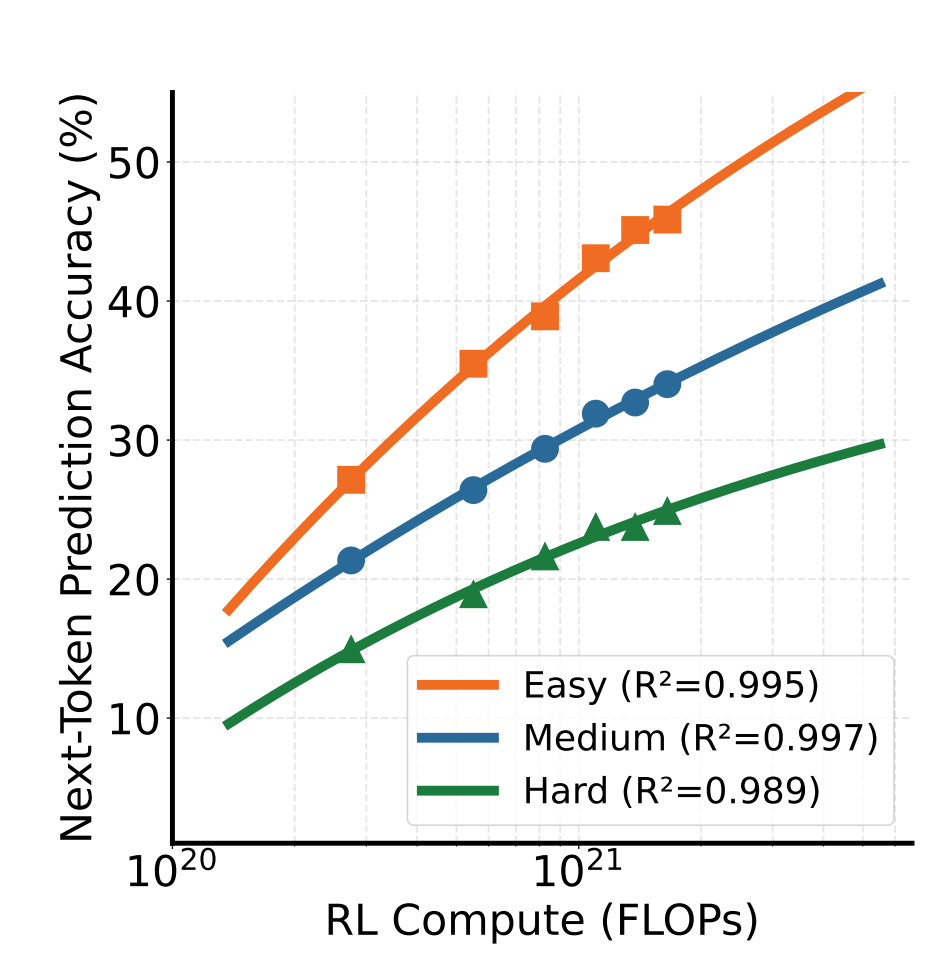
2. Scaling Properties of Reinforcement Pre-Training
Scaling properties were another key focus. Traditional LLM pre-training is known to follow a power-law relationship between compute and performance, and the authors investigated whether RPT shows similar behavior. By evaluating RPT at different compute budgets (100–1200 training steps), they found that accuracy improved smoothly with increasing compute, with fitted curves showing R² values close to 0.99 across all difficulty splits. This confirms that RPT scales predictably, the more compute you invest, the more reasoning-driven improvements you get.
3. Reinforcement Fine-Tuning with RPT
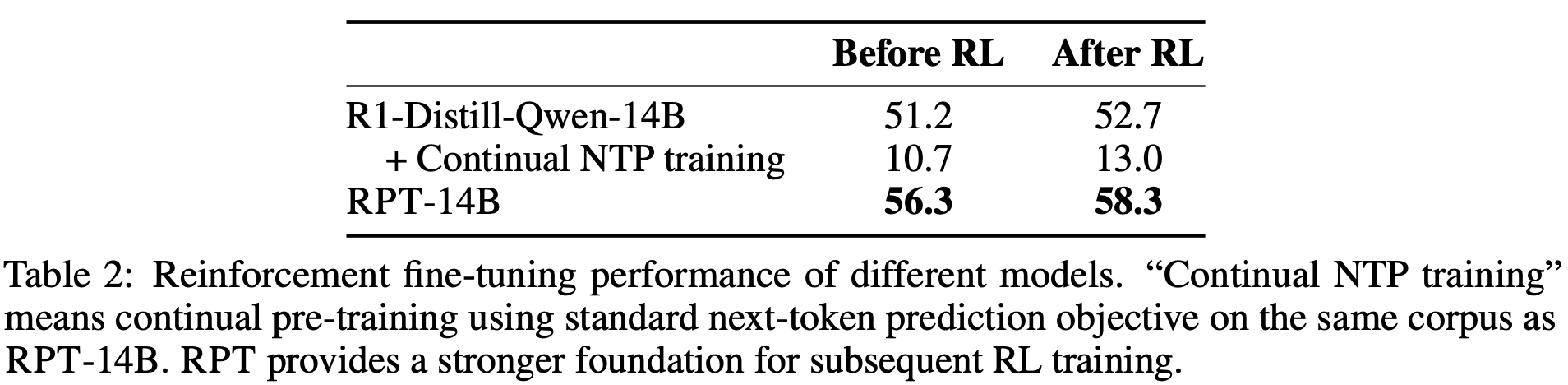
The team then explored how RPT interacts with reinforcement fine-tuning (RLVR). Using a small-scale setup with 256 training and 200 testing samples from Skywork-OR1, they compared continual next-token pre-training versus reinforcement pre-training. The results were clear: continual next-token pre-training actually degraded reasoning ability, while RPT provided a strong foundation that transferred effectively to RL fine-tuning. For instance, R1-Distill-Qwen-14B improved only marginally (51.2 → 52.7 accuracy) after RL, whereas RPT-14B started higher (56.3) and climbed further (58.3). This shows that reinforcement pre-training primes models to benefit more from subsequent alignment and task-specific fine-tuning.
