
What are Large Reasoning Models?
How did humans build AI models which could reason like them?

Human beings have this incredible gift of being able to “think deeply”.
What does “deeply” mean here?
Well, it means that, all of us are doing “something” in that tiny little brain of ours, that allows us to navigate our way in this world, which is complex.
Think about the time when you are ordering a cake for your mother on her birthday.

It does take some time to think about the right cake. I consider the following:
(1) What is her favorite cake?
(2) Did she like the last one?
(3) Should I try something different this time?
(4) Has she expressed any recent cravings?
etc, etc..
In short, we have many different thoughts in our brain, which are processed to help us come up with the right cake.
This process is what we call as “reasoning”.
But, all questions do not require reasoning. For example, if someone asks me the capital of India, I can immediately give the right answer.
That is true…Almost.
Types of Reasoning
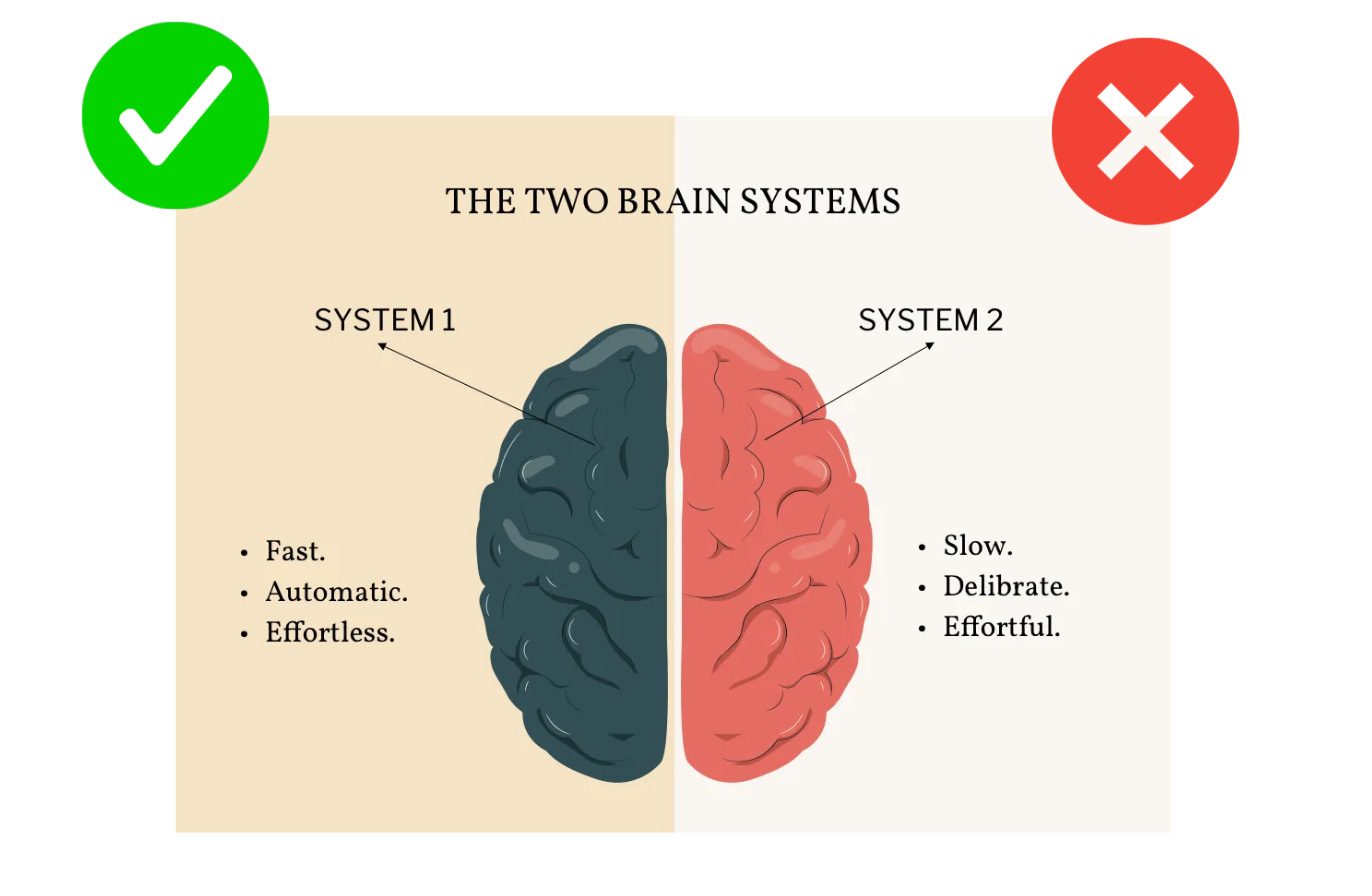
Reasoning comes in 2 types - Fast Reasoning and Slow Reasoning.
Fast reasoning helps us think immediately about the answer.
Example: “What is the capital of India”
On the other hand, slow reasoning helps us think slowly to get to the answer.
Example: “Which movie shall I watch tonight” (I take a long time to decide this)

The fast reasoning process is also called as “System 1” thinking, and the slow reasoning process is called as “System 2” thinking.
This terminology is popularized in the famous book called “Thinking Fast and Slow” written by Daniel Kahneman (I highly recommend reading this book).

Now, the central question in which the AI community is interested in is this:
Can Large Language Models (LLMs) reason?
You might say that: “Duh, they should reason..Aren’t LLMs made to think like humans”
Well, no.
LLMs are made to answer like humans, not think like them.
ChatGPT was the first user-facing LLM which came out in December 2022.
Here is an example of what it could do:

It gave us answers on literally anything we asked.
It was crazy good at tasks.
Let me rephrase..It was crazy good at “System 1” tasks.
For tasks which required complex reasoning, i.e “System 2” thinking, it was not very good.
Here is a classic example, where earlier versions of LLMs failed:

In 2022 and 2023, we were here:
LLMs worked for the most part. But, they were a “black box”. And that black box was not thinking like humans do.
So, what was the black box doing?
LLMs are trained on a huge corpus of data. The data consists of input-output pairs which the LLM learns to mimic.
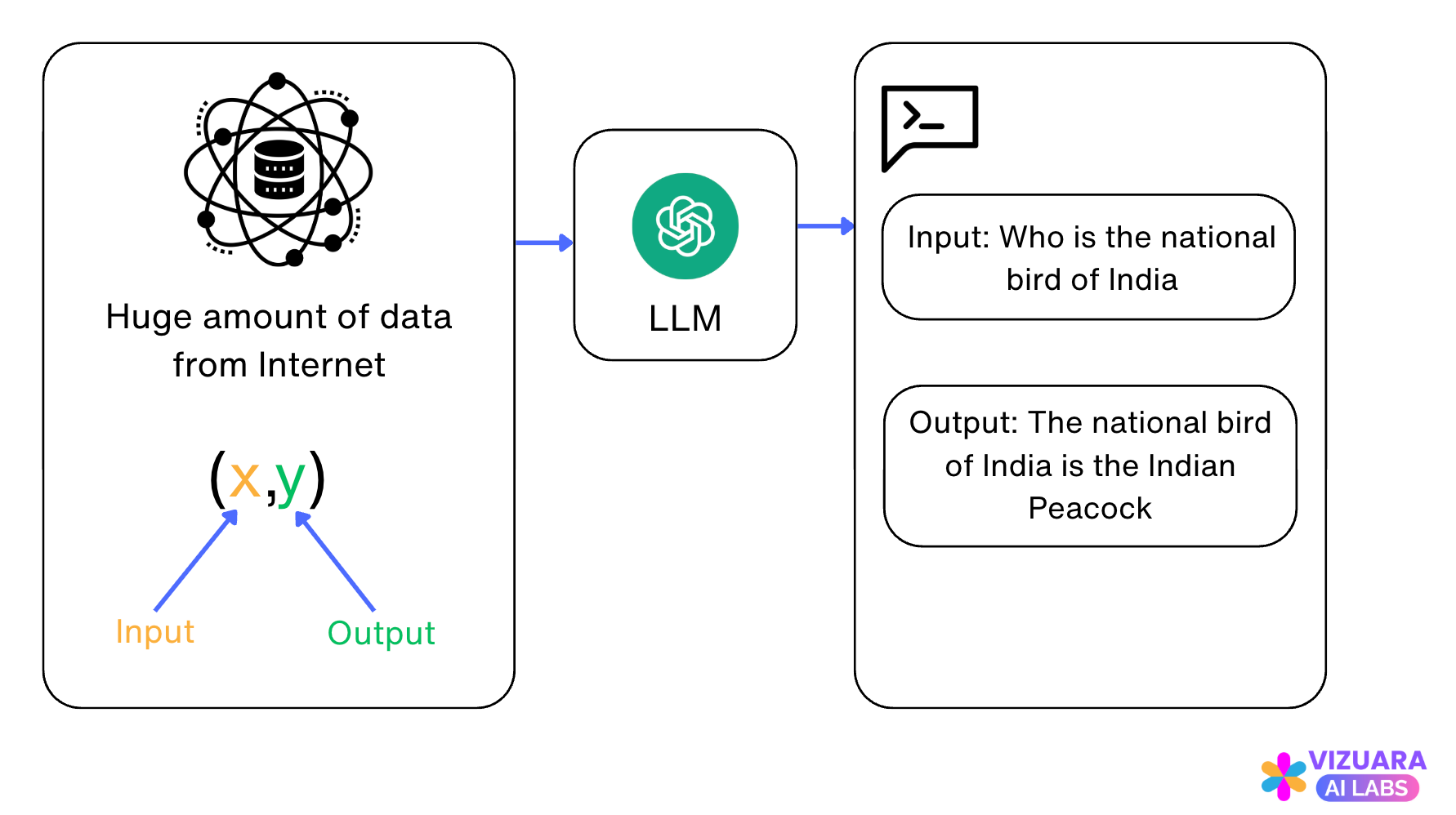
When we get an answer from ChatGPT, we think that: “Oh, it is so smart, it can actually think”
But it does not think.
It is understanding the patterns from the input-output pairs of data and giving you the answer which aligns the most with the patterns it has learnt.
This was something the AI research community was not very happy with. And thus the quest for building LLMs which can actually reason began.

