
Understanding Byte Pair Encoding (BPE) in Large Language Models
Unlocking the Power of Byte Pair Encoding in LLMs: A Closer Look at Tokenization


Byte Pair Encoding (BPE) is one of the most popular subword tokenization techniques used in natural language processing (NLP). It plays a crucial role in improving the efficiency of large language models (LLMs) like GPT, BERT, and others. This article will provide a detailed explanation of BPE, its algorithm, and why it’s so effective, along with illustrative figures.
“Byte Pair Encoding (BPE) is a data compression technique that iteratively merges the most frequent pair of consecutive bytes (or characters) in a text or data sequence into a single, new symbol. The process is repeated until a specified number of merges is reached or no more frequent pairs remain”

1. What really is Byte Pair Encoding?
Character level tokenization is not very efficient.
This has been explained in detail in this post:

Byte Pair Encoder (BPE) uses subwords as tokens instead of characters.
Instead of treating every character or word as an individual unit, BPE operates on subword units, which helps solves 2 things:
It prevents the number of tokens needed to represent the text from increasing too much, which is the main issue with character tokenization (this is referred to as ballooning effect in the blog post link shared above).
We retain linguistic patterns: such as common prefixes, suffixes, and word stems.
BPE iteratively merges the most frequent pair of characters or subwords in a corpus until a predefined vocabulary size is reached.
2. BPE Algorithm explained with a simple example

Let’s say we have only 2 words in our dataset: low and lowest.
Initialization:
Start with each character in the corpus as a separate token:Vocabulary:{l, o, w, e, s, t, </w>}Tokenization at Character Level:
Each word is represented as a sequence of characters with a special end-of-word marker:"low" →
l o w </w>"lowest" →
l o w e s t </w>
Counting Pair Frequencies:
Identify the most frequent adjacent pairs of tokens:Pair
l oappears twice: once in "low" and once in "lowest".Pair
o wappears twice: once in "low" and once in "lowest".Pair
w </w>appears once: in "low".Pair
e sappears once: in "lowest".Pair
s tappears once: in "lowest".
Merge the Most Frequent Pair:
Bothl oando wappear twice, so either could be merged first. Let's assume we mergeo wfirst:"low" →
l ow </w>"lowest" →
l ow e s t </w>
Vocabulary:{l, ow, e, s, t, </w>}Recount Pair Frequencies:
After the first merge:
Pair
l owappears twice.Pair
e sappears once.Pair
s tappears once.
Merge the Next Frequent Pair:
Merge l ow:
"low" →
low </w>"lowest" →
low e s t </w>
Vocabulary: {low, e, s, t, </w>}Recount Pair Frequencies:
After the second merge:
Pair
e sappears once.Pair
s tappears once.
Merge the Next Frequent Pair:
Merge e s:
"lowest" →
low es t </w>
Vocabulary: {low, es, t, </w>}Merge the Final Pair:
Merge es t:
"lowest" →
low est </w>
Vocabulary: {low, est, </w>}Final Vocabulary:
After all merges, the final vocabulary includes:
lowest</w>
This vocabulary is sufficient to represent the words in the corpus:
"low" →
low </w>"lowest" →
low est </w>
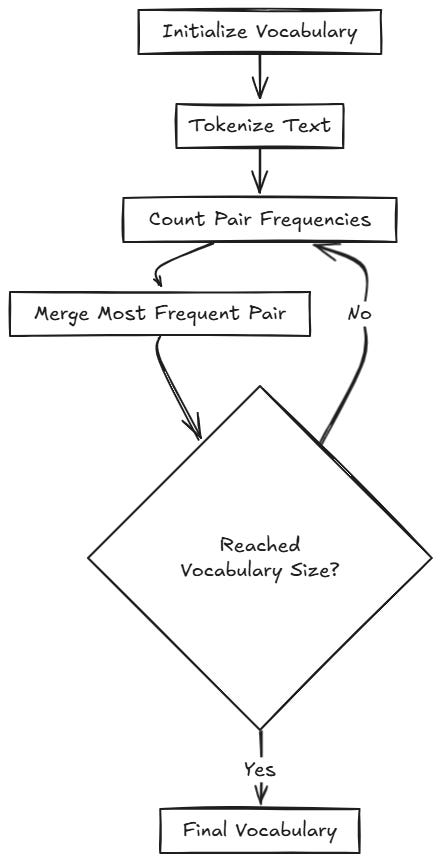
The final vocabulary consists of both characters and meaningful subwords that frequently occur together in the corpus.
Compared to the initial vocabulary of single characters, the final vocabulary is:
Efficient : It groups frequently co-occurring characters or subwords into single tokens, minimizing the total number of tokens needed. This make it possible to fit longer sentences within the context window of the LLM during pre-training.
Context-aware: It encodes linguistic patterns, such as common prefixes, suffixes, and word stems, making tokenization more efficient for downstream tasks. Having “est” as one token is an example of this.
3. How do we decide the vocabulary size?
Note: The desired vocabulary size is a hyperparameter in the BPE algorithm, and it decided by the user. For example, GPT-2 has a vocabulary size of 50257 while GPT-4 has a vocabulary size of ~100000.
The key thing to note is that there is a trade-off between vocabulary size and sequence length, which is very important to decide the vocabulary size.
Vocabulary size directly impacts how text is tokenized:
Larger Vocabulary:
Fewer tokens per sentence (longer subwords or even whole words are represented as single tokens).
Better for capturing rare words or linguistic nuances.
Increases memory and computational costs for embedding and training.
Smaller Vocabulary:
More tokens per sentence (each token represents a smaller unit like a character or short subword).
Since token length for sentences is very high, the tokens may not fit in context length of LLMs. This may lead to loss of context and poor LLM training.
The nature and size of the training corpus also heavily influences the vocabulary size:
Large, Diverse Data:
A larger vocabulary is often needed to handle diverse linguistic patterns, rare words, and multilingual data (such as regional language data).Small or Domain-Specific Corpora:
A smaller vocabulary may suffice because the language use is limited.
4. Here’s an implementation of Byte-Pair Encoding (BPE) in Python:
Coding file (shortened from Andrej Karpathy’s original file):
We start a simple text passage about the movie Dark Knight Rises:

“The Dark Knight Rises is a superhero movie released in 2012. It is the final part of Christopher Nolan’s Dark Knight trilogy, following Batman Begins and The Dark Knight. The film stars Christian Bale as Bruce Wayne/Batman, who has been retired as Batman for eight years after the events of the previous movie.
The main villain in the movie is Bane, played by Tom Hardy. Bane is a powerful and intelligent terrorist who threatens Gotham City with destruction. He forces Bruce Wayne to come out of retirement and become Batman again. Anne Hathaway plays Selina Kyle, also known as Catwoman, a skilled thief with her own agenda.
The movie is about Bruce Wayne’s struggle to overcome his physical and emotional challenges to save Gotham. It also shows themes of hope, sacrifice, and resilience. The film has many exciting action scenes, such as a plane hijack and a massive battle in Gotham.
In the end, Batman saves the city and inspires the people of Gotham. However, he is believed to have sacrificed his life. The movie ends with a twist, suggesting that Bruce Wayne is alive and has moved on to live a quiet life.
The Dark Knight Rises was a big success and is loved by many fans for its epic story, strong characters, and thrilling action”
With character level tokenization, we have:
Vocabulary size = 256
Number of tokens = 1252
Now, we will implement the BPE algorithm. To do this, first we need to decide the desired vocabulary size. Let’s say the desired vocabulary size is 276. This means that we will add 20 additional tokens to the vocabulary. This also means that we will perform 20 merges through the BPE algorithm.
When you run the code, here are the 20 merges performed:
merging (101, 32) (e ) into a new token 256
merging (115, 32) (s ) into a new token 257
merging (97, 110) (an) into a new token 258
merging (116, 104) (th) into a new token 259
merging (100, 32) (d ) into a new token 260
merging (105, 110) (in) into a new token 261
merging (116, 32) (t ) into a new token 262
merging (32, 115) ( s) into a new token 263
merging (101, 110) (en) into a new token 264
merging (105, 257) (iā) into a new token 265
merging (101, 114) (er) into a new token 266
merging (258, 260) (ĂĄ) into a new token 267
merging (104, 256) (hĀ) into a new token 268
merging (97, 114) (ar) into a new token 269
merging (114, 101) (re) into a new token 270