4. Zero-Shot Performance on End Tasks
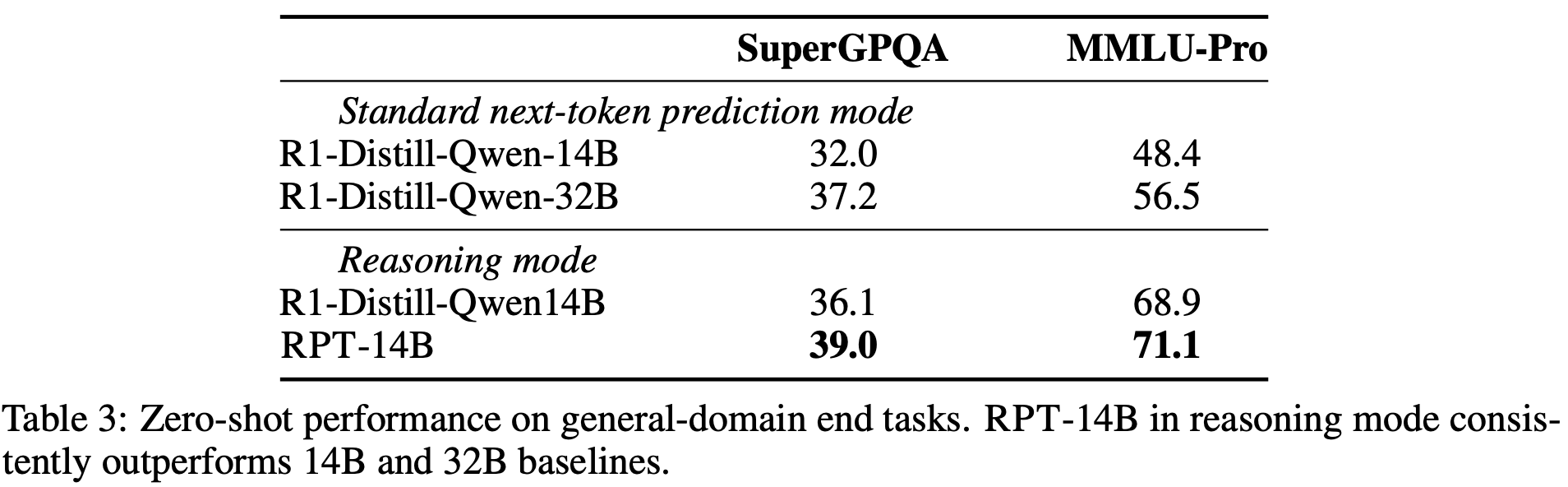
Beyond pre-training and fine-tuning, the authors also examined zero-shot generalization. On two widely recognized benchmarks; MMLU-Pro and SuperGPQA, the RPT-14B consistently outperformed R1-Distill-Qwen-14B in both standard and reasoning modes. Remarkably, RPT-14B even surpassed the much larger R1-Distill-Qwen-32B under next-token prediction, with gains of about 7 points on SuperGPQA and 22 points on MMLU-Pro. This underscores the idea that reinforcement pre-training can substitute for sheer scale, injecting reasoning ability that size alone doesn’t guarantee.
5. Next-Token Reasoning Pattern Analysis
Finally, the team analyzed reasoning patterns to see how RPT changes the way models think. By comparing R1-Distill-Qwen-14B (used for problem solving) with RPT-14B (used for next-token reasoning), they found marked differences in thought processes.