Making Large Language Models which can reason
The first reasoning model, o1, was released by OpenAI on September 12 2024.
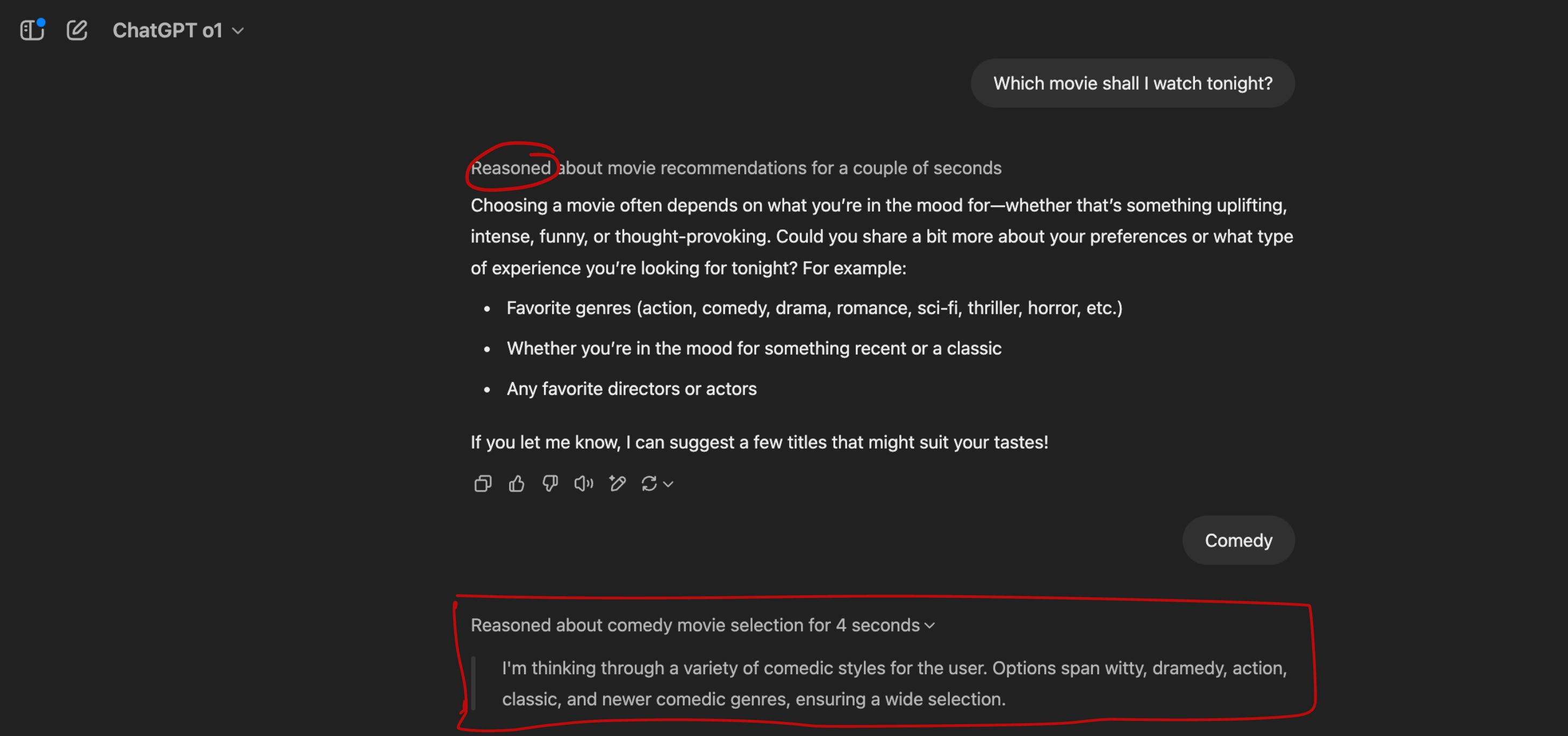
After asking questions like “Which movie shall I watch tonight”, the LLM appears to be going through a reasoning process, like humans.
It thinks for some time..4 seconds..and then gives the answer.
Now, Open AI does not open-source its models. So, no one knew how they had made it work.

It almost looked like magic.
Until it didn’t.
On January 20, 2025, DeepSeek, a Chinese company, released a reasoning model named “DeepSeek-R1” which rivaled the performance of o1.

And it was open source.
For the first time, people could see what had made the o1 work think like humans.
The recipe was out in the open.
The recipe involved 4 ingredients, which became the blueprint for building a large reasoning model.
Let us have a look.
Blueprint for building a large reasoning model (The 4 Ingredients)
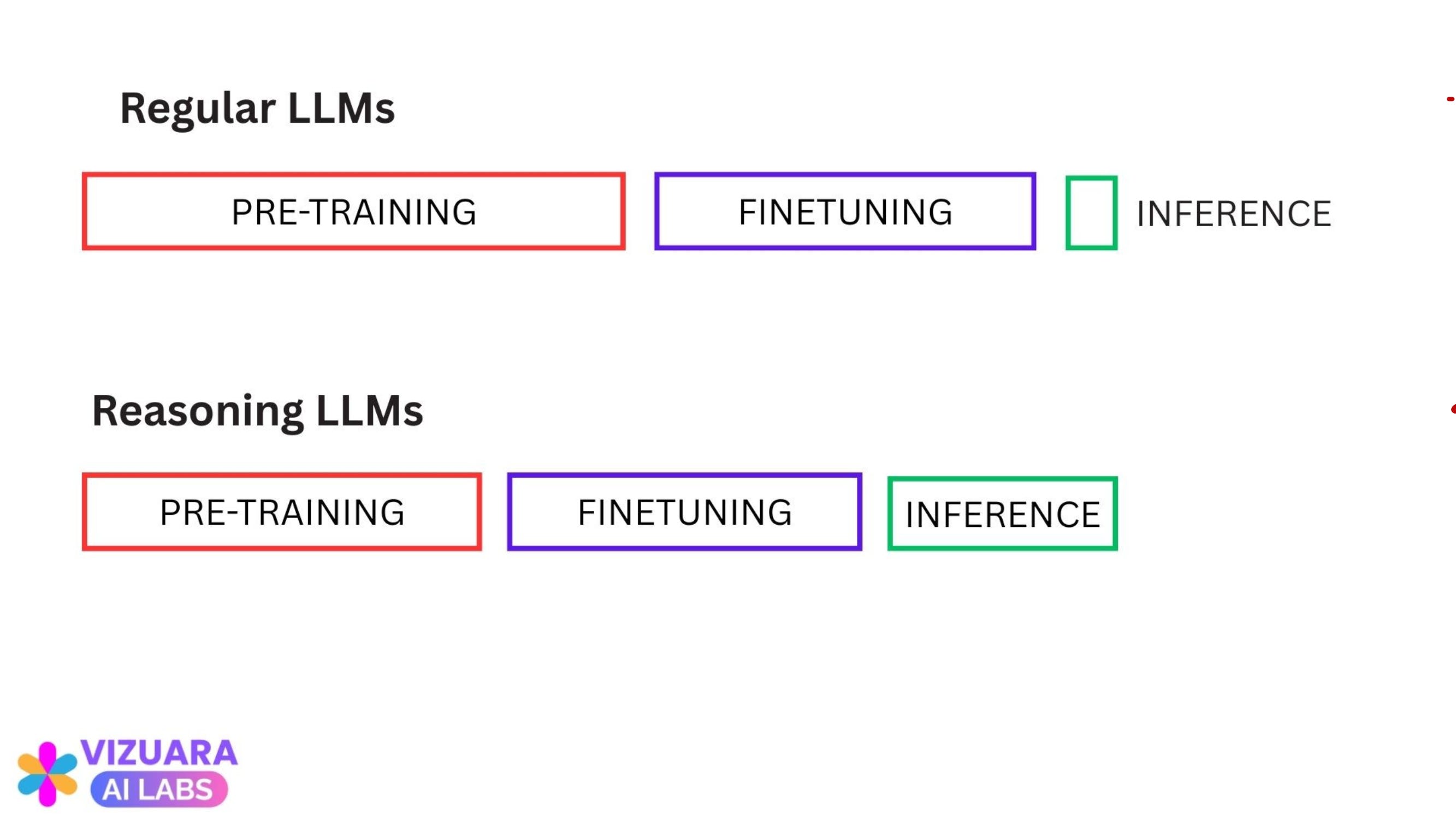
Ingredient #1: Inference-Time Compute Scaling
All of us have observed that, humans tend to give better answers when they think for more time.
Why does this happen?
Because thinking step-by-step leads to the correct answer.
Think about complex Maths problems or puzzles (e.g., Sudoku)