merging (46, 32) (. ) into a new token 271
merging (44, 32) (, ) into a new token 272
merging (84, 268) (TČ) into a new token 273
merging (111, 32) (o ) into a new token 274
merging (111, 118) (ov) into a new token 275
After BPE, the final vocabulary size and number of tokens are:
Vocabulary size = 276
Number of tokens = 957
Using BPE, the number of tokens needed to represent the text are reduced from 1252 to 957. This is a compression ratio of 1.3 times!
This demonstrates the advantage of BPE in reducing number of tokens needed to represent a text. In addition, we also retain linguistic patterns through subwords like “in” and “en” which have been merged!
5. Byte Pair Encoding (BPE) Summary:
BPE tokenizers break down unknown words into subwords and individual characters:
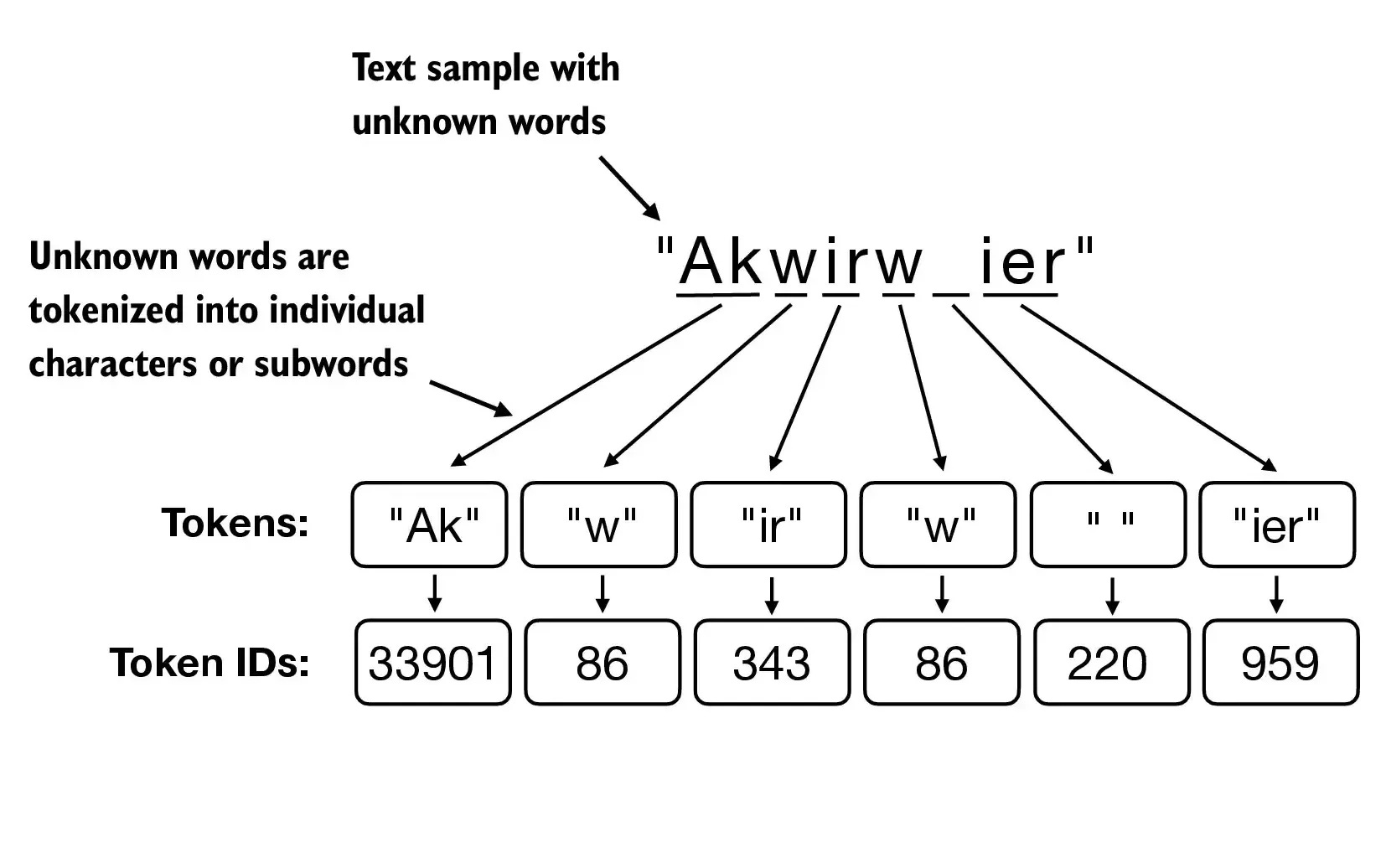
This leads to 2 advantages:
It prevents the number of tokens needed to represent the text from increasing too much, which is the main issue with character tokenization.
We retain linguistic patterns: such as common prefixes, suffixes, and word stems.
6. Limitations of BPE
While BPE is highly effective, it has some limitations:
Fixed Vocabulary Size
BPE relies on a pre-determined vocabulary size. If this size is too small, it may over-segment words into subwords, losing semantic meaning. If it's too large, it may include unnecessary subword units, making the model less flexible.
Conclusion

Byte Pair Encoding is a cornerstone of modern NLP, providing a balance between vocabulary size and language coverage. By understanding its inner workings, we can appreciate the efficiency and power it brings to large language models.
This article confused me even more than I was.
In the initial example you started with 7 distinct tokens and ended up with 3 distinct tokens. Later on, you said you need to perform 20 merges through the BPE algorithm to add 20 additional tokens.
Once decreased the vocab size, other increased? How?
I read in another source that the merged tokens are still retained in the vocabulary. So the first example of you is misleading.
In Step 2, we iteratively merge tokens from single characters. But do we remove single characters from our vocabulary after merging them? The final vocab only consists of 3 tokens 'low', 'est', '</w>', should it not additionally still contain the original characters?