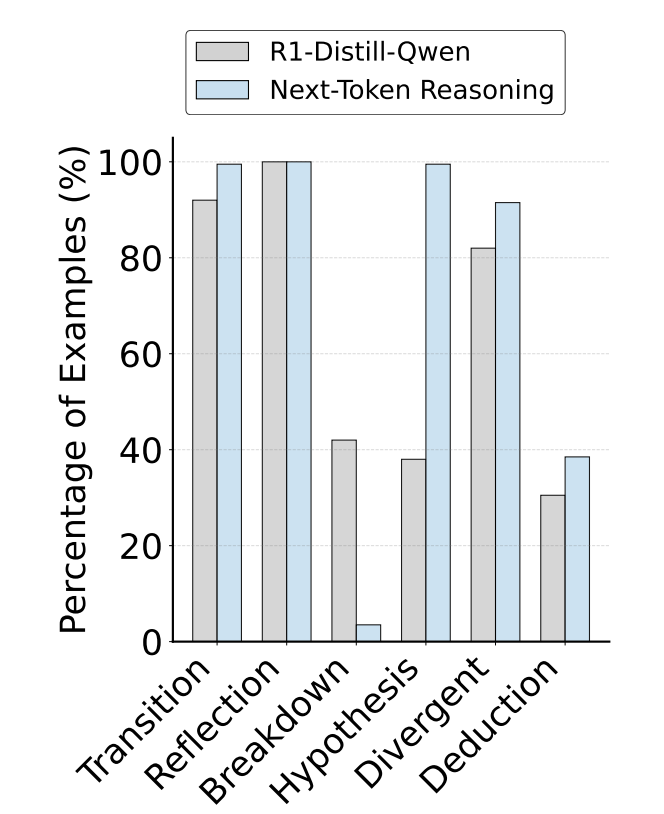
RPT-14B showed a much higher use of hypothesis generation (+161%) and deduction (+26%), while the baseline leaned more heavily on breakdown strategies. Example traces revealed that RPT doesn’t just pattern-match tokens but engages in deliberative processes: brainstorming alternatives, reflecting on structural cues, and weighing multiple plausible continuations. This qualitative shift shows that RPT nudges models toward inferential reasoning rather than shallow correlations.
In sum, across quantitative benchmarks and qualitative analysis, RPT proves its value: better accuracy on hard tokens, predictable scaling, stronger reinforcement fine-tuning, superior zero-shot performance, and richer reasoning patterns.
7. Thoughts
RPT is compute- and cost-intensive: Unlike standard pre-training, reinforcement pre-training requires repeated rollouts, reward computations, and cross-episode updates. This drastically amplifies time, compute, and cost requirements. Scaling such pipelines beyond research demos to production-level LLMs will demand innovations in both algorithmic efficiency and infrastructure design.
Autoregression is limited: Token-by-token generation is inherently inefficient, it is like walking blindfolded with only one-step lookahead. This is why we might need better generative backbones (latent diffusion models, or other latent-space models) for reasoning.
Reasoning in latent space: Instead of optimizing in raw token space, moving reasoning into a compressed latent space could allow for more global, structured exploration. Think of it as solving puzzles in the “idea space” before committing to words.
Reasoning as constrained optimization: Another way is to frame reasoning as a pathfinding task, hence, trying to minimize the number of steps/tokens to reach a goal token. This turns reasoning into a search over efficient trajectories, like finding shortest paths on a graph (which might reduce the rollout cost, as the task is to shorten the path itself, though it may lead to some sort of collapse).
8. Conclusion
At its core, Reinforcement Pre-Training reframes reasoning as an optimization process rather than a side-effect of alignment. By moving beyond pure next-token prediction and introducing structured reward-guided exploration, we gain the ability to push models toward deeper, multi-step reasoning rather than shallow, greedy continuation.
In this article, we began by tracing the rise of modern LLM training pipelines, from massive pre-training to careful alignment tuning, and why this multi-stage setup balances coverage with behavioral precision. We then revisited reasoning itself from CoT and CoCOnut methods to the view of reasoning as emergent under RL-based alignment and highlighted why token prediction alone is too myopic. We explored the ideal scenario of abundant compute and high-quality semantics, before diving into reinforcement pre-training: its methodology, how it shifts optimization from one-step lookahead to guided exploration, and the implications across domains. Finally, we discussed open thoughts on architecture, latent-space reasoning, optimization framing, and the immense compute challenges ahead.
Hence, the key takeaway is that RPT is not just another fine-tuning trick; it is the first serious attempt to treat reasoning as part of pre-training itself, rather than a patch added later. Sometimes, changing what we optimize for; changes what the model is. Personally, I’m excited about the possibilities that emerge when reasoning is not an accident, but a design choice.
RPT paper : https://arxiv.org/abs/2506.08007
That's all for today.
Follow me on LinkedIn and Substack for more such posts and recommendations, till then happy Learning. Bye👋
Thanks for beautiful explanation