We need time and mental energy to think about such problems before we reach the solution.
Now, apply the same concept to LLMs.
What will happen if we make LLMs think before giving an answer?
Let us take a simple example.
Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 balls. How many tennis balls does he have now?
Let us see a regular (non-reasoning) LLM answers this:
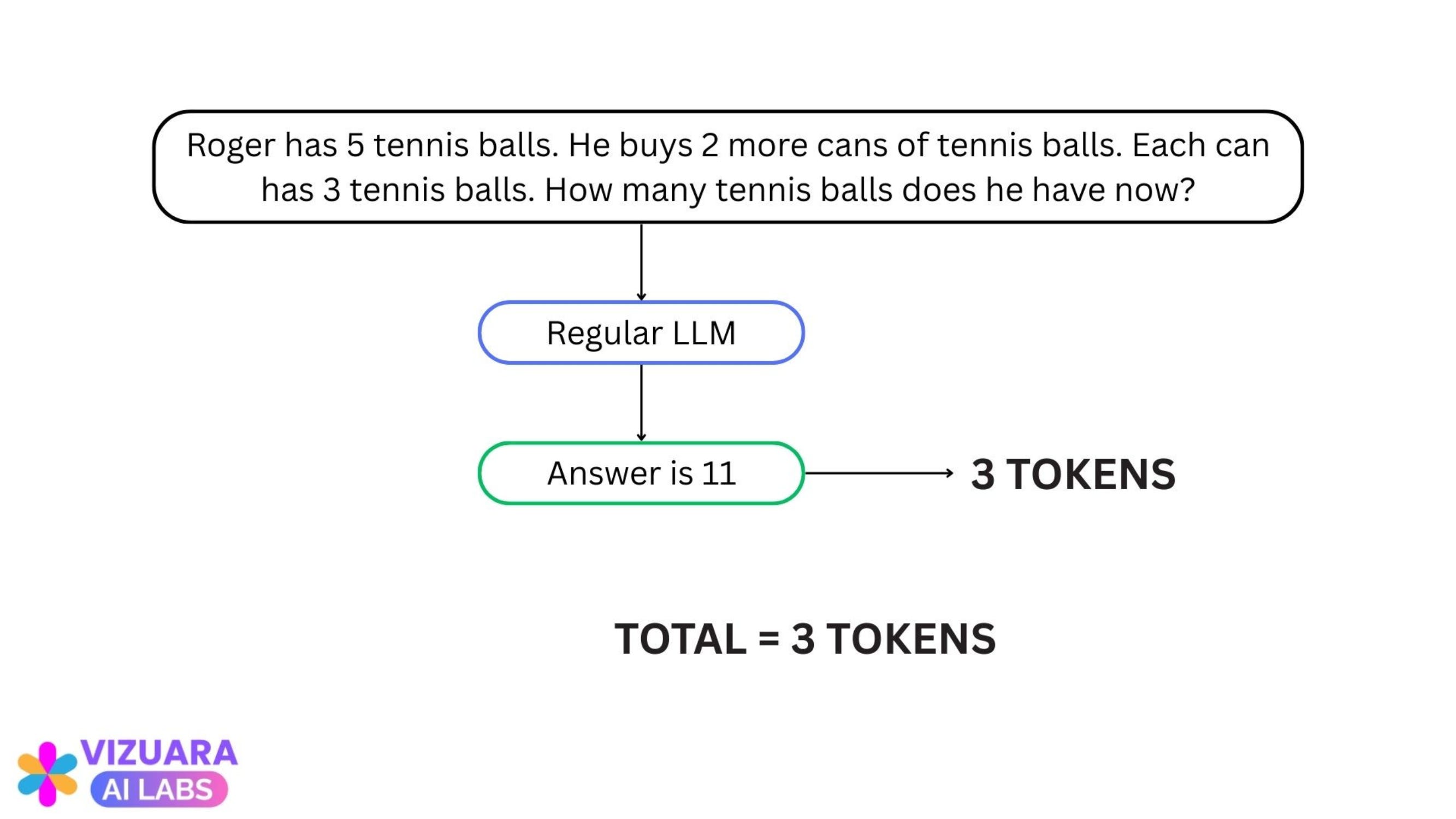
The LLM uses 3 tokens: [“Answer”, “is”, “11”]
Now, we will force the model to “think” before it gives an answer.
This is what we get:
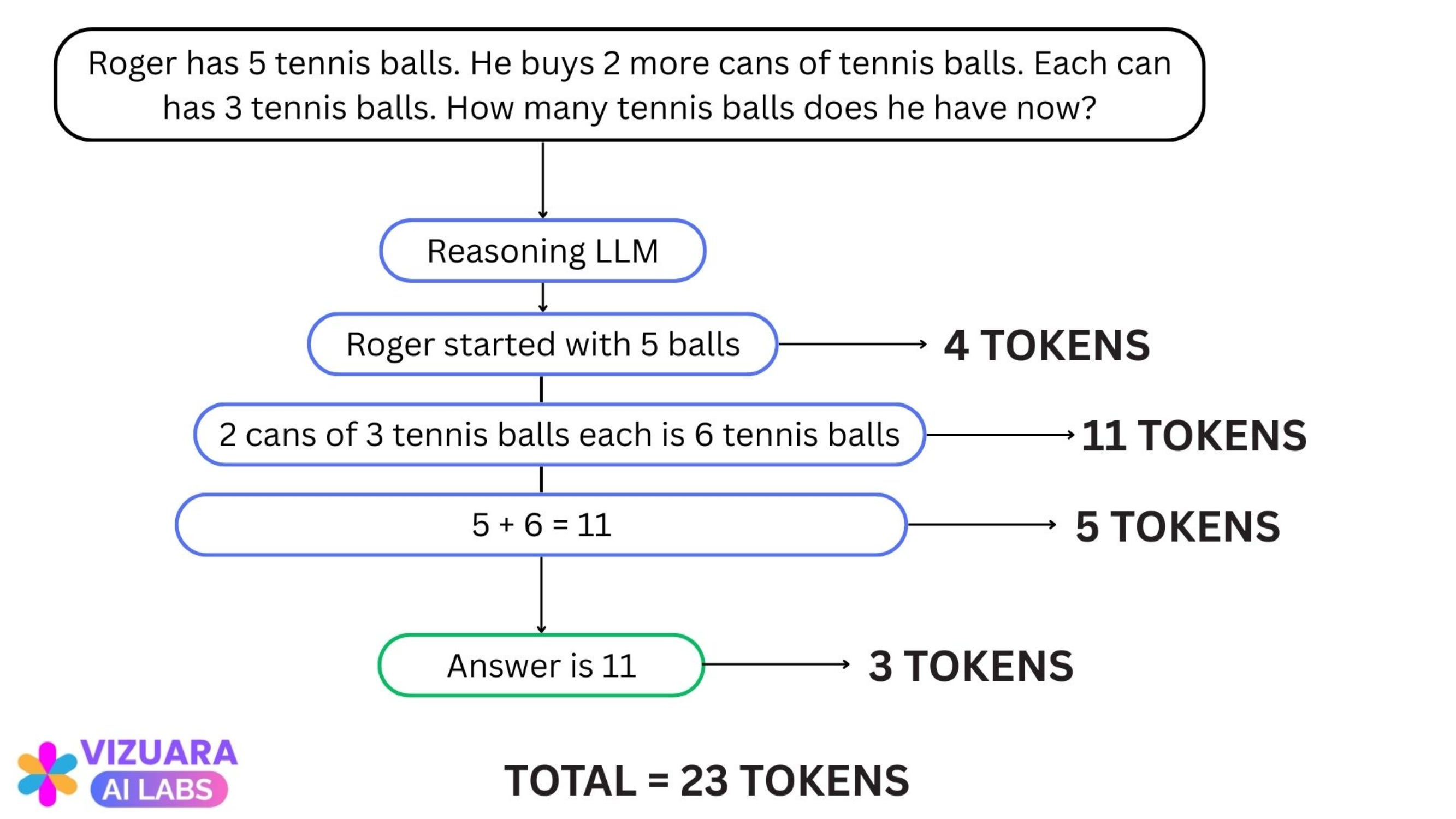
The model uses 23 tokens as it shows us the step-by-step reasoning it uses to get to the answer.
Test-time compute is the total computational resources used by the model during inference.
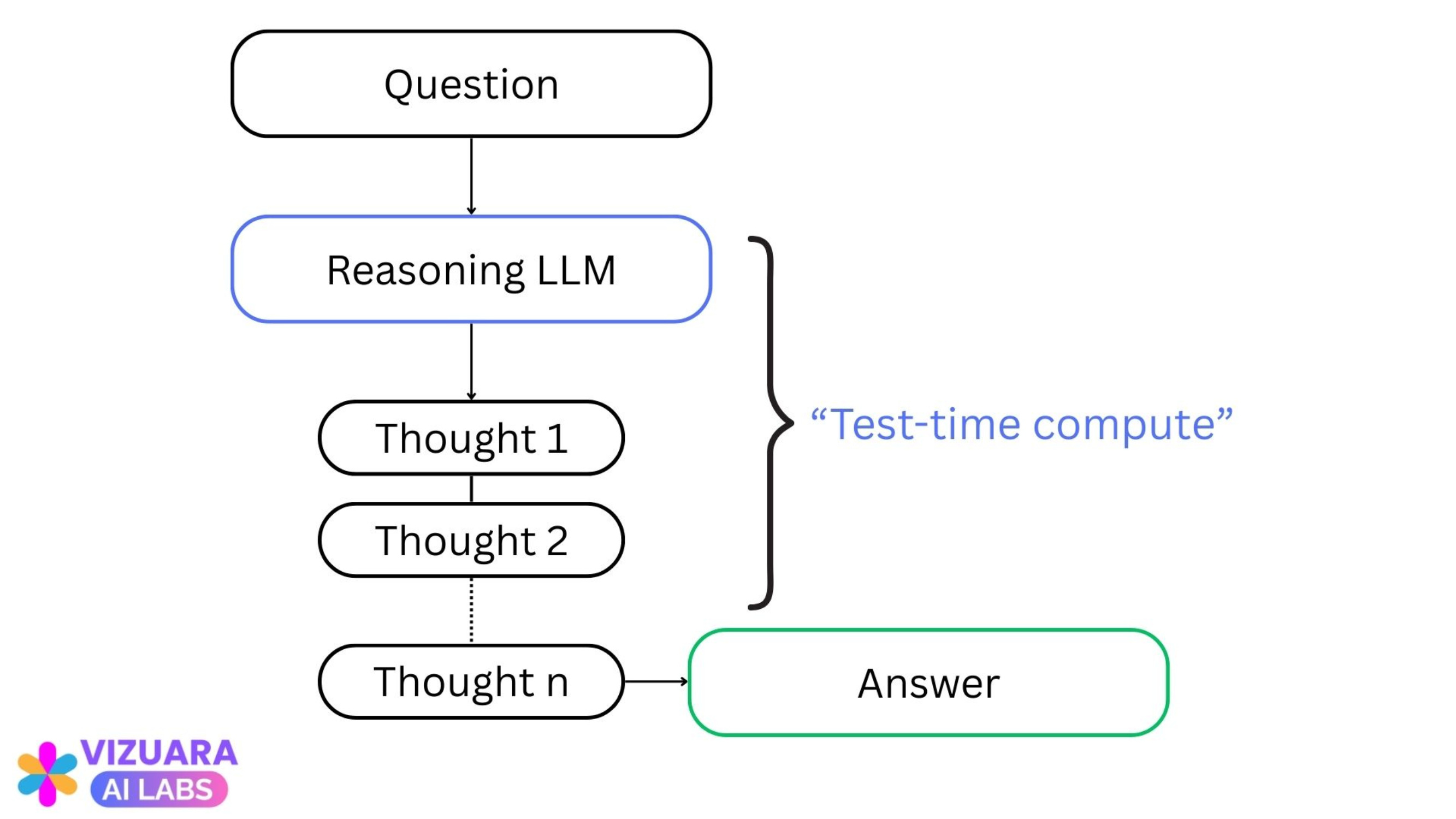
Ingredient 1 gives more time to the model to think. This way, the model spends more computing resources while thinking.
Now, it turns out that spending more computational resources during inference gives reasoning capabilities to the model.
Model accuracy on complex-reasoning tasks scales with test-time compute. Hence the name “Inference-Time Compute Scaling”.
So, giving more time to the LLM to think before answering gives better answers.

When did we think of this?

In 2022, by the Brain team at Google Research.
They found that, if we provide some examples in the prompt itself which guide the model on how to think, the model produces chains of thought for general user prompts.
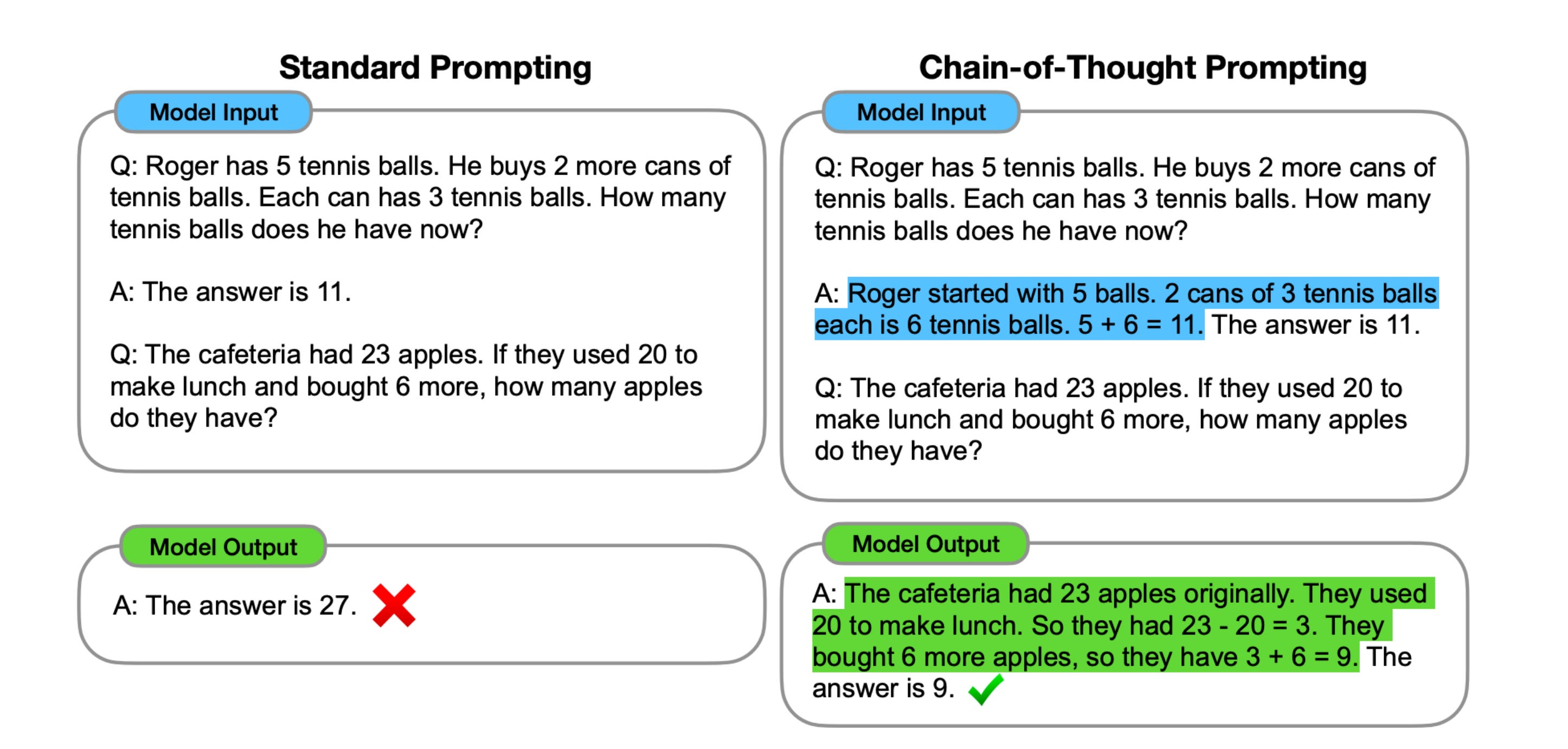
Here, notice the “blue highlighted lines”. They are the chains of thought given to the LLM in the prompt. This serves as a guide, which the model learns from and produces correct answers for reasoning tasks, such as the answer shown in “green highlighted lines”
Later, people said, why take this much effort, just add the following line to the prompt:
“Let’s think step by step”
And it worked.

Sometimes simple solutions do work beautifully.
Since then, there have been several methods which have induced reasoning only during inference, without tweaking anything with the model.
These are some popular methods which use “Ingredient 1” to increase the model capability to solve complex reasoning task:

Ingredient #2: Pure Reinforcement Learning
Reinforcement learning systems typically involve an agent-environment interface.
The agent is the entity whom we want to teach something. This could be a “master chess player” making a move, a “gazelle” learning to run, a mobile house cleaning “robot” making decisions or “you” eating breakfast.
In all these examples, the agent is interacting with the environment which takes the form of a chess board, nature, room or our internal state of mind. The goal of the agent is to achieve a reward, which for the above examples would be winning the chess game, running fast, collecting maximum amount of trash and obtaining nourishment.
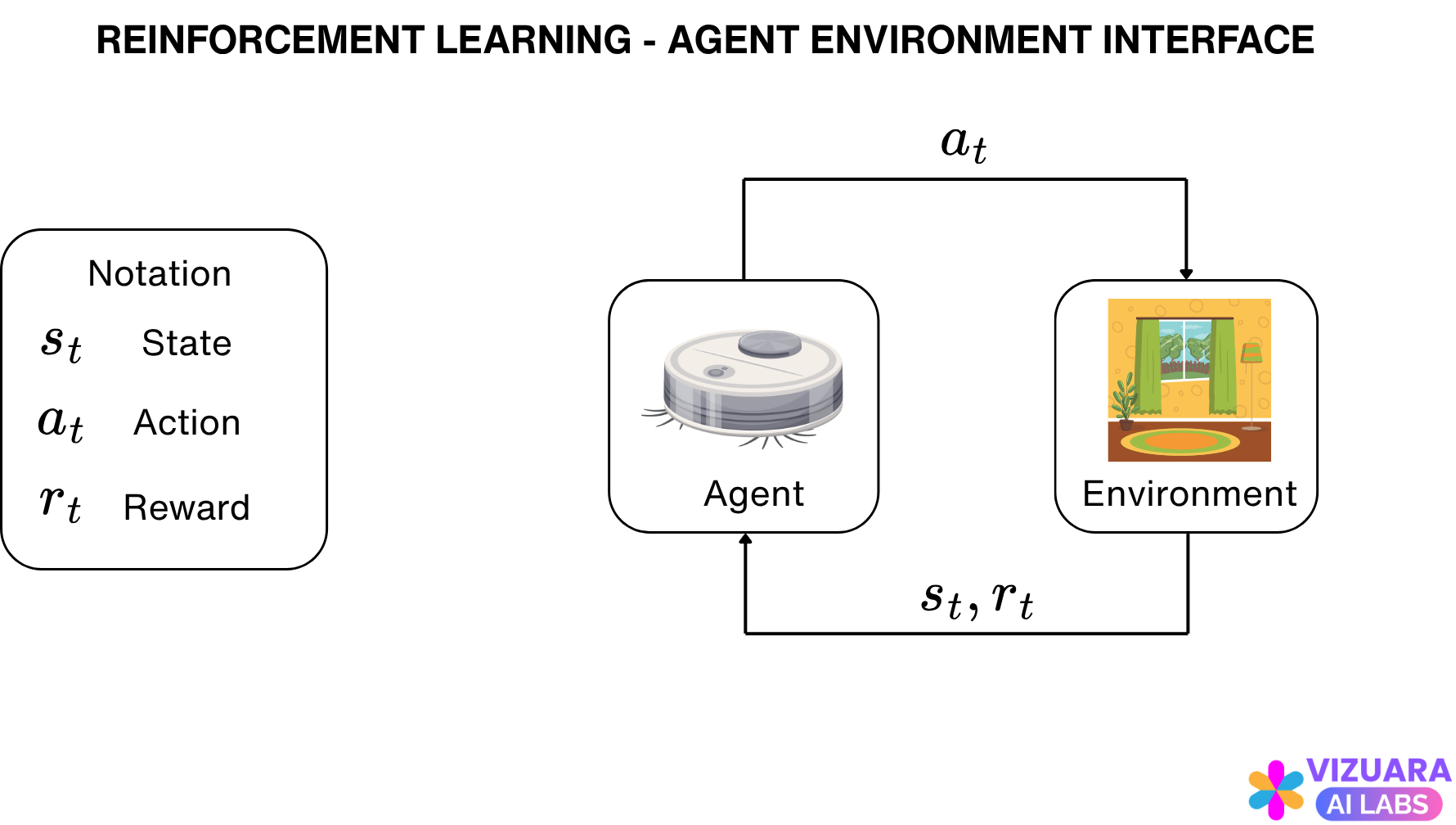
While the agent interacts with the environment, at each time step, it receives information of the state of the environment. Based on the state, the agent takes an action and receives a reward.
The goal of all reinforcement learning problems is to help the agent choose actions in such a way that the total cumulative rewards received by the agent is maximized.
The decision of choosing an appropriate action at each state is taken with the help of the agent’s policy.
If one attempts to formulate LLMs in terms of an agent-environment interface, it does not seem straightforward.
You can refer to this article for a more detailed understanding: How to think of LLMs as an RL problem?
The DeepSeek-R1 paper which we saw before, showed that using Pure Reinforcement Learning, we can give LLMs the capability to reason.
At the heart of “pure reinforcement learning” was the GRPO algorithm. Refer to this article for a more detailed understanding about GRPO: How does GRPO work?
The DeepSeek-R1 paper showed that, rather than explicitly teaching the model how to solve the problem, it automatically develops reasoning strategies by giving the right incentives to the model (rewards).
Consider the example below:

The model says “Wait, wait, Wait. That’s an aha moment I can flag here”. It does this by itself, without giving any supervised input-output examples.

The ingredient of Reinforcement Learning was an integral part for the blueprint to design Large Reasoning Models.
Ingredient #3: Supervised Fine-Tuning and Reinforcement Learning
In the DeepSeek-R1 paper, the model which used Pure Reinforcement Learning was called DeepSeek-R1-Zero.
This model proved that, pure RL can be used to induce reasoning in an LLM.
But, it was not a ready-to-use model.
It had an issue of language-mixing. Several times, the model mixed multiple languages in the output.
So, DeepSeek-R1 was developed.
It included 7 steps which I will list below.
Step 1: The DeepSeek-R1-Zero Model
The base model which is trained using Reinforcement Learning is called as DeepSeek-V3.
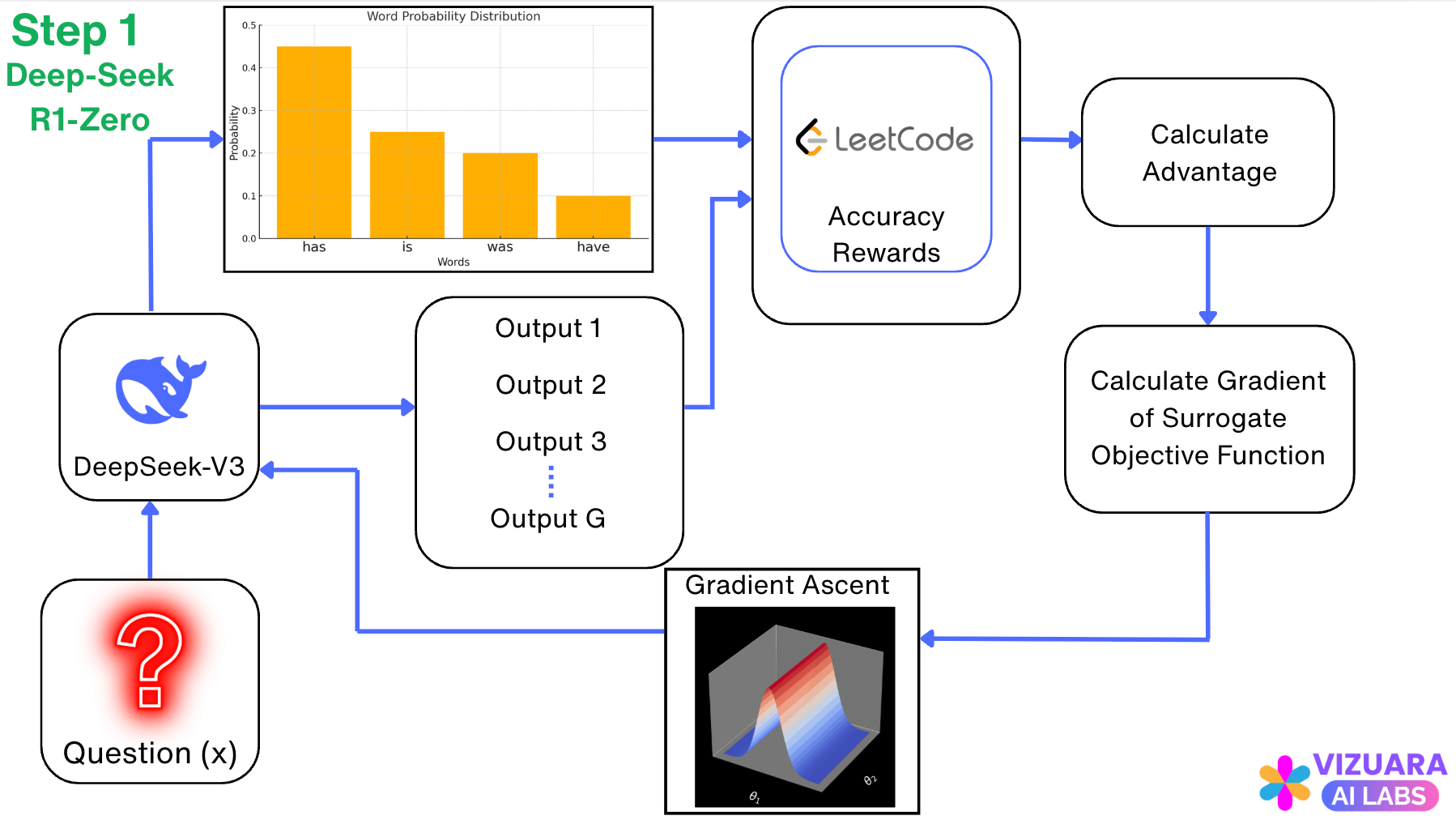
There are some things in this diagram which you might be seeing for the first time. Don’t worry. Just keep in mind that, this is the Reinforcement Learning process in DeepSeek-R1-Zero which used an algorithm called Group Relative Policy Optimization (GRPO).
But this is same as Ingredient #2. What else?
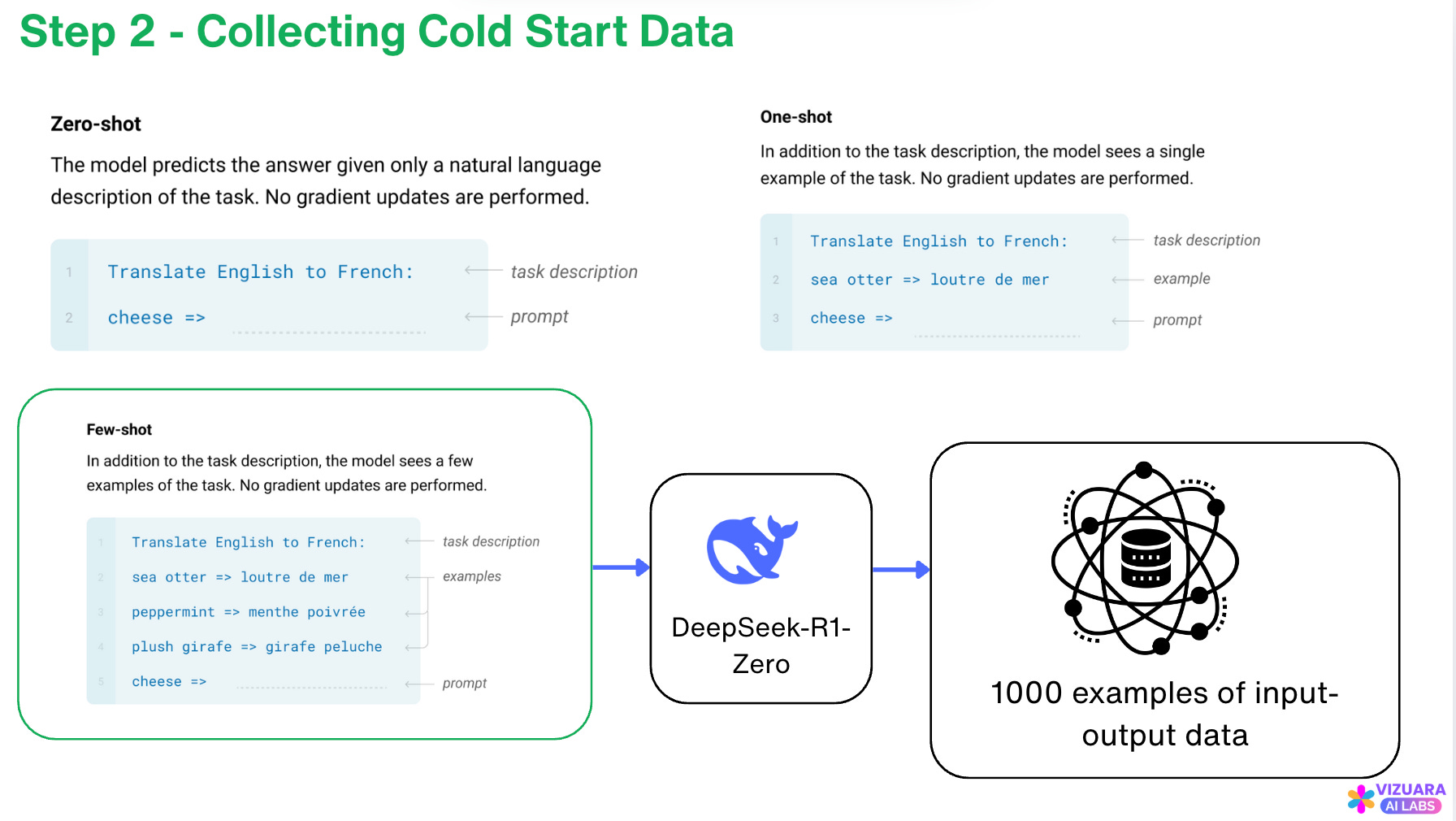
Step 2: Collecting Cold Start Data
In Step 2, the DeepSeek-R1-Zero model is used to collect pairs of input-output data.
For example, input can be something like:
If all crows are black and a bird is not black, can it be a crow?
And, the output can be:
No
This data is also called as “Cold Start Data”. This terminology probably comes from cold start in an engine, which means starting the engine when it's at or below ambient temperature, meaning it's colder than its normal operating temperature.
Step 3: Finetune Model using Cold Start Data
Just as we train a neural network with input-output pairs of labelled data, the base LLM in DeepSeek called “DeepSeek-V3” is trained using the cold start data collected in Step 2.
This process is also called as “Fine-tuning”.
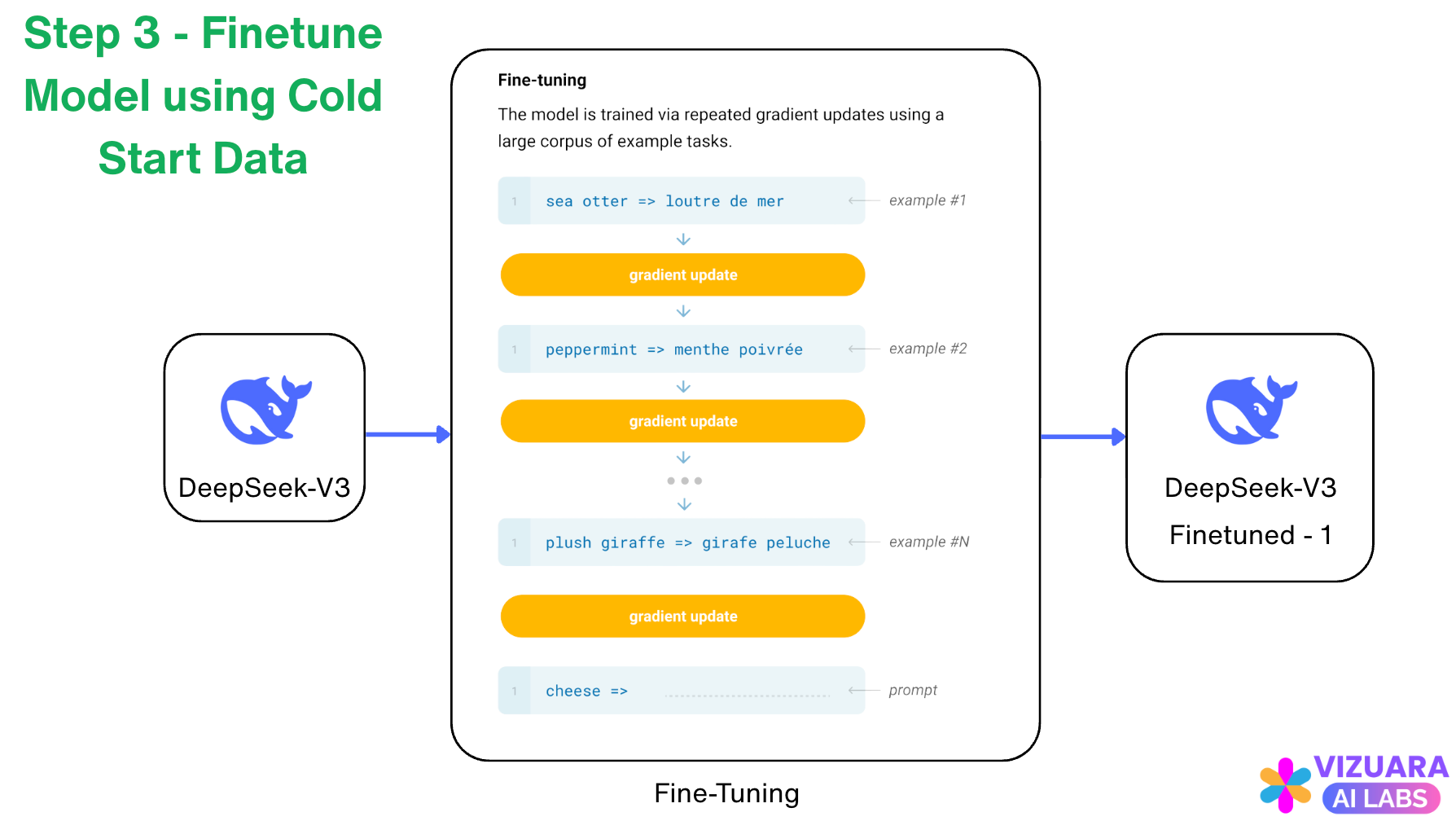
Here, we are teaching the LLM that, look, you are already trained using a lot of data. But, here is some more data which you need to learn from.
We do this because we want to improve the model with the help of the cold start data we have collected, before we start the Reinforcement Learning Phase again.
Step 4: Training using Reinforcement Learning
We do one more round of training the model using Reinforcement Learning, again using the GRPO model.
This time, we expect the model to do even better than DeepSeek-R1-Zero, because we have made the model better using the cold-start data before using RL.
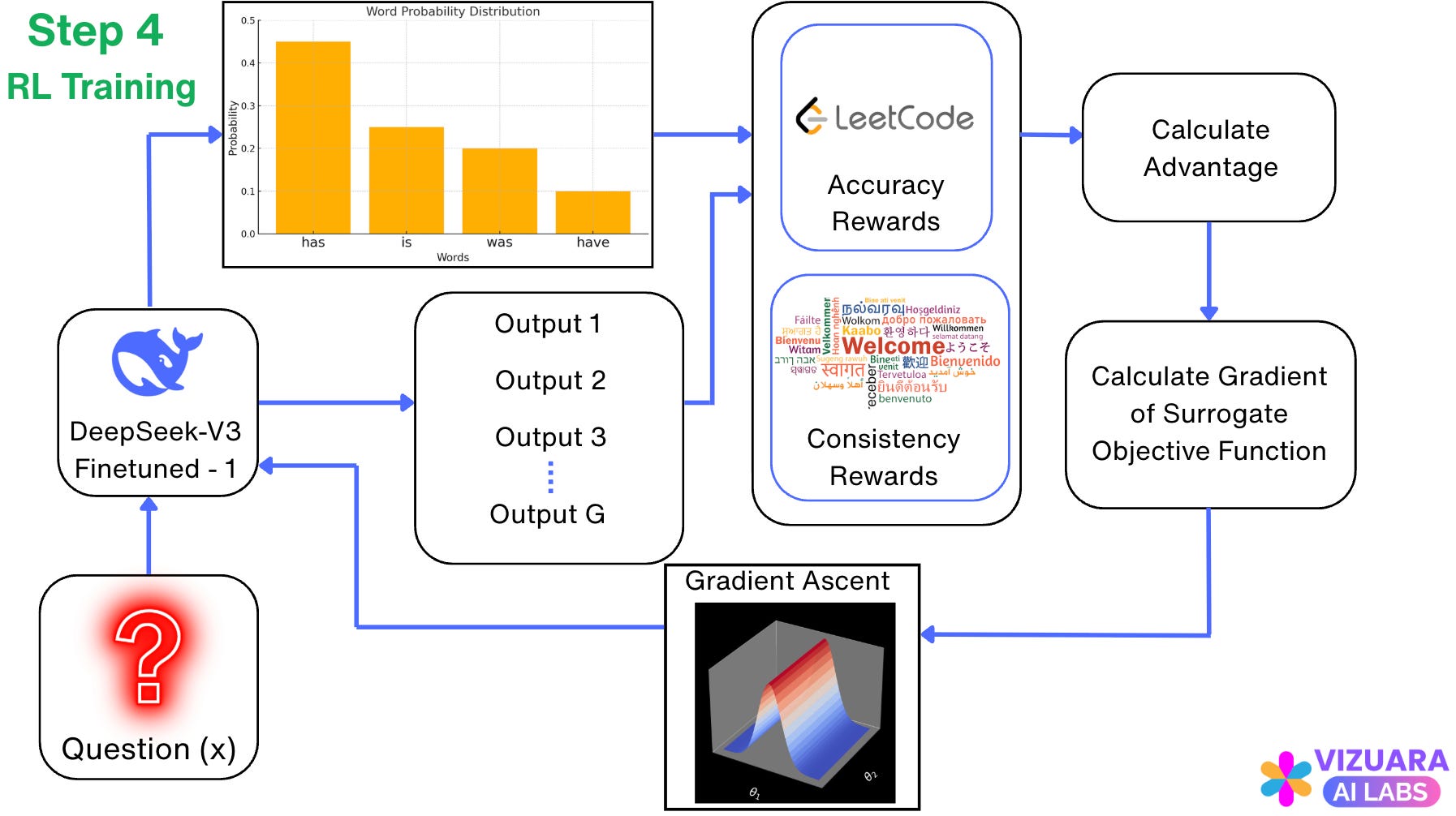
A careful reader will notice that, we have added a “consistency rewards” box here, which was not there for DeepSeek-R1-Zero. This is added to make sure that the model output does not contain a mixture of languages, but has a single language which the user has used/requested in the prompt.
Step 5: Collect Huge Amounts of Data - General Purpose Tasks
Now, we again take the role of a “data collector”. This time, we need more bags, because we want to collect a lot of data.
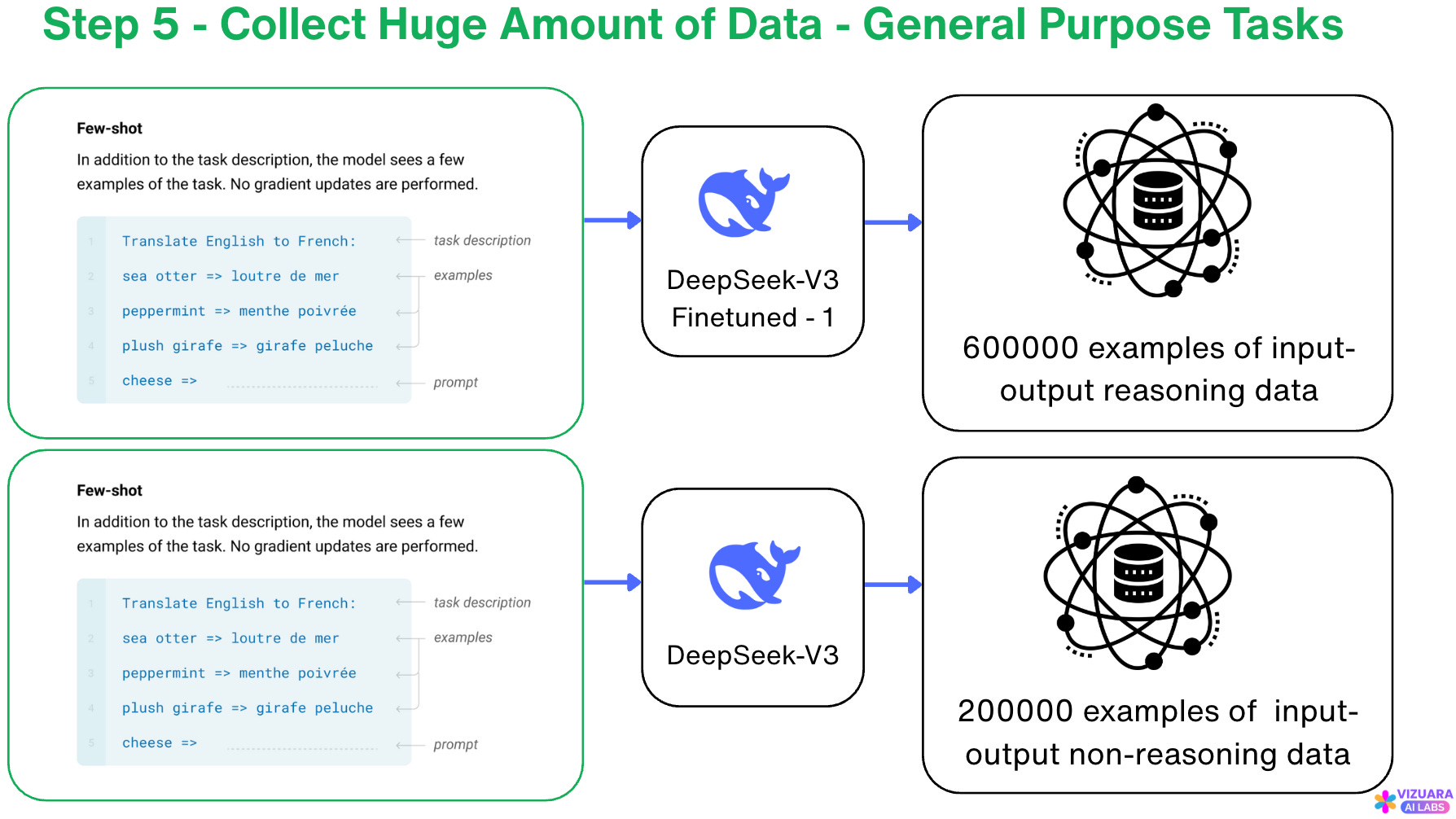
We use the trained model from Step 4 to collect 600000 examples of input-output reasoning data and 200000 examples of input-output non-reasoning data. This data contains a lot of rich information about general purpose questions, not just reasoning-based questions.
This is done to make sure that our model becomes a general expert, not just an expert at reasoning tasks.
You can probably predict the next steps..
Yes again fine-tuning, following by RL training.
Step 6: Finetune model using 800000 Data Samples
Now, we fine-tune our model from Step 4 using these 800000 data samples collected during the previous step.
We are again telling the LLM that, look, you are already smart, but why don’t you get even smarter on a wide range of tasks and become a general expert.
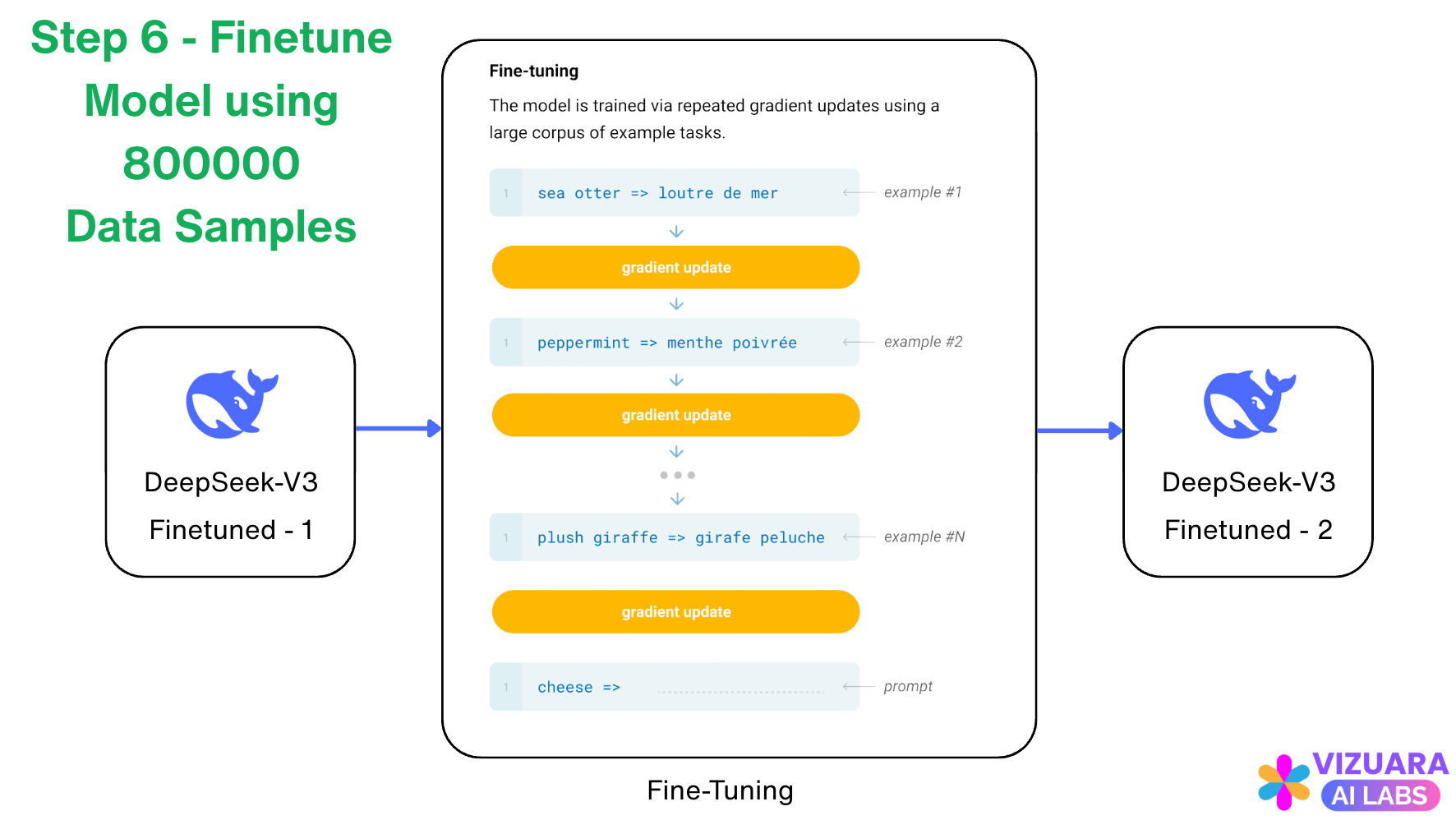
We following this up, by another round of RL Training.
Step 7: Training using Reinforcement Learning
We do one more round of training the model using Reinforcement Learning, again using the GRPO model.
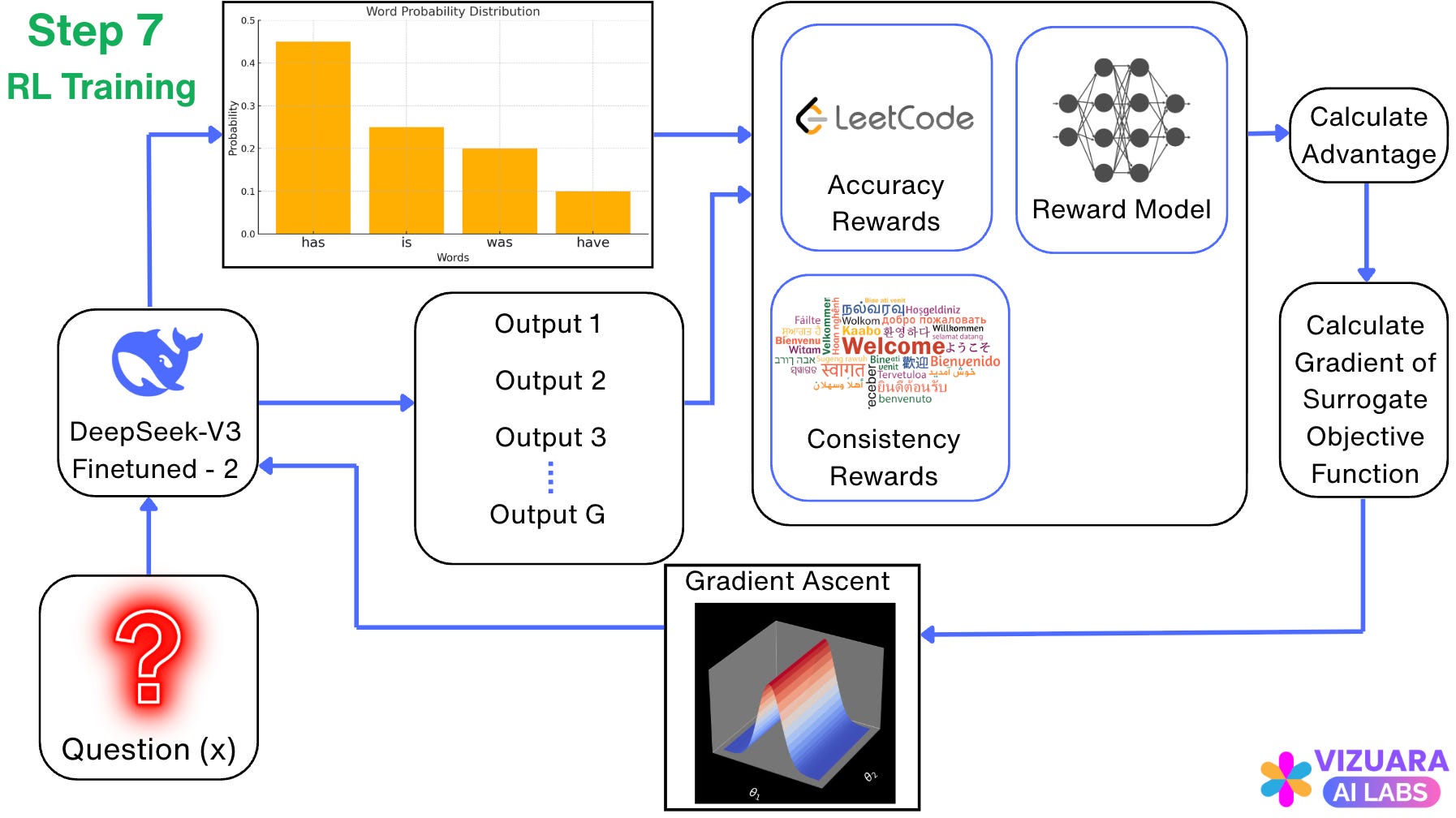

This might look like a lot of steps, but this recipe has become the universal norm for building large reasoning models.
So, in a way, we must be thankful to DeepSeek-R1 for telling us the secret recipe which the OpenAI o1-model had “most probably” used.
Wait, we are not done yet. There is a last ingredient remaining.
Ingredient #4: Distillation
You might have heard distillation the context of water purification..

What does it mean here?
In the context of reasoning LLMs, it means the following:
Let us say that, we have a small model which does not have reasoning capabilities.
So, how do I give reasoning capabilities to this model?
You might say that: Just switch your model to a larger model.
But, I want to run this model locally on my device which does not have the memory required for a large model like DeepSeek which has 671 Billion Parameters.
What if, we do something like this?
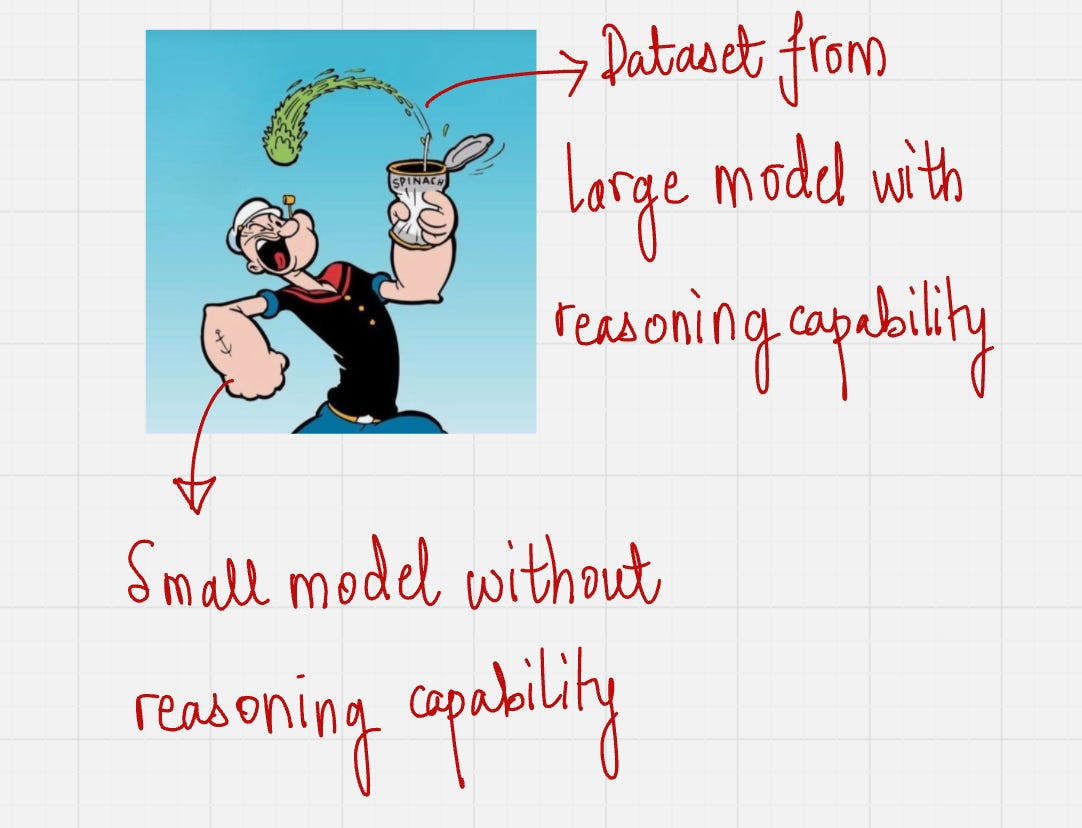
We use dataset from a larger model with reasoning capability and then use that data to finetune the smaller model.
DeepSeek did exactly this.
They first used the dataset of 800000 input-output pairs which we have collected in our second ingredient.
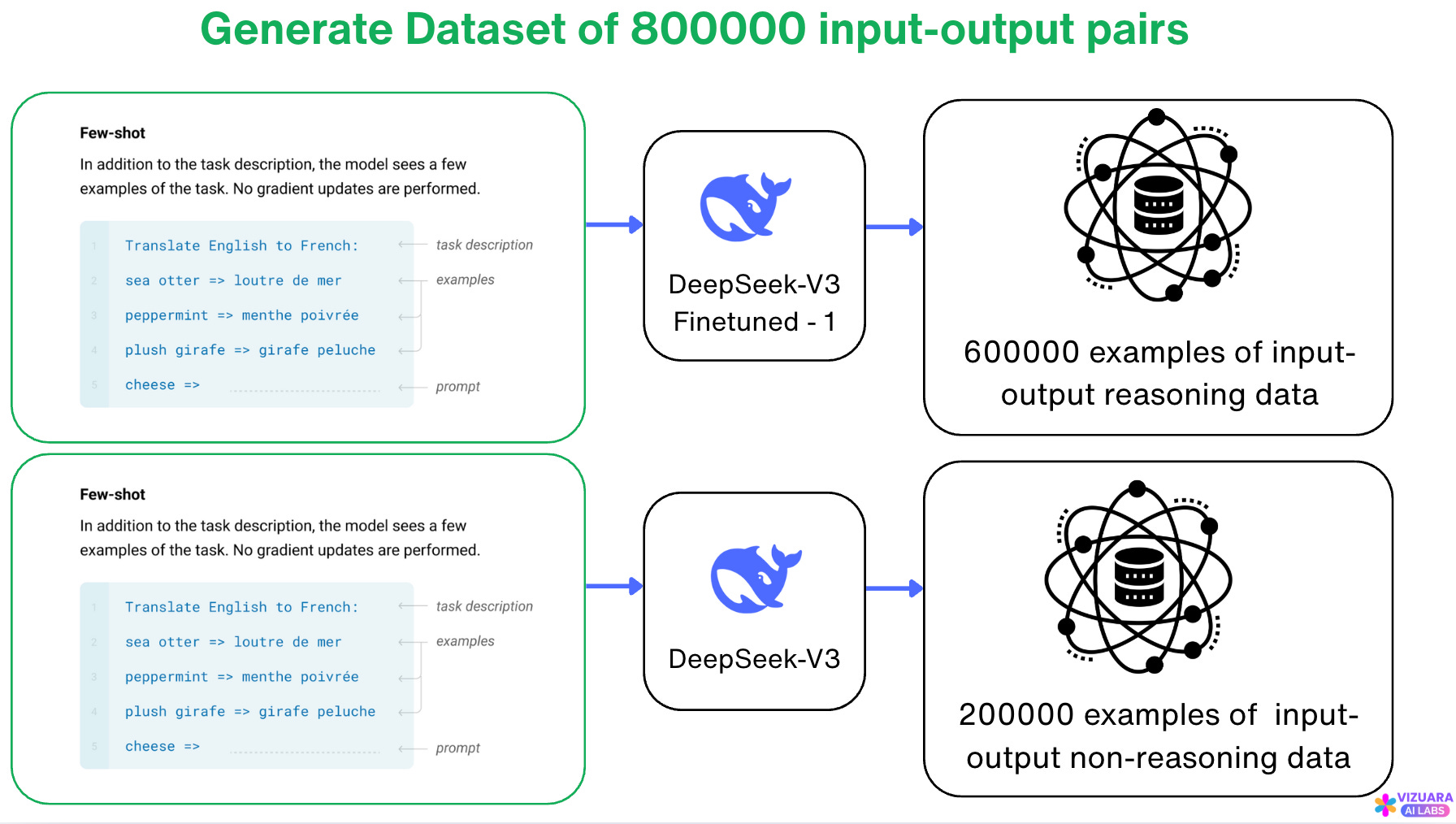
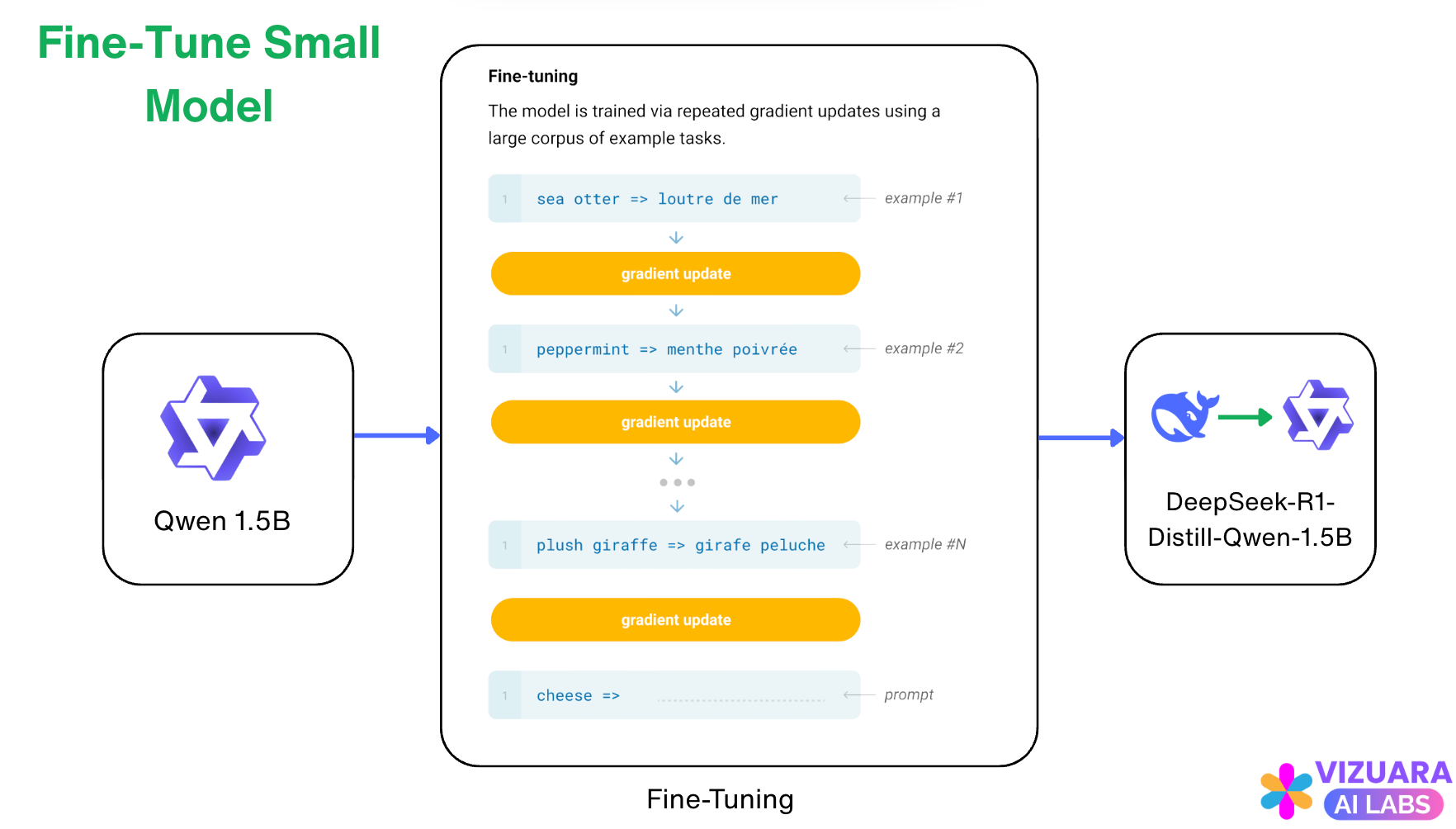
Then they finetuned a smaller model like Qwen 1.5B which did not have reasoning capabilities.
Here, notice that the smaller model has 1.5 Billion parameters which is ~ 450 times smaller than DeepSeek-R1 model.
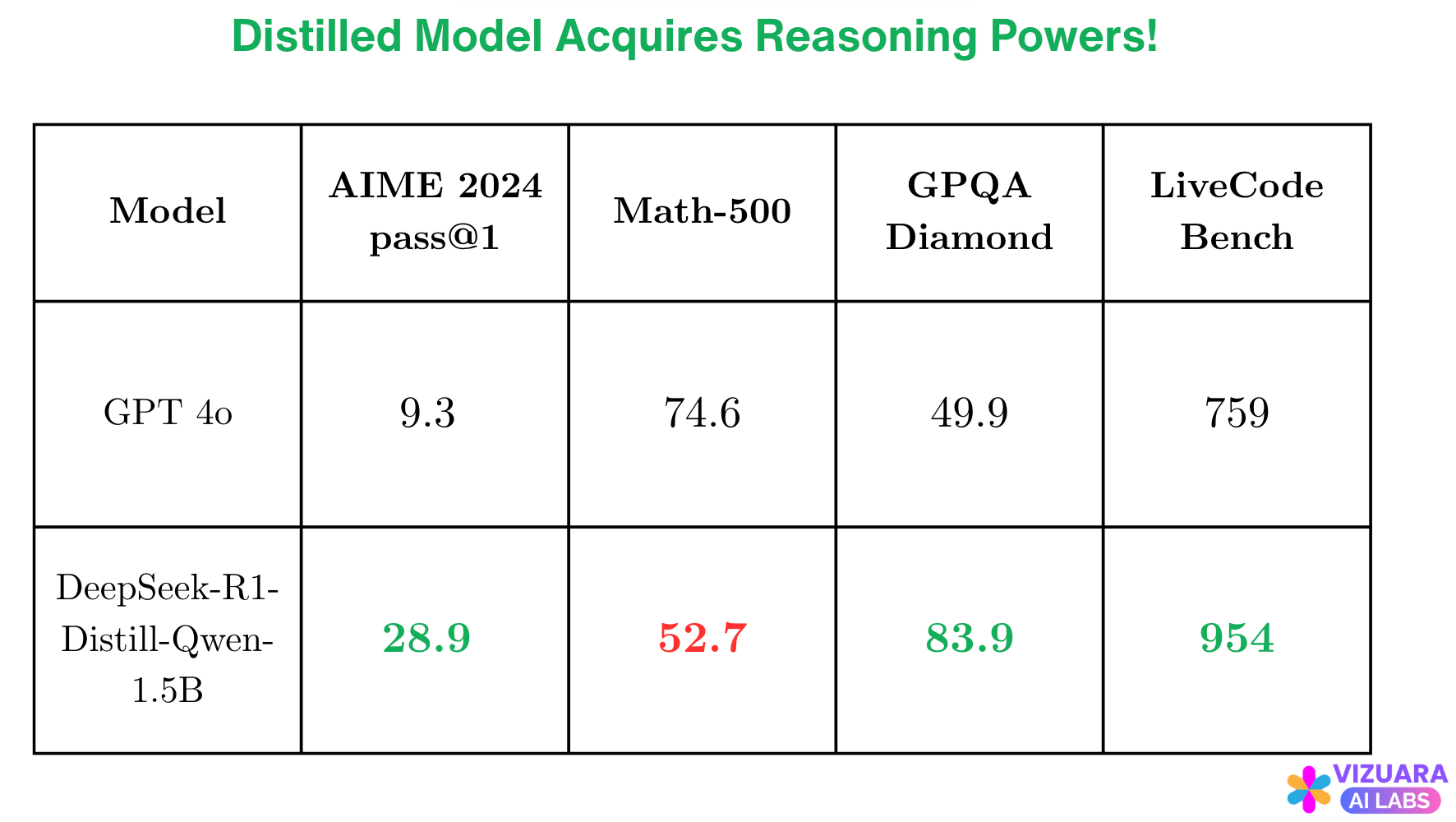
After this step, they found that the smaller model acquires reasoning powers!

Have a look at the benchmarks! The model which is 450 times smaller than DeepSeek performs better than GPT-4o on several benchmarks.
I personally feel that this method will be used in the future to make LLMs available on our personal devices like phones or laptops!
So, that is it! This is how Large Reasoning models are built!
I am sharing some relevant material below which will help you dive deeper into this subject:
Ingredient #1:
For Beginners: Lecture 1 - Lecture 3 of the course “Reasoning LLMs from Scratch”: Course Link
Language Models are Few-Shot Learners: https://arxiv.org/abs/2005.14165
Language Models are Zero-Shot Learners: https://arxiv.org/abs/2205.11916
Ingredient #2:
For Beginners: Lecture 4 - Lecture 21 of the course “Reasoning LLMs from Scratch”: Course Link
Deep Seek Math Paper (Introduced GRPO): https://arxiv.org/abs/2402.03300
Ingredient #3:
For Beginners: Lecture 4 - Lecture 22 of the course “Reasoning LLMs from Scratch”: Course Link
Deep Seek-R1 Paper: https://arxiv.org/abs/2501.12948
Ingredient #4:
For Beginners: Lecture 22 of the course “Reasoning LLMs from Scratch”: Course Link
Deep Seek-R1 Paper: https://arxiv.org/abs/2501.12948
How does it get the aha moment? Is that because of GRPO